
1. 앙상블(Ensemble)
- 분석 결과의 성능을 향상하기 위해 다수의 모델을 결합하여 하나의 최종 결과를 도출하는 방법
✅ 왜 모델들을 결합하는가?
- 과적합 발생으로 정확도가 부족한 단점을 보완하기 위해 사용
✅ 최종 결과는 어떻게 내는가?
- 회귀분석의 경우, 평균과 같은 대푯값을 산출해 최종 결과 종합
- 분류분석의 경우, 다수결과 가중 다수결 방식 등을 활용해 최종 결과 도출
✅ 종류
투표, 배깅, 부스팅, 랜덤 포레스트
2. 투표 (Majority voting)
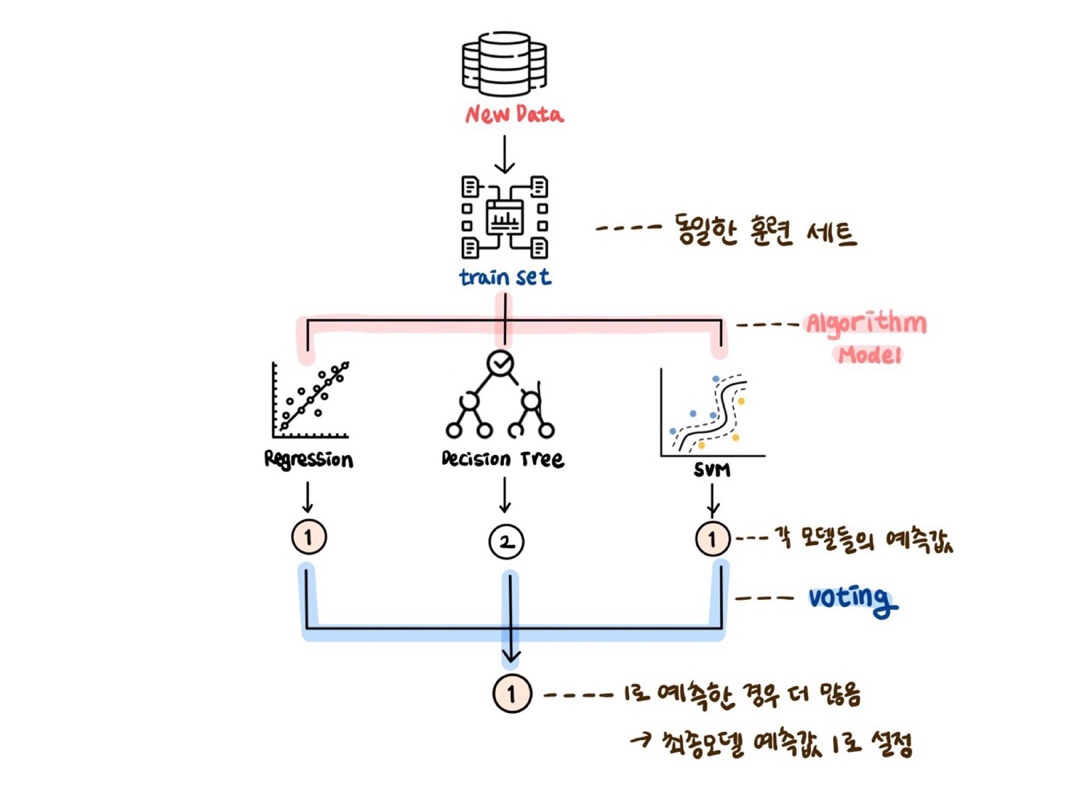
하나의 훈련세트에 훈련되지 않은 새 데이터를 대입하고 각 모델들의 예측값을 출력하여 예측된 횟수가 가장 많은 분류 결과로 최종 모델을 도출하는 기법이다.
3 배깅 (Bagging)
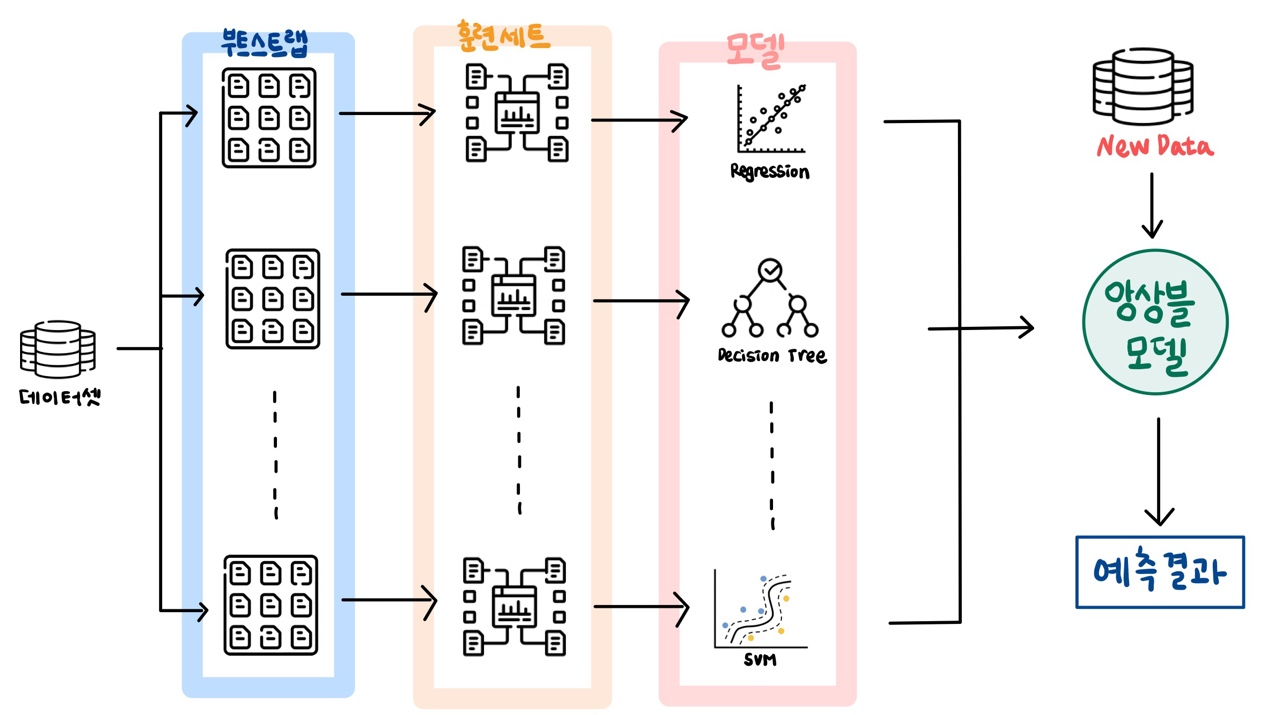
3.1 정의
- 하나의 데이터셋을 가지고 여러 개의 훈련세트를 만들고, 각 훈련 세트로 모델을 만든다.
3.2 부트스트랩 샘플링 (Bootstrap aggregating)
랜덤 복원 추출을 통해 같은 크기의 표본을 추출하는 샘플링 기법
3.3 특징
- 성능 향상에 효과적
- 데이터의 사이즈가 작거나 결측값이 있는 경우 유리함
- 여러 개의 표본에서 각각 모형을 병렬적으로 학습
4. 랜덤포레스트 (Random Forest)
4.1 정의
- 의사결정나무 기반의 앙상블 알고리즘으로, 배깅의 하위 개념
- 여러 개의 의사결정나무 모델을 만든 뒤, 각 모델에서 최적의 가지들을 추출해 하나의 새로운 나무를 만드는 기법
- 기본 배깅에 특징 배깅 과정을 추가한 방법
4.2 의사결정나무가 모이다?
Forest = Tree로 이루어져있다 !
숲은 나무로 이루어져 있듯이,
랜덤포레스트는 수많은 의사결정나무가 모여서 생성된다.
의사결정나무로 어느 집단의 건강 위험도를 결정한다고 생각하자.
성별, 나이, 흡연여부 이 3가지 feature로는 위험도를 예측하기 쉽지 않다. 따라서 운동량, 키, 몸무게 등과 같이 3가지보다 더 많은 요소를 고려하여 건강 위험도를 판단하는 것이 바람직하다.
하지만, 이렇게 많은 feature들을 기반으로 1개의 의사결정나무를 만든다면 트리 가지는 많아질 것이고 깊이도 깊어져 과적합이 일어날 수 있다.
따라서, 랜덤 포레스트는 전체 feature 중 랜덤으로 일부 feature를 무작위 선택해 하나의 결정 트리를 만들고 그 과정을 반복하여 여러 개의 결정 트리를 만들어 간다.
하나의 거대한 결정트리를 만드는 것이 아니라 여러 개의 작은 결정 트리를 만든다!
4.3 최종 예측값은 어떻게 내는가?
여러 개의 결정 트리에서 내놓는 예측값은 다 다르다.
따라서 랜덤 포레스트의 최종 예측값은 다수결의 원칙으로 결정 트리에서 내놓은 예측 값들 중 가장 많이 나온 값으로 결정한다.
분류일 경우는 가장 많이 등장한 값
회귀일 경우는 평균값
4.4 왜 랜덤으로 feature을 고르는가?
랜덤 포레스트의 목적은 모든 요소를 고려하여 최종 예측값을 내는 것이다. 중요한 요소이든 덜 중요한 요소이든 모두 고려하려하는 목적이다.
따라서 결정 트리의 한 단계를 만들 때 모든 요소를 고려하는 것 보다는, 랜덤으로 몇 개의 feature를 골라 결정 트리 여러 개 만들어가는 방법이 오버피팅 되는 단점을 해결한다.
4.4.1 특징 배깅(Feature bagging)
-
개별 나무를 분리할 변수를 랜덤으로 선택하는 기법
-
변수를 한 번만 랜덤하게 선택한 후 그 변수들을 가지고 분리를 하는 것이 아니라, 각각 분리할 때마다 분리기준과 변수를 랜덤 선택하는 것이다.
-
동일한 트리 생성 방지 = 개별 나무들끼리 같아질 가능성이 거의 없어진다!
▶ 개별 나무들의 상관성을 줄여 일반화 오류가 작아져 예측력 향상
▶ 변수가 많은 경우, 별도의 변수 제거 없이 분석 가능
4.5 특징
- 분류와 회귀 문제 모두 사용 가능
- 의사결정나무의 편향(bias)는 유지하고 분산(variance)는 감소 (배깅의 장점을 이어받음)
▶ 예측 편향 감소 ▶ 예측력 증가 - 이상치에 민감하지 않으며 결측치를 다루기 쉽다.
- 유연하지 못하다. 즉, 나무 외에 다른 예측 모형 적용하기 힘들다
4.6 분류 분석 실습
5. 부스팅 (Boosting)
5.1 정의
- 예측력 약한 모형을 모아 예측력 강한 모형을 만드는 앙상블 기법
- 순차적으로 학습하며 데이터의 가중치(중요도)를 재조정
▶ 오차가 적어지도록 하기 위함
▶ 잘못 분류한 데이터는 높은 가중치, 잘 분류한 데이터는 낮은 가중치 부여
5.2 특징
- 높은 정확도
- 과적합 가능성 높음
- 이상치에 취약
▶ 배깅의 '랜덤포레스트' 와 반대
가중치를 조정하는 방법에 따라 알고리즘 구분
5.3 AdaBoost (Adaptive boosting)

- 약한 모형을 하나씩 순차적으로 학습하는 부스팅 기법으로, 학습한 모형이 잘못 분류한 표본에 높은 가중치를 부여하고 다음 모형은 높은 가중치가 부여된 표본을 잘 분류할 수 있도록 학습된다. 각각의 결과를 종합하여 강한 모형을 생성한다.
5.4 GBM (Gradient boosting machine)
-
Adaboost와 유사하지만 가중치 조정 시 경사하강버을 이용하는 부스팅 기법으로, 경사하강법은 잔차 즉 오류를 최소화하는 방향으로 가중치를 재조정한다.
-
대표적인 탐욕 알고리즘 (Greedy Algorithm)으로, 문제를 해결하는 과정에서 매순간 가능한 모든 선택지 중에 최선의 답을 선택한다.
▶ 과적합 될 확률이 높고 학습 시간이 길다는 단점
(1) Level - wise

-
균형 트리 분할 방식
-
최대한 균형 잡힌 트리를 유지하면서 분할하고 이에 따라 깊이 최소화
-
ex) GBM, XGBoost
(2) Leaf - wise

-
최대 손실을 갖는 리프 노드를 지속 분할하여 깊고 비대칭적인 트리 생성
-
ex) Light BGM
