[논문리뷰] Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection , CVPR 2020
인공지능
code : https://github.com/sfzhang15/ATSS
Intro
Object Detection 에서 사용되는 모델은 크게 YOLO, SSD 같은 1-stage 모델과 Faster-RCNN과 같은 2-stage 모델로 나누어집니다.
둘의 차이는 box를 detection 하는 과정에서 region proposal network (RPN) 을 사용하지 않는지(1 stage), 사용하는지(2 stage) 여부입니다.
Object Detection 분야의 모델을 나누는 또 다른 기준은 anchor의 사용 여부입니다.
anchor란 특정 aspect ratio를 가진 object를 탐지하기 위해 다양한 크기와 비율로 "미리 정의해놓은" bounding box를 의미합니다.
anchor를 사용하는 대표적인 모델은 YOLO v1입니다. 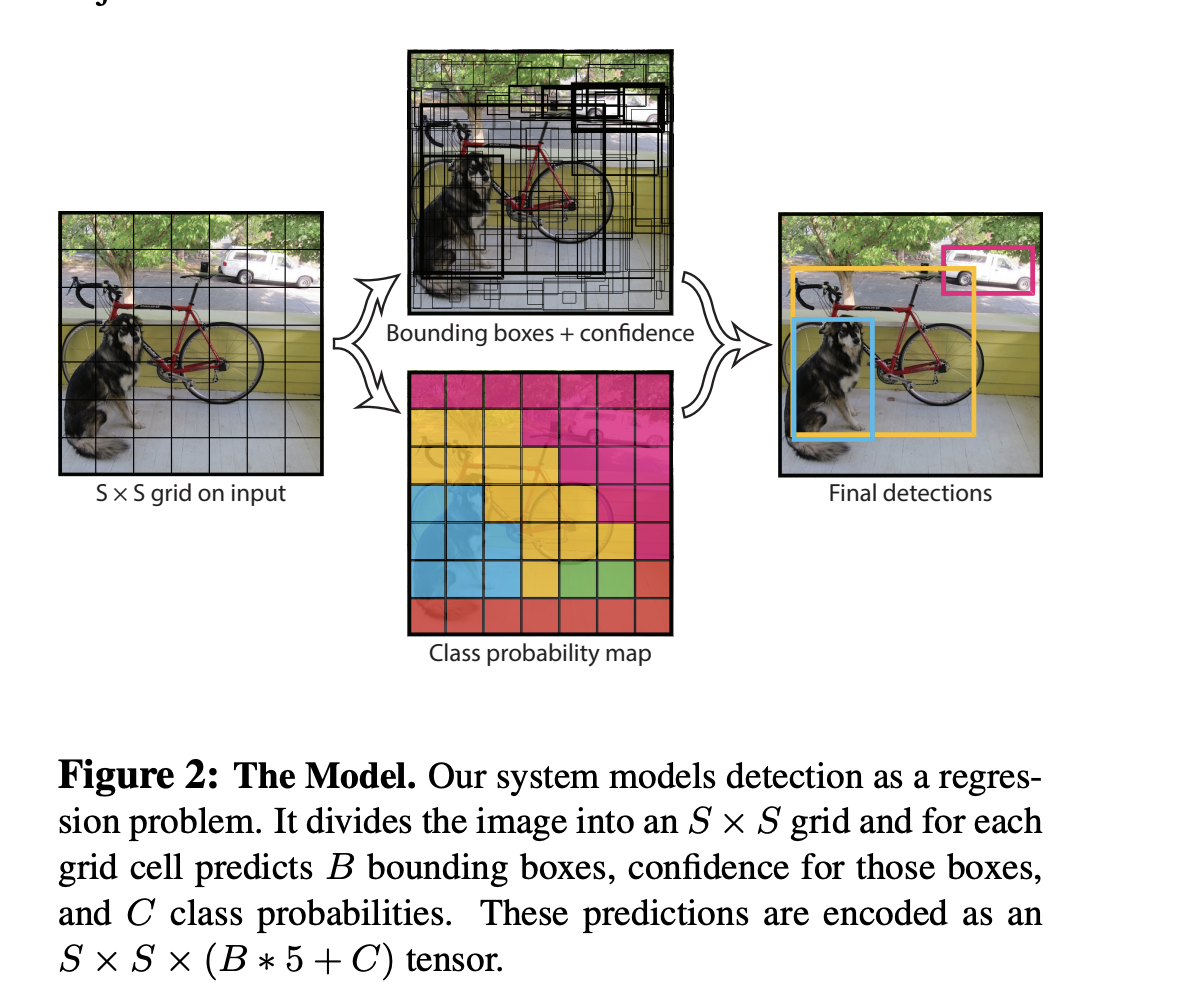
객체의 크기, 비율 등 객체의 특징에 해당하는 B개의 anchor box를 사람이 디자인합니다.
이미지 전체를 SxS grid로 나누고, 각 grid에서 디자인한 B개의 anchor box에 해당하는 feature를 뽑아 network에 input으로 넣어주는 방식입니다.
이를 여러 개의 anchor를 tiling한다고도 하는데,
각기 다른 가로, 세로, 비율을 가진 anchor box들을 이미지의 각 위치마다 anchor box를 놓는 것을 의미합니다.
이후 모델이 각 anchor box 마다 객체일 확률, 배경일 확률, 위치 (class probability, bounding box offsets)등 을 예측하고 각 anchor box의 모양과 위치를 세부적으로 조절합니다.
anchor-based detection 의 한계
이렇게 hand-crafted anchor를 사용하면 학습 데이터에 있어서는 높은 정확도를 보이는 장점이 있지만 명확한 단점 또한 존재합니다.
-
anchor box 디자인
학습 데이터 안에 포함된 객체의 특징을 파악하여 사람이 직접 box를 디자인하기 때문에 데이터가 바뀔때마다 매번 box를 설계해야합니다. -
높은 computation cost
다양한 크기와 비율을 가진 객체를 탐지하기 위해 보통 2개 이상의 anchor를 사용하는데, 그에 따라 각 anchor에서 만들어내는 feature가 많아져서 computation cost가 커지게됩니다. -
낮은 inductive bias
학습데이터 안에 포함되지 않은 특징을 가진 새로운 데이터를 예측할 때, 해당 데이터는 미리 설계한 anchor box로는 예측 성능이 매우 떨어지게 됩니다.
위와 같은 한계점으로 인해 anchor box를 사용하지 않는 모델을 연구하게 됩니다.
anchor-free detection
anchor를 사용하지 않는다면 어떻게 객체를 detection 할 수 있을까요?
anchor free 모델은 미리 정의한 anchor 없이 바로 object를 탐지하는데,
Keypoint-based method 와 Center-based method 의 두가지 방법이 있습니다.
-
Keypoint-based method
먼저 여러 개의 미리 정의되거나 자체 학습된 Keypoint를 찾은 다음 객체의 공간 범위를 제한하는 방법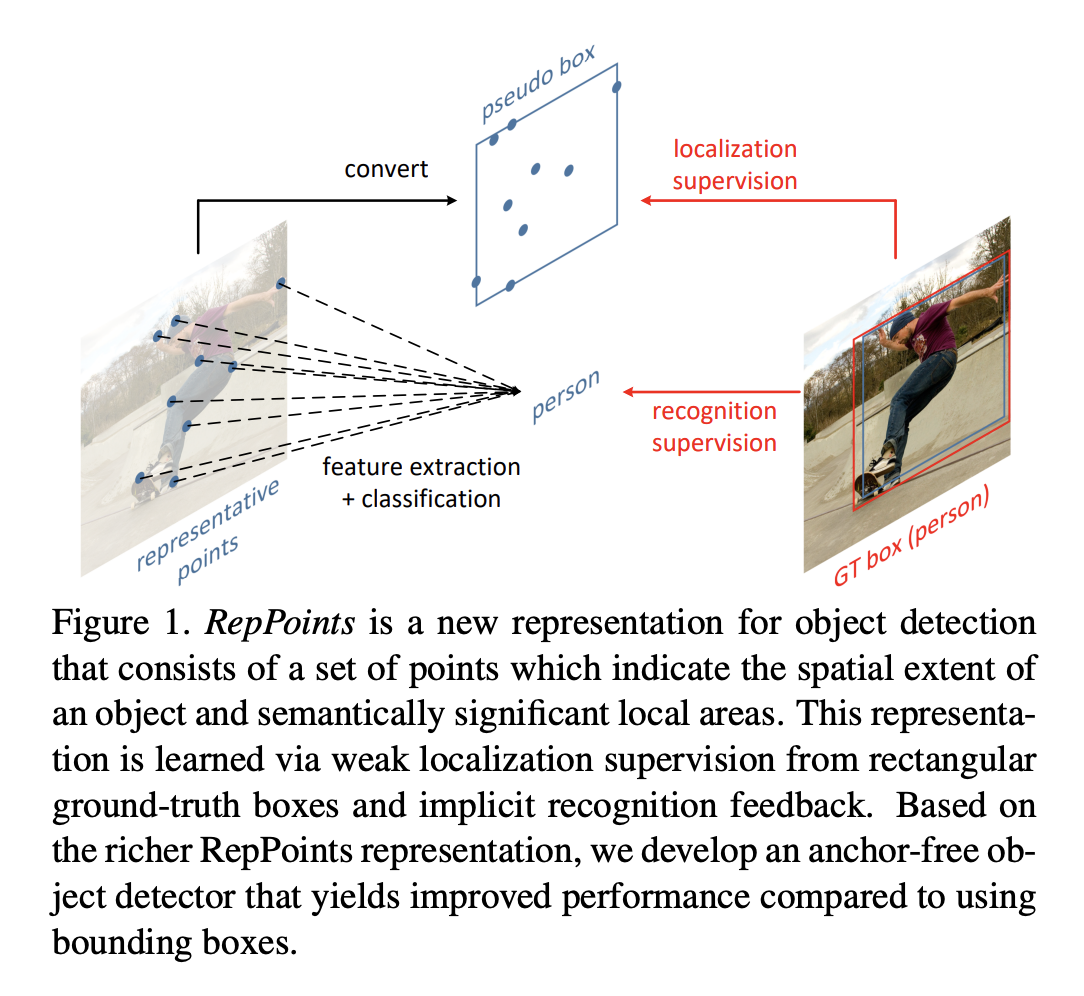
[RepPoints, CVPR 2019]
-
Center-based method
객체의 중심점 또는 영역을 사용하여 양의 값을 정의한 다음 양의 값에서 객체 경계까지의 네 가지 거리를 예측하는 방법
[FCOS, ICCV 2019]
[이 논문이 연구된 이유/배경]
그동안은 detection 분야에서 Anchor-base 모델을 사용하는 것이 높은 정확도를 보장하기 때문에 정답처럼 여겨졌지만, FPN과 FOCAL loss 의 등장으로 Anchor-Free 모델의 연구도 활발하게 진행됩니다.오늘 리뷰할 논문인 Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection (이하 ATSS) 은 Anchor-based 방법론과 Anchor-free 방법론의 성능 차이를 야기하는 핵심 원인이 무엇인지 찾고, 찾은 원인을 기반으로 성능 차이를 줄이는 방법(ATSS)을 제안합니다.
Background
-
FPN
Feature Pyramid Network. 보다 다양한 크기의 객체를 탐지하기 위해 network의 마지막 layer에서 나온 feature만 사용하는 것이 아니라, 각 layer에서 나온 모든 feature를 사용합니다.
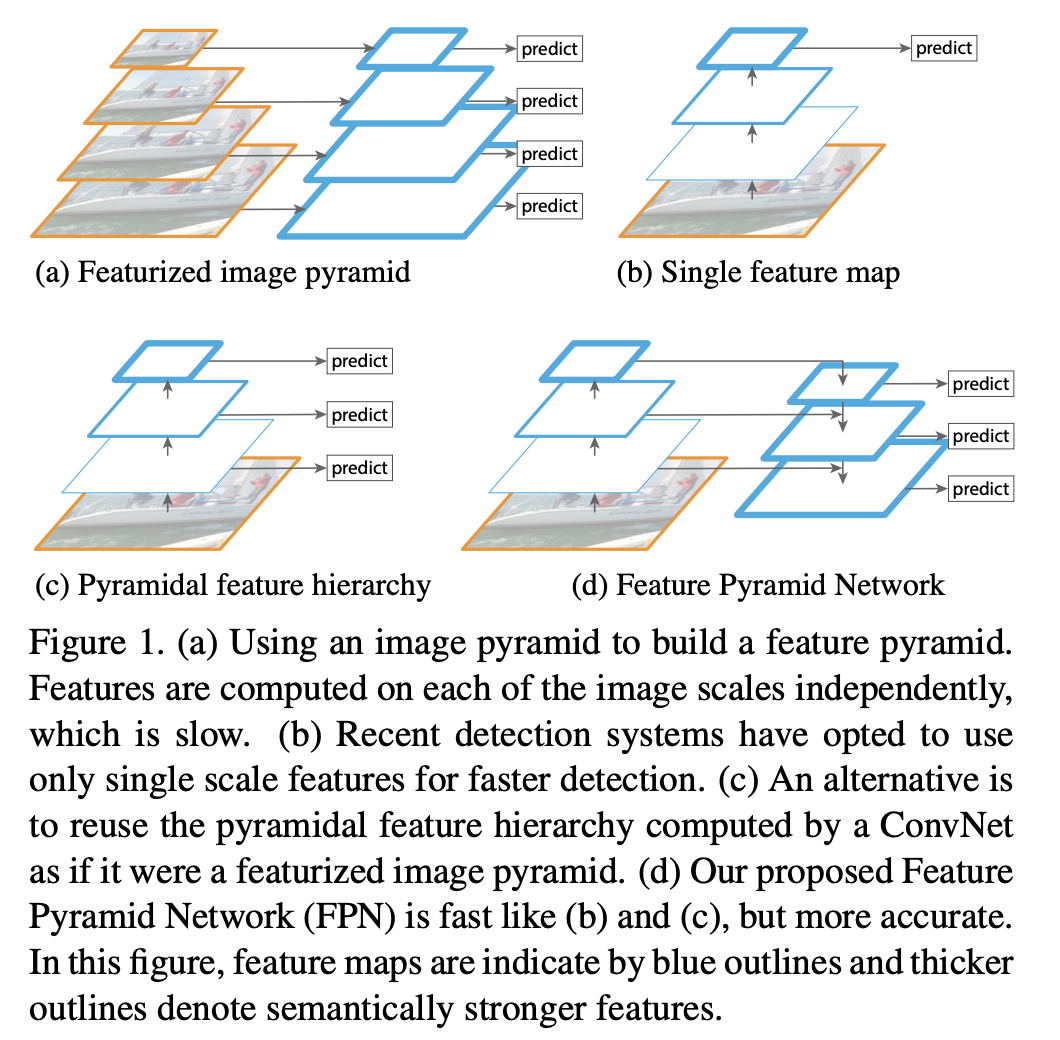
-
FOCAL loss
1 stage detector의 경우 RoI pooling 과정이 없어 class imbalance 문제가 심각합니다. 이미지 안에서 object가 차지하는 영역은 적고 배경이 차지하는 영역이 크다면 negative anchor box의 갯수가 positive anchor box의 갯수보다 훨씬 많아져 학습에 방해가 됩니다. 배경은 객체에 비해 쉽게 구분되기 때문에 학습에 중요한 부분이 아닌데, 차지하는 비율이 커서 loss, gradient를 계산할 때 배경의 영향이 커지게 됩니다.이를 해결하기 위해 분류하기 어려운 케이스(여기서는 객체)일 때 loss 계산 시 더 큰 가중치를 주고, 쉽게 분류할 수 있는 경우(배경)는 작은 가중치를 주는 방법입니다.
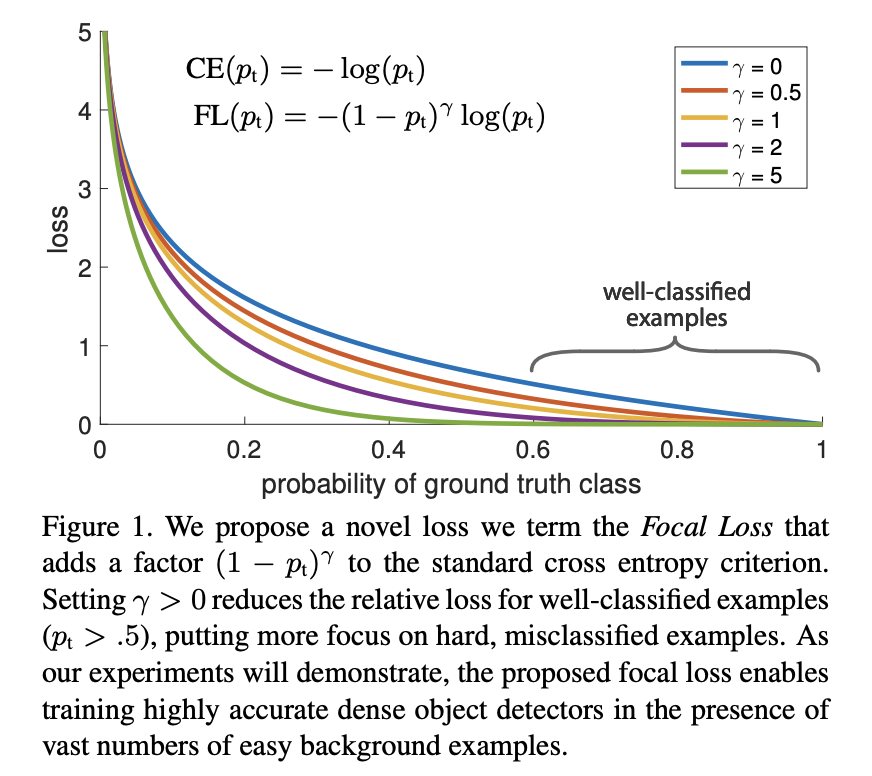
-
왜 FPN, Focal loss의 등장으로 anchor free 모델의 연구가 활발히 진행되는지
FPN과 Focal loss의 장점은 다양한 feature를 사용하고, RPN을 사용하지 않는 방법론에서 객체 탐지의 정확도를 높여주는 기법이므로 anchor가 사라져서 오는 정확도의 하락을 해당 기법들로 보완하였습니다. -
FCOS
Anchor-free , Center-based method 에 속하는 모델입니다.
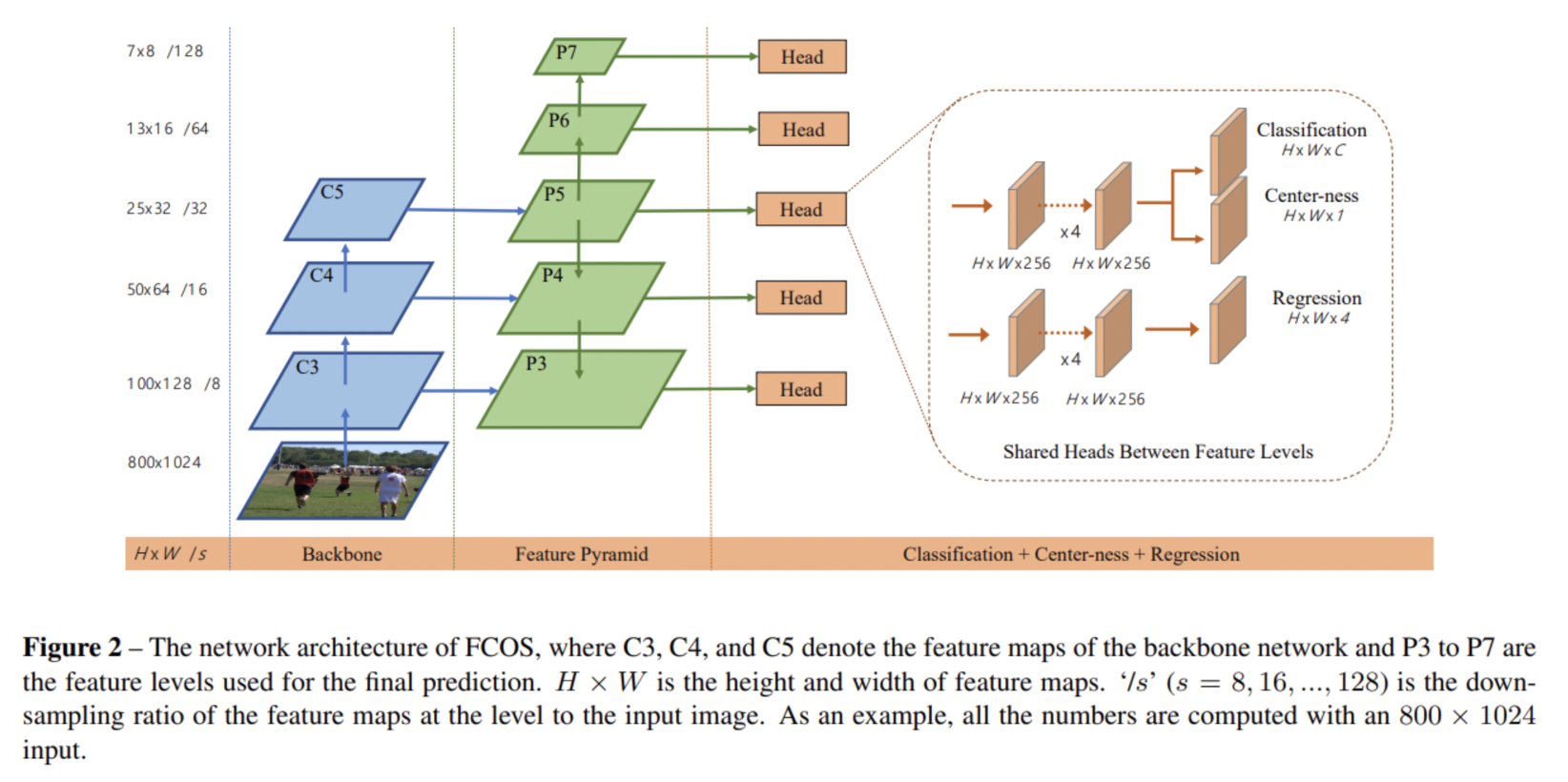
CNN으로만 구성된 네트워크입니다.
feature map의 모든 픽셀마다 GT 박스 안에 포함되면 해당 물체로 classification합니다.
해당 위치로부터 bonding box 경계까지의 거리를 regression 합니다.
주요 특징은 다음과 같습니다.- FPN : 겹친 물체 detection
- Center-ness branch : 중심으로 부터 거리가 가까운 Prediction 만을 사용
Abstract
해당 논문에서는 Anchor-based와 Anchor-free 방법론간의 성능 차이를 야기하는 핵심적인 차이가
positive, negative sample을 어떻게 정의하는지에 따라 달렸다는 것을 보여줍니다.
즉 학습을 하며 positive, negative sample 의 정의를 똑같이 하면
box or point regression 을 어떻게 하느냐와는 상관없이 최종적인 detection 성능에서도 차이가 적다는 것입니다.
이는 근래의 detector 들 성능에는 positive and negative training samples을 어떻게 select 하느냐가 핵심임을 뜻합니다.
따라서 이 논문에서는 Adaptive Training Sample Selection (ATSS) 를 제안합니다.
ATSS 는 객체의 통계적 특징에 따라 positive, negative sample을 자동으로 결정하게 하는 기법입니다.
Contribution
- Anchor-Based 와 Anchor-Free detector 의 핵심 차이는 positive and negative training samples을 어떻게 정의하는지 임을 밝힘
- Adaptive Training Sample Selection (ATSS) 를 제안
- ATSS 를 통해 50.7 AP 로 SOTA 달성
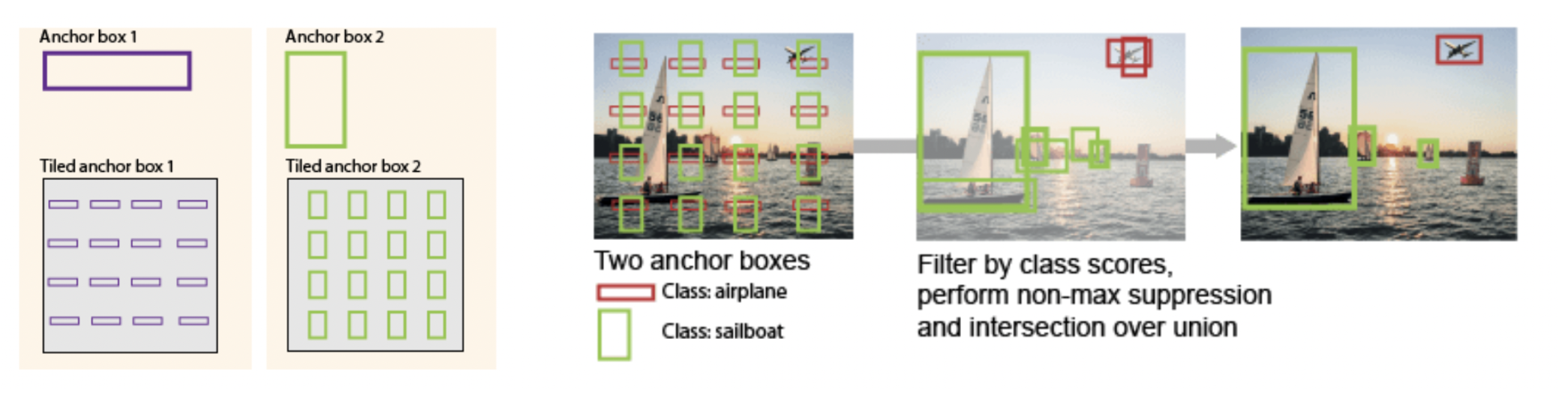
- Obejct detection를 위해 이미지의 위치별로 여러 anchor를 tiling 할 필요성에 대한 실험 진행 (그럴 필요 없다고 말함)
anchor를 tiling?
여러개의 anchor를 tiling한다.
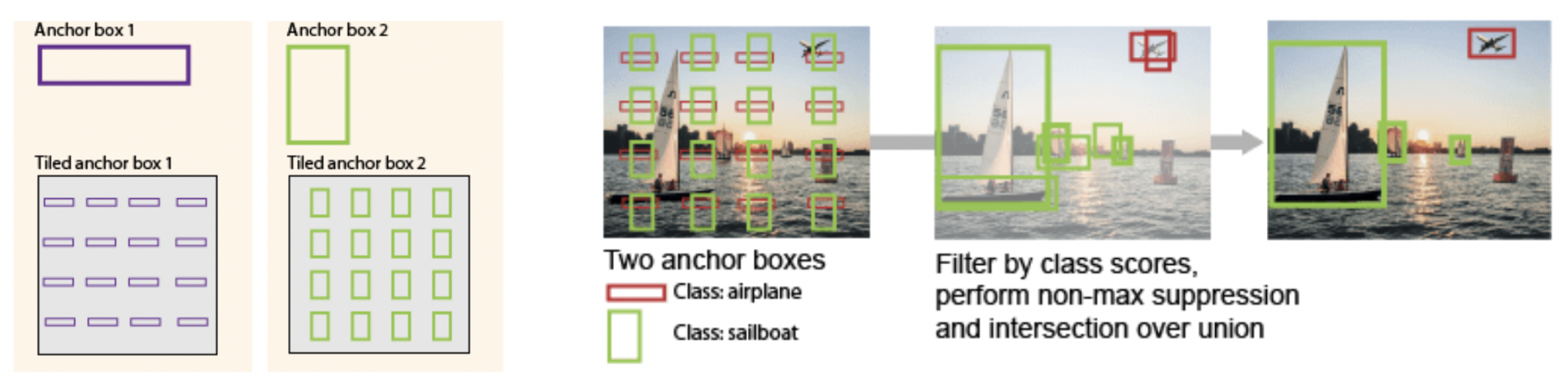
특정 aspect ratio를 가진 object를 탐지하기 위해 우리는 미리 가로, 세로, 비율이 정의된 bounding box를 가지고 있고, 이를 anchor box라고 한다.
각기 다른 가로, 세로, 비율을 가진 anchor box들을 이미지의 각 위치마다 anchor box를 놓는 것을 의미한다.
이후 모델이 각 anchor box 마다 객체일 확률, 배경일 확률, 위치 등을 예측하고 각 anchor box의 모양과 위치를 세부적으로 조절해나간다.
Experiment
Anchor-Based detector로는 RetinaNet, center-based Anchor-Free detector로는 FCOS를 가지고 실험을 진행합니다.
두 모델을 선택한 이유는 FCOS 논문에서 anchor based인 RetinaNet 보다 좋은 성능을 냈는데,
아래 세가지의 차이 중 어떤것이 더 좋은 성능을 내도록 했는지 분석해보고자 두 모델을 선택했습니다.
| Differenece | RetinaNet | FCOS |
|---|---|---|
| (1) The number of anchors tiled per location | tiles several anchor boxes per location | tiles one anchor point per location |
| (2) The definition of positive and negative samples | resorts to the Intersection over Union (IoU) for positives and negatives | utilizes spatial and scale constraints to select samples |
| (3) The regression starting status | regresses the object bounding box from the preset anchor box | locates the object from the anchor point. (anchor point = center of an anchor box in RetinaNet) |
Exp1 - Inconsistency Removal
이 실험은 위의 3가지 차이 중 (1) The number of anchors tiled per location를 분석한 실험입니다. 몇 개의 anchor box를 사용하느냐가 두 기법의 핵심 차이라면 기존에 두개 이상의 anchor를 사용하는 RetinaNet은 anchor box의 갯수를 FCOS와 동일하게 했을 때
두 기법의 성능차이가 작아야 할 것입니다.
FCOS 논문에서 FCOS가 RetinaNet보다 더 나은 성능을 보입니다.
그 이유를 분석하기 위해 FCOS에 적용한 기법을 RetinaNet에도 적용해봅니다.
RetinaNet은 FCOS에서 Anchor Points를 하나만 사용하는 것처럼 anchor box 하나만 사용합니다.
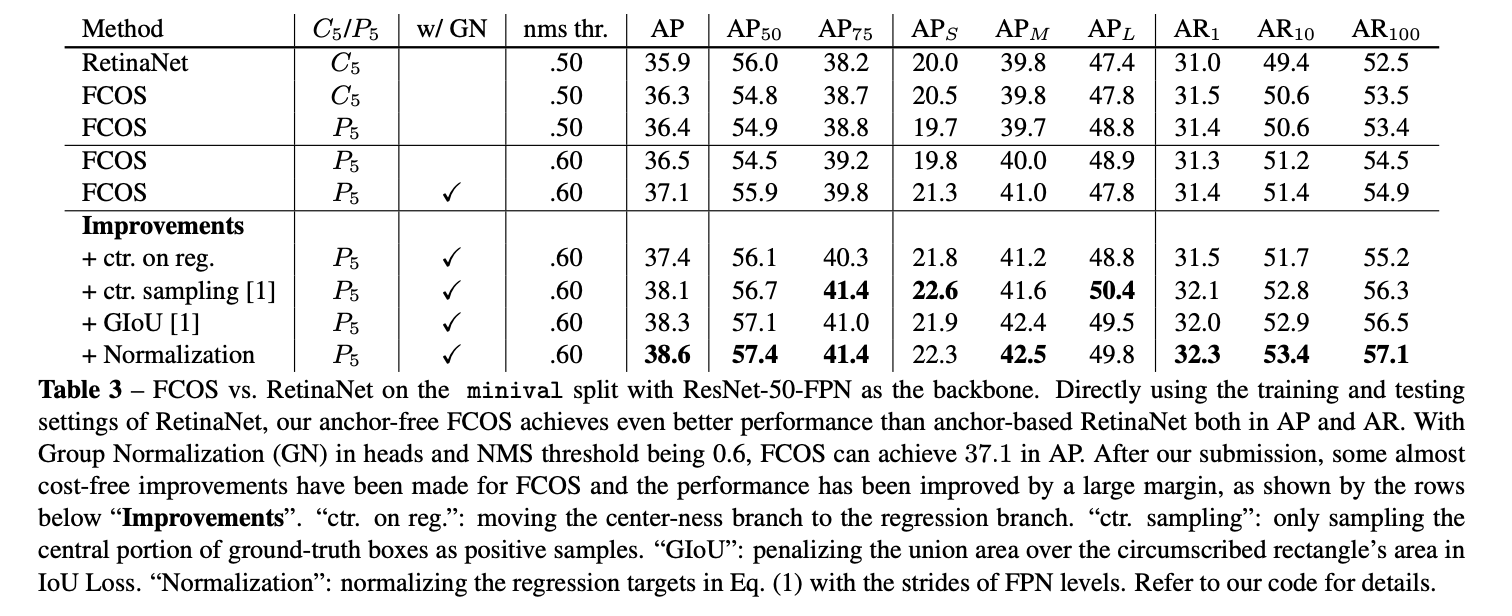
위의 테이블은 FCOS 논문에서 가져온 것인데, FCOS 와 RetinaNet의 minival AP_large 가 47.4% vs. 48.9%로 FCOS가 더 높습니다.
-
GroupNormalization
-
GIOU regression loss function
-
Limiting positive samples in the ground-truth box : GT Box안 쪽에 속하는 sample들만 positive sample candidate로 보는 것
-
Centerness branch : foreground를 검출할때 foreground라고 예측한 지점이 실제 ground truth 박스 기준으로 얼마나 center에 가깝냐를 예측하는 기법
-
Adding a trainable scalar for each level feature pyramid : 객체의 크기를 예측할때 learnable한 scalar 값을 이용
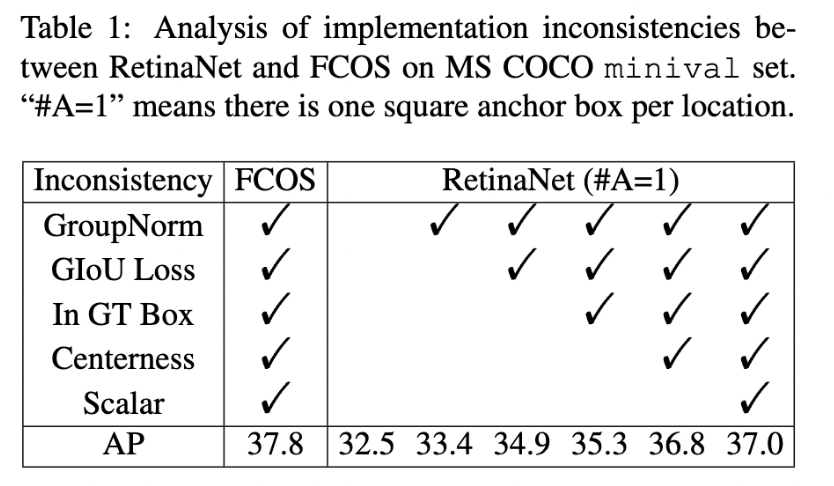
ATSS논문에서는 이 기법들을 RetinaNet에 적용해봤을 때 AP가 32.5에서 37 까지 올라 FCOS와 0.8만큼의 작은 차이가 나는 것을 확인했습니다.이처럼 위의 기법들은 anchor based 방법론에도 적용할 수 있는 것이어서, anchor-based 와 anchor-free methods의 핵심 차이점이 아닌 것을 의미합니다.
Exp2 - Essential Difference
이제 두 방법론에서 남은 차이점은 두가지입니다.
- classification subtask - the way to define positive and negative samples
- regression subtask - the regression starting from an anchor box or an anchor point
Classification
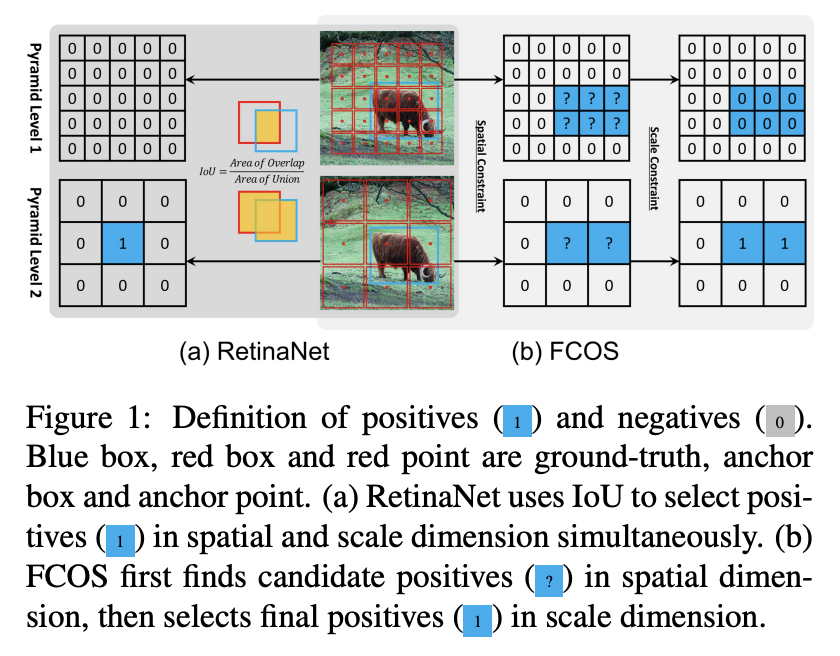 위의 그림 (a)을 보면 RetinaNet은 각 다른 pyramid level 로부터 온 박스들의 p/n을 나누는데에 IOU를 사용합니다.
위의 그림 (a)을 보면 RetinaNet은 각 다른 pyramid level 로부터 온 박스들의 p/n을 나누는데에 IOU를 사용합니다.
처음에는 각 object의 best anchor box와 IOU 가 보다 큰 박스들은 positive, IOU가 보다 작은 박스는 negative로 간주합니다.
(b)를 보면 FCOS는 각 다른 pyramid level 로부터 온 포인트의 positive/negative를 나누는데에 spatial and scale constraints 를 사용합니다.
spatial constraint : anchor point 가 ground truth bounding box 안에 포함되면 Positive Sample, 안되면 Negative Sample (= 해당 샘플이 object인지 여부)
scale constraint : Feature Pyramid Level 별로 서로 다른 크기의 Annotation을 할당하기 때문에, 사전에 정의한 Scale과 Annotation의 크기가 맞지 않는 Pyramid Level에선 모두 Negative Sample로 할당 (= 해당 샘플이 box의 크기를 결정하는지)
처음에는 ground-truth box안에 있는 포인트들을 candidate positive sample로 두고, candidate로부터 final positive를 구하는데, 이 때 각 pyramid level 마다 정의된 scale range를 기준으로 크기가 맞으면 positive, unselected anchor points 는 negative samples가 됩니다.
정리하면
두 방법 모두 spatial, scale dimension 정보를 활용하는데
FCOS는 spatial - scale 순으로 순차적으로 사용하고 , RetinaNet은 IOU 비교를 통해 동시에 사용합니다.
따라서 두 방법은 서로 다른 positive and negative sample을 만들게 됩니다.
Regression
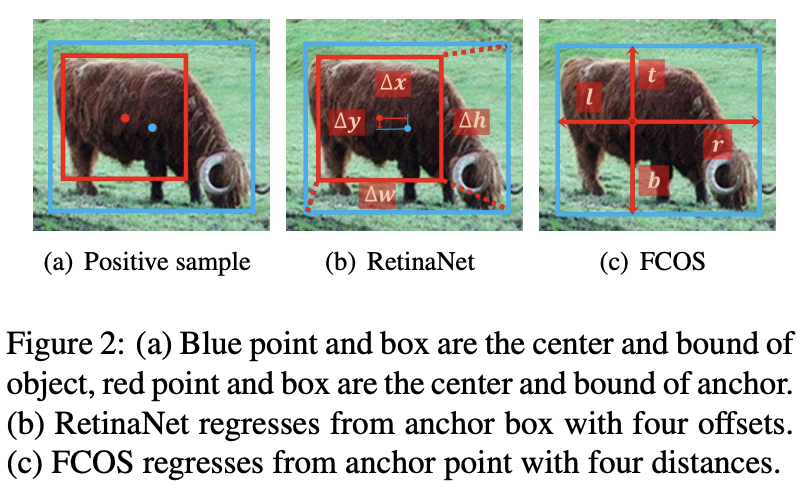
positive/negative sample이 정해졌으면 positive sample로 부터 박스의 구체적인 위치를 regression 합니다.
(b) RetinaNet은 anchor box와 GT box 간의 4개의 offset을 통해 위치를 찾고,
(c) FCOS는 anchor point로 부터 GT box 네 변까지의 거리를 통해 위치를 찾습니다.
즉 regression starting status가 RetinaNet은 box, FCOS는 point 입니다.
Exp2 Result
classification 에서의 define positive and negative sample,
regression 에서의 regression starting status
를 합쳐 두 방법을 비교해본 결과 테이블입니다.
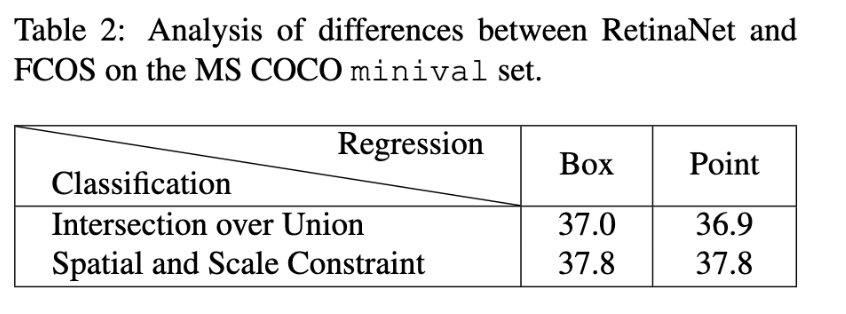
regression starting status : RetinaNet 처럼 Box를 사용하느냐, FCOS 처럼 Point를 사용하느냐 에 따른 score는 큰 차이가 나지 않지만
define positive and negative sample : positive, negative sample을 정의할 때 IOU를 사용하느냐, Spatial and Scale Constraint를 사용하느냐 에 따른 차이는 큰 것을 볼 수 있습니다.
따라서 definition of positive and negative samples이 anchor-based and anchor-free detectors 간의 핵심적인 차이라고 주장합니다.
Adaptive Training Sample Selection(ATSS)
Object Detector를 학습시킬 때
첫번째, classification 단계에서 positive, negative sample을 구분하고
두번째, regression 단계에서 positive sample을 사용해서 위치를 예측합니다.
앞선 실험을 통해 첫번째 단계가 중요함을 알았기 때문에 "how to define positive and negative training samples"를 결정하는 ATSS 를 제안합니다.
ATSS는 hp를 거의 사용하지 않고 object의 통계적인 특성에 따라 automatically 하게 positive, negative sample을 구분합니다.
Algorithm

(1) pyramid level 을 돌면서 GT의 center와 anchor의 center가 가장 가까운(L2 distance) k 개의 anchor 후보를 선정합니다.
(2) (1)에서 뽑은 anchor box 후보들과 GT 와의 IOU를 계산합니다.
(3) (2)에서 계산한 IOU의 평균과 표준편차를 계산합니다.
(4) (1)에서 뽑은 anchor box 와 GT의 IOU 가 후보 anchor들의 평균 + 표준편차 이상이면 Positive, 미만이면 Negative 로 간주합니다
평균과 표준편차를 이용하는 것의 의미
그림 3(a)에 표시된 것처럼 평균이 높으면 high-quality candidate가 있으며 IoU threshold가 높을 것으로 예상
표준편차가 크면 pyramid level 에서 어떤 layer 가 해당 object를 탐지하는데에 적합한지 알 수 있다.따라서 평균 + 표준편차는
object를 잘 탐지하는 pyramid level 에서 나온 후보 anchor 중 high-quality anchor를 positive로 뽑는다는 의미
ATSS의 장점
-
Maintaining fairness between different objects
여기서, IoU 가 정규분포를 따른다고 가정해보면,
평균(IoUs) + 표준편차(IoUs) 이상의 IoU를 갖는 sample은 뽑힌 sample들 중에서
약 상위 16%에 속하는 sample들을 high-quality sample로 보고, positive sample로 판단하는 것으로 이해할 수 있습니다.IoU가 정규분포를 따르지 않는다고 해도,
각 object 가 0.2 * kL 개의 positive sample을 가지고 있는 것이고 이들은 scale, aspect ratio, location 과 무관합니다.이와는 다르게 RetinaNet과 FCOS의 전략은 더 큰 객체에 대해 훨씬 더 Positive sample을 갖는 경향이 있어 서로 다른 객체간에 불공평 함을 초래합니다.
-
Keeping near hyperparameter-free
ATSS 알고리즘에서는 몇개의 후보 positive anchor box를 선택할지를 결정하는 k 만이 hyperparameter 로 사용됩니다.K의 값에 따른 성능을 측정한 결과 너무 작거나(3) 큰(19) 값을 제외하고 7~17사이의 값에서는 성능이 다 비슷한 결과를 보입니다.
 이러한 결과로 저자는 제안하는 label assignment 방법이 almost hyperparameter-free하다고 주장합니다.
이러한 결과로 저자는 제안하는 label assignment 방법이 almost hyperparameter-free하다고 주장합니다.
ATSS 를 사용했을 때 RetinaNet과 FCOS에서 모두 좋은 성능을 보입니다.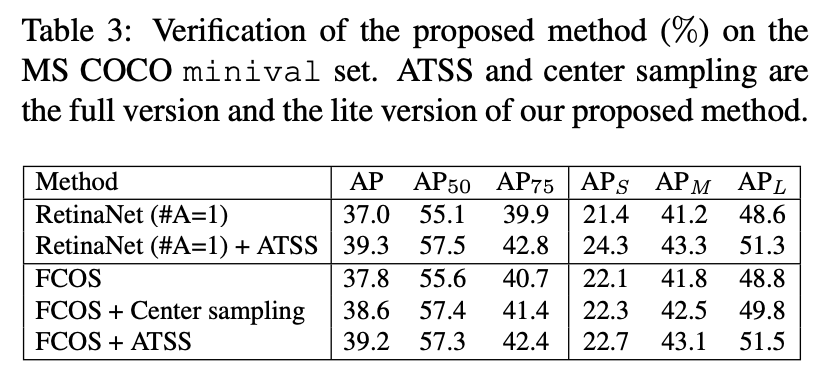
anchor scale과 aspect ratio에 따른 실험 결과 또한 큰 차이가 없습니다. 이는 ATSS가 다른 anchor setting 이 달라져도 robust 하다는 것을 의미합니다.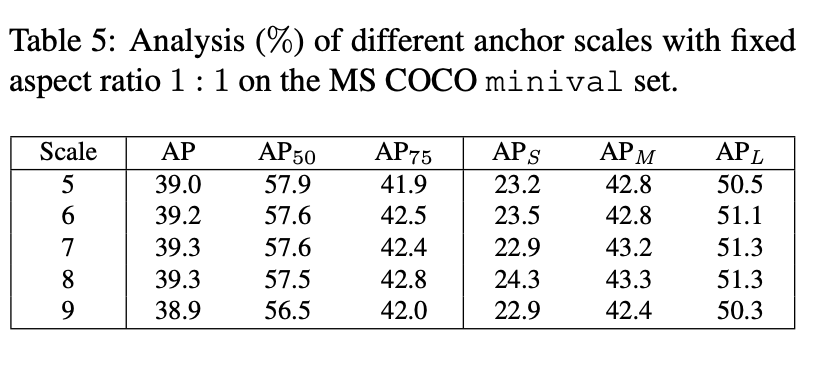
Conclusion
object detection 에서 one-stage anchor-based 와 center-based anchor-free detectors의 핵심 차이는
the definition of positive and negative training samples 입니다.
이를 위해 객체의 통계적 특징을 기준으로 adaptive 하게 positive sample을 정의하는 ATSS 기법 제안하여 성능을 향상시키고 두 방법론 간의 gap을 줄일 수 있었습니다.
Reference
YOLOv1 (You Look Only Once) Paper
RepPoints: Point Set Representation for Object Detection, CVPR 2019
FCOS: Fully Convolutional One-Stage Object Detection, ICCV 2019
anchor tiling : anchor-boxes-for-object-detection
FPN
FocalLoss
