Vision Transformer 연구흐름
- VIT(patch 개수 n에 따라 #operation quadratic하게 늘어나는 단점)
VIT는 특히 training data size, model size가 클 때 global information, long-range interactions를 얻는 것은 CNN보다 뛰어난 성능을 보인다.
Background
-
Review of Linear Attention in NLP
우리가 잘 알고있는 Attention의 수식을 보면 다음과 같다.의 Similarity 함수로 Softmax(exp)를 사용하면 그 수식을 softmax attention이라고 부른다.
t시점의 디코더의 은닉상태 Q(Query) 벡터와 모든 시점의 인코더의 은닉상태 K(Key) 벡터를 dot product(내적) 하여 유사도를 구하는 과정이 있다.
따라서 이 attention의 시간복잡도는 input sequence 길이인 n을 제곱한 이 된다.Linear Attention의 장점
Similarity 함수로 ReLU와 같은 kernel fuction을 사용하면 Linear Attention이라고 부른다.이 때의 Attention 수식은 아래처럼 정리할 수 있다.
이렇게 정리가 되면 과 를 한번씩만 계산하고 재사용하면 되기 때문에 시간복잡도와 메모리 사용이 O(N)으로 줄어든다. (sequence의 길이 n이 d보다 작을 때)

https://arxiv.org/pdf/1706.03762.pdf : Attention All You Need (2017) Vaswani et al.
Related Work
- Vision Transformer
- Efficient Vision Transformer
[Efficient Transformer]
<attention module의 complexity를 줄이자! 는 논문>
Swin Transformer, 2021
이미지를 window로 나누어 local window 내에서만 self-attention을 수행함
[PVT(Pyramid Vision Transformer)](Pyramid Vision Transformer)
Spatial Reduction Attention(SRA) : attention 전에 key, value의 spatial 사이즈를 줄이는 방법
MobileVIT V2, 2018, Linformer, 2020
token을 projection해서 차원을 줄이는 방법
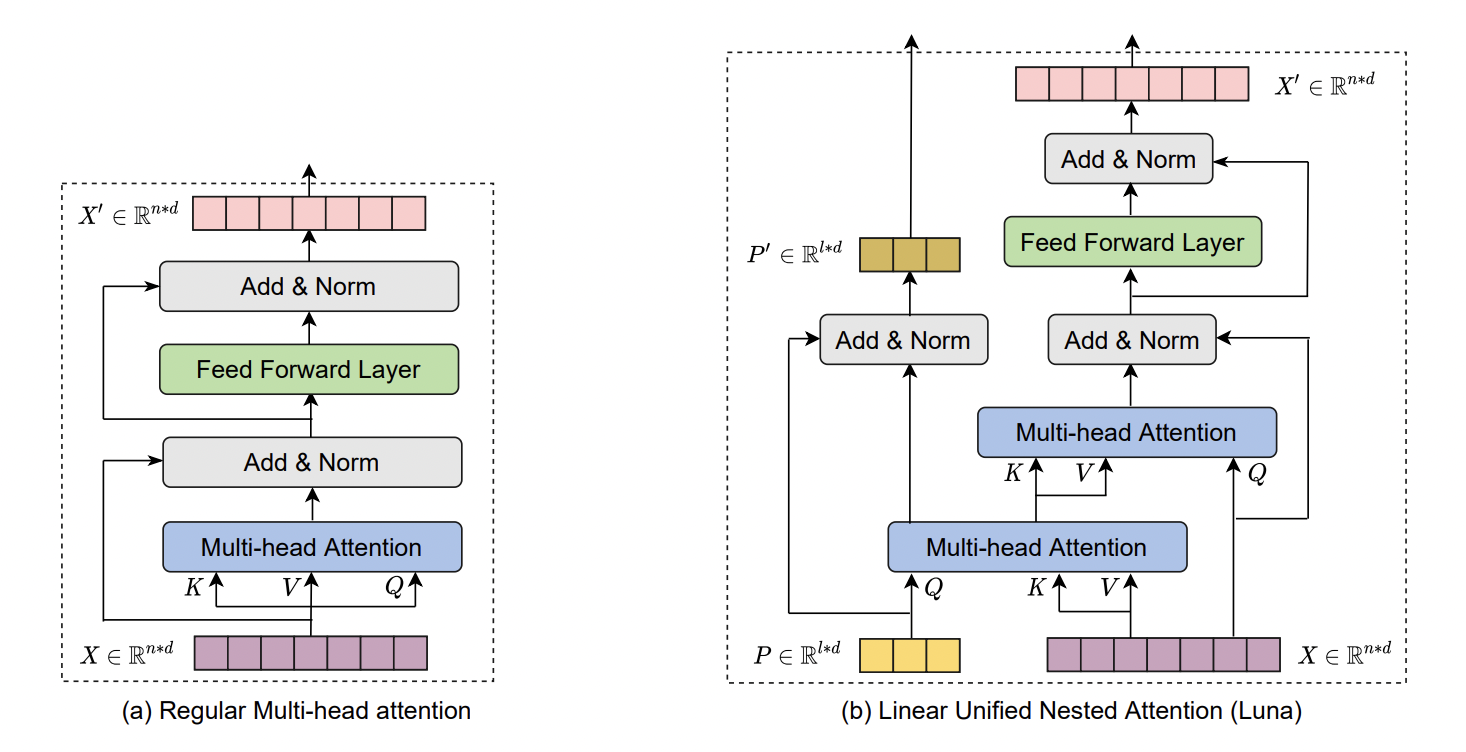
Luna: Linear Unified Nested Attention
NLP - Machine Translation 분야에서 나온 논문이긴 한데 좋은 성능(LRA score)을 보였으며, 이런 접근도 가능하다는 걸 보이기 위해 첨부함
linear unified nested attention - attention을 두번 겹쳐서 수행하여 Q, K의 사이즈를 다르게 해서 의 시간 복잡도를 linear하게 만듬.X-former 시리즈
Performer - https://arxiv.org/abs/2009.14794v4
Linformer - https://arxiv.org/abs/2006.04768v3
Reformer - https://arxiv.org/abs/2001.04451v2
Mobileformer - https://arxiv.org/abs/2108.05895v3
EfficientVIT
EfficientViT: Enhanced Linear Attention for
High-Resolution Low-Computation Visual Recognition
1. Abstract
Input resolution에 따라 computational complexity가 quadratic하게 증가하는 VIT (softmax attention을 사용하기 때문)
Swin, PVT와 같은 방법은 비용을 줄이기 위해 local window 내의 softmax attention을 제한하거나 key/value tensor의 resolution을 작게 만들었지만 이는 VIT의 이점인 global feature extraction의 성능도 제한해버린다.
softmax attention을 제한 ??
Swin Transformer의 경우 window 단위로 self attention을 진행하기 때문에 complexity가 image size에 대해 linear하다.
따라서 본 논문에서 제안하는 EfficientVIT는 다음의 방법을 제안한다.
- local feature extraction ability를 향상시키기 위해 softmax attention 대신 linear attention with depthwise convolution 사용
이를 통해 EffinientVIT는 linear computational complexity안에서 global and local feature extraction capability를 유지한다.
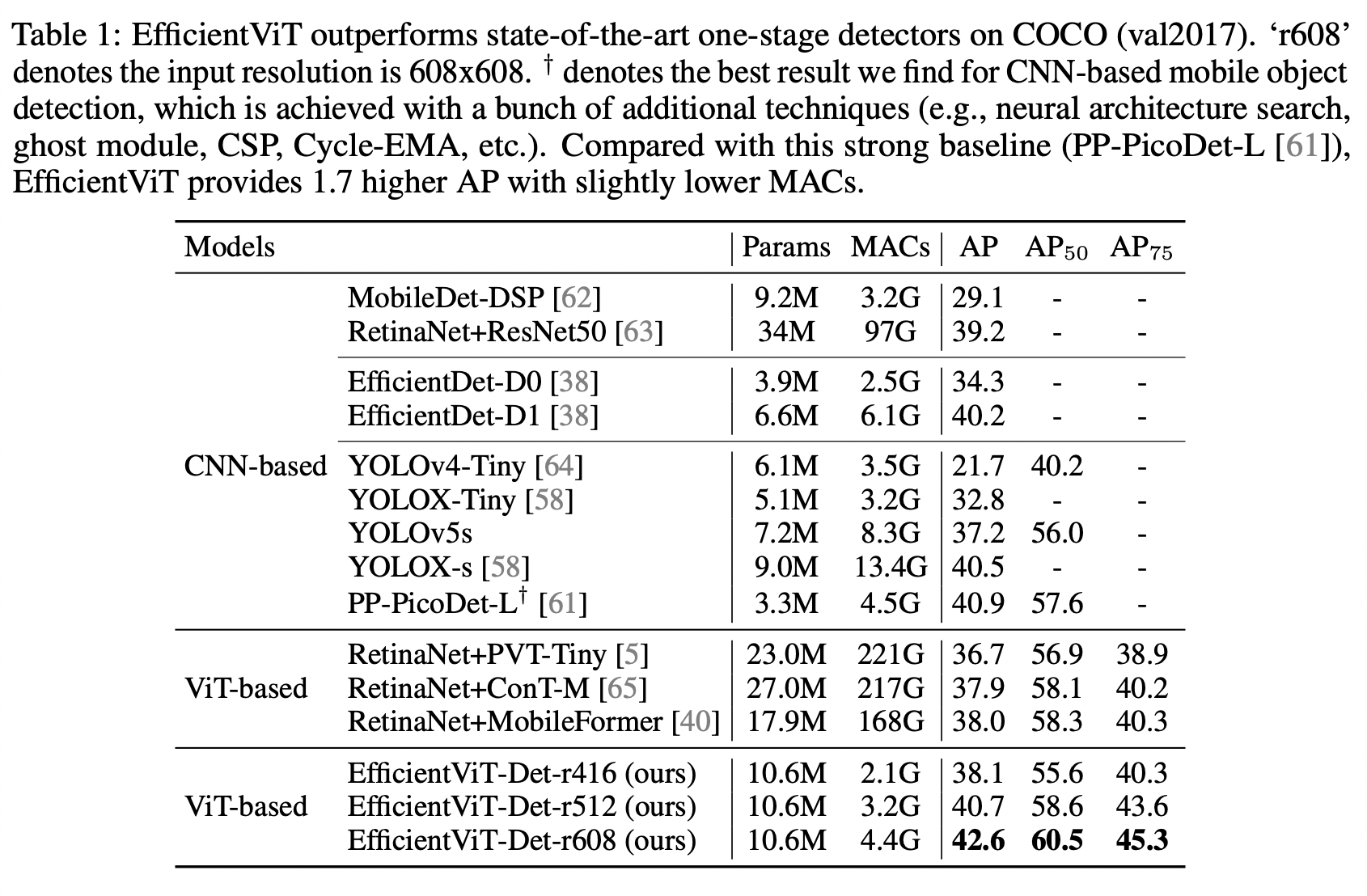
이를 통해 COCO 에서 EfficientDet-D1과 비교했을 때 2.4 AP while having 27.9% fewer MACs인 42.6 AP with 4.4G MACs 달성했다. 등등
2. Introduction
low-resolution & high-computation region에서는 VIT가 좋은 성능을 보이지만, high-resolution & low-computation scenarios에서는 CNN보다 성능이 떨어진다.
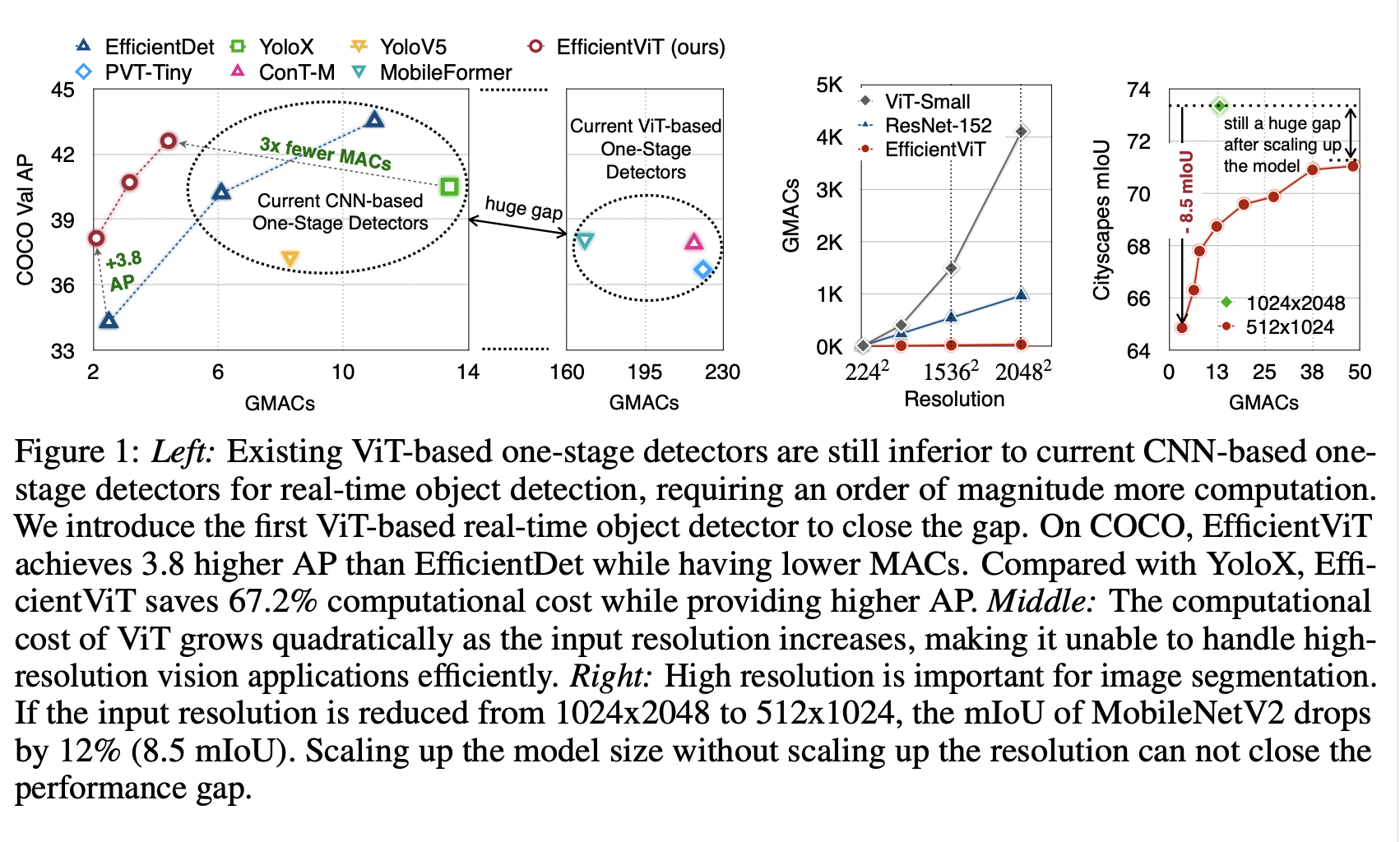 Figure 1의 왼쪽 그래프가 COCO dataset에서 VIT-based, CNN-based one-stage detector들을 비교한 것이다. 둘 사이에 160G MACs의 큰 차이가 있다.
Figure 1의 왼쪽 그래프가 COCO dataset에서 VIT-based, CNN-based one-stage detector들을 비교한 것이다. 둘 사이에 160G MACs의 큰 차이가 있다.
이런 차이가 나는 이유는 VIT에서 computational bottle neck을 유발하는 softmax attention module 때문인데, 이 모듈의 computational cost는 input resolution이 커짐에 따라 quadratically하게 증가하기 때문이다.
이를 해결하기 위한 가장 정확한 첫번째 방법은 input resolution을 줄이는 것이지만, 자율주행이나 의료 이미지 프로세싱과 같은 분야는 high-resolution이 필수적이다. 위 사진의 맨 오른쪽 사진이 Cityscapes dataset에서의 mobileNetV2의 input resolution에 따른 성능(mIOU)차이를 보여준다.
input resolution을 1024x2048에사 512x1024로 줄였을 때, 성능은 12%(8.5 mIOU)하락한다. model의 사이즈를 늘리는 것으로는 MACs가 3.6배 증가했음에도 불구하고 input resolution을 증가시킨 것만큼의 performance는 나오지 않는다.
두번째 방법은 softmax attention을 할 때 fixed-size local windows를 사용하여 attention scope을 제한하거나, key/value tensor dimension을 줄이는 방법도 있다. 하지만 이러한 방법은 VIT의 가장 큰 장점인 non-local attention capability(the global receptive field)를 감소시켜서 large-kernel CNN보다 안좋은 예측을 하게된다.
그래서 이 논문에서는 EfficientDet보다 COCO map 3.8이 높으면서 MAC은 더 적고 , YOLOX와 비교했을때는 67.2% 의 computional cost를 감소한 모델인 EfficientVIT를 제안한다.
이는 이전 논문들처럼 softmax attention을 제한하여 사용하지 않고, linear attention(Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention, 2020)을 사용한다.
linear attention의 가장 큰 장점은 softmax attention과 같이 의 attention map을 유지하는 것이다. 하지만 matrix multiplication 과정에서 전체 attention map을 계산하지 않도록 하여 linear computational complexity를 가지고 softmax attention의 global feature extraction capacity를 유지한다.
Linear Attention의 장점은 두가지가 있다.
- Softmax Attention과 마찬가지로 의 attention map을 사용한다는 것인데, matrix multiplication의 associative property를 활용해서 전체 attention map을 명시적으로는 계산하지 않게하여 계산복잡도를 linear하게 유지하면서 softmax attention의 global feature extraction capacity를 유지한다.
- Softmax를 사용하지 않아 mobile에서 사용하기에 좋다.
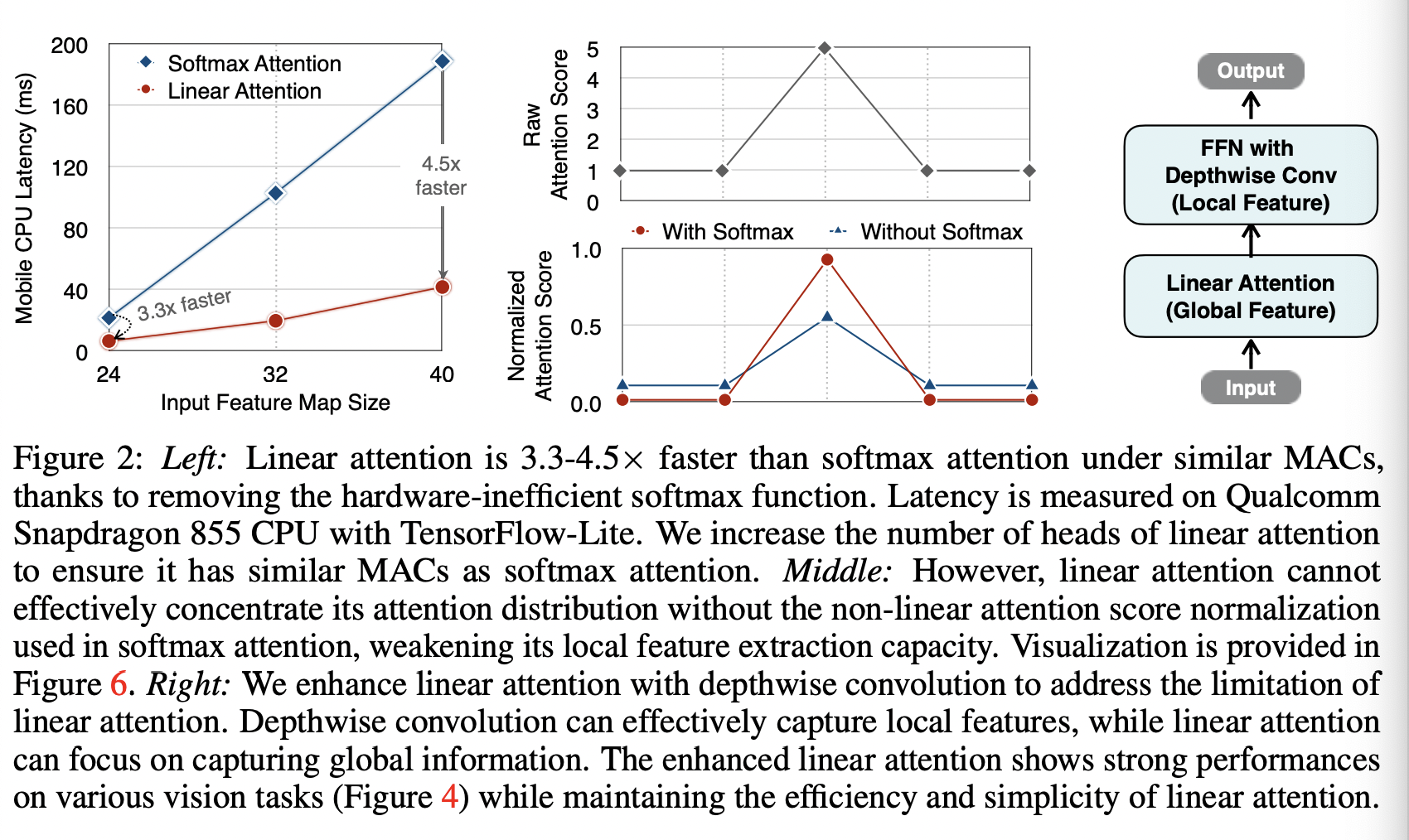 Figure2의 맨 왼쪽 그래프를 보면 비슷한 MACs 일 때 Linear attention은 softmax attention에 비해 3.3~4.5배까지 빨라진다. (MAC를 맞추기 위해 linear attention을 사용할 때는 multi-head의 갯수를 늘렸다.)
Figure2의 맨 왼쪽 그래프를 보면 비슷한 MACs 일 때 Linear attention은 softmax attention에 비해 3.3~4.5배까지 빨라진다. (MAC를 맞추기 위해 linear attention을 사용할 때는 multi-head의 갯수를 늘렸다.)
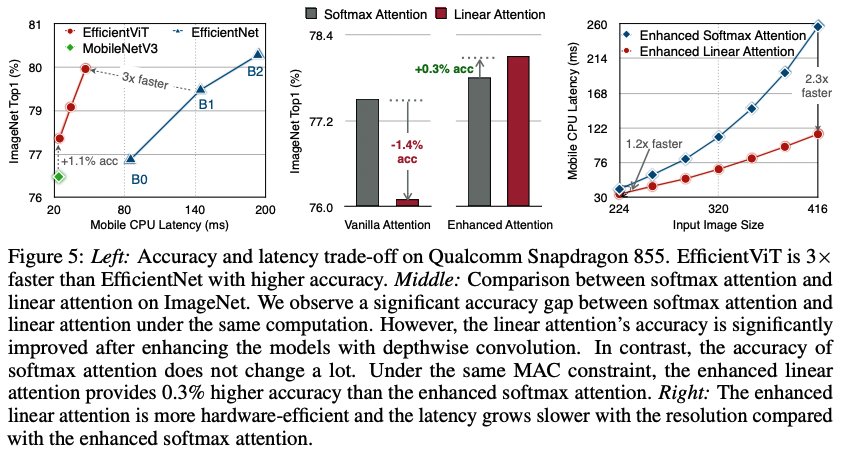
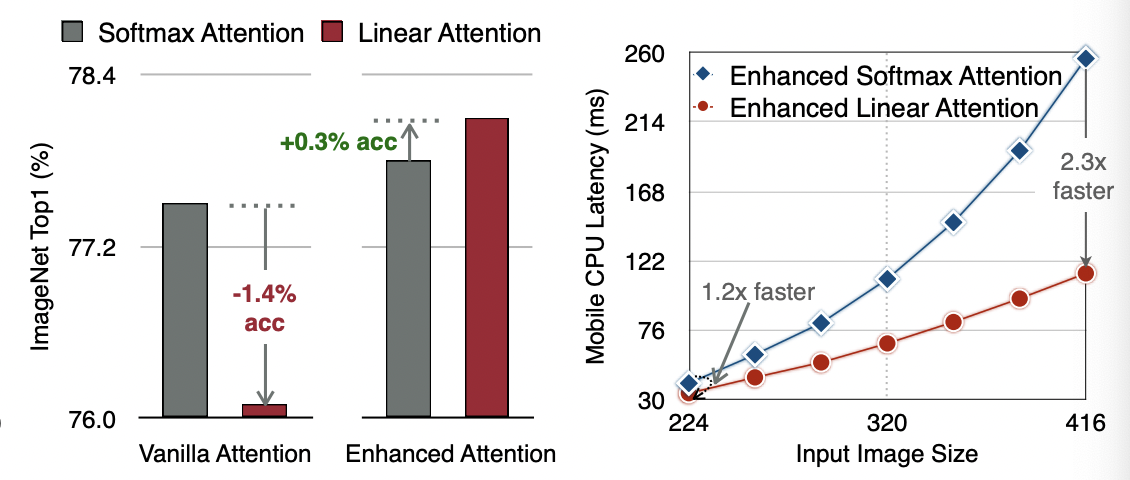
그러나 linear attention은 바로 적용하는 것은 단점이 있다. 이전 연구들에서 linear attention 과 softmax attention 간의 큰 performance gap을 보였다. Figure5 중간 그래프를 보면 ImageNet top1 acc이 linear attention을 사용했을 때 1.4% 감소한다.
두 attention의 차이는 linear attention은 non-linear attention score normalization scheme이 부족하다는 것이다. linear attention이 local pattern에서 만들어진 high attentention score에 attention 분포를 집중시킬수 없게하여 local feature extraction capacity를 떨어뜨린다. 이는 attention map을 시각화한 아래의 사진에서도 볼 수 있다.
non-linear attention score normalization?
attention score를 얻고 softmax 를 취해 attention distribution을 얻는 과정,,, softmax가 아닌 ReLU 사용시 음수값은 0이 되어 attention 분포의 표현력이 제한된다는 말인듯
따라서 이 논문에서는 linear attention의 low complexity and low hardware latency를 살리기 위해 각 FFN layer의 사이에 depthwise convolution을 넣은 enhance linear attention구조를 제안한다.
(근데 구체적으로 어떻게 했는지는 논문에서 안알려줌(코드 공개도 안함))
기존의 mobile VIT 모델(Mobile-former, MobileVIT, NASVIT)들은 parameter size와 MAC를 감소시키는 것에 집중했지만 이 논문에서는 mobile device에서의 latency를 감소시키는 것에 집중했다. 따라서 앞선 모델들과 달리 complicated dependency, hardware inefficient operations가 없다.
- contribution 요약
- ViT architecture를 사용한 high-resolution low-computation visual recognition 연구. Linear Attentiond이 Softmax Attention의 대안이며 하드웨어 친화적이라는 것을 밝혔다.
- enhanced linear attention 제안하여 linear attention의 약점인 local feature extraction을 보완.
- EfficientViT based on our enhanced linear attention 제안. (COCO object detection, Cityscapes semantic segmentation, ImageNet classification)에서 nas나 kd같은 add-on technique 없이 CNN-based models( (e.g., EfficientDet, SegFormer, EfficientNet))보다 높은 성능을 기록.
3. Method
-
Enhancing Linear Attention with Depthwise Convolution
linear attention 이 softmax attention보다 computational complexity and hardware latency는 뛰어나지만, NLP, Vision 태스크 모두에서 성능이 떨어진다는 연구가 있었다.
이 원인을 local feature extraction capacity라고 생각했다. Softmax attention과 linear attention을 사용했을 때 attention score를 시각화해보면
linear attention을 사용했을 때 local pattern에서 만들어지는 high attention scores 에 집중하지 못하는 것을 볼 수 있다.
 이를 해결하기 위해 local feature axtraction에 큰 강점을 갖는 depthwise convolution을 FFN layer사이에 끼워넣어 computational overhead를 크게 발생시키지 않으면서 linear attention의 local feature extraction capacity를 보완했다.
이를 해결하기 위해 local feature axtraction에 큰 강점을 갖는 depthwise convolution을 FFN layer사이에 끼워넣어 computational overhead를 크게 발생시키지 않으면서 linear attention의 local feature extraction capacity를 보완했다. -
Building Block
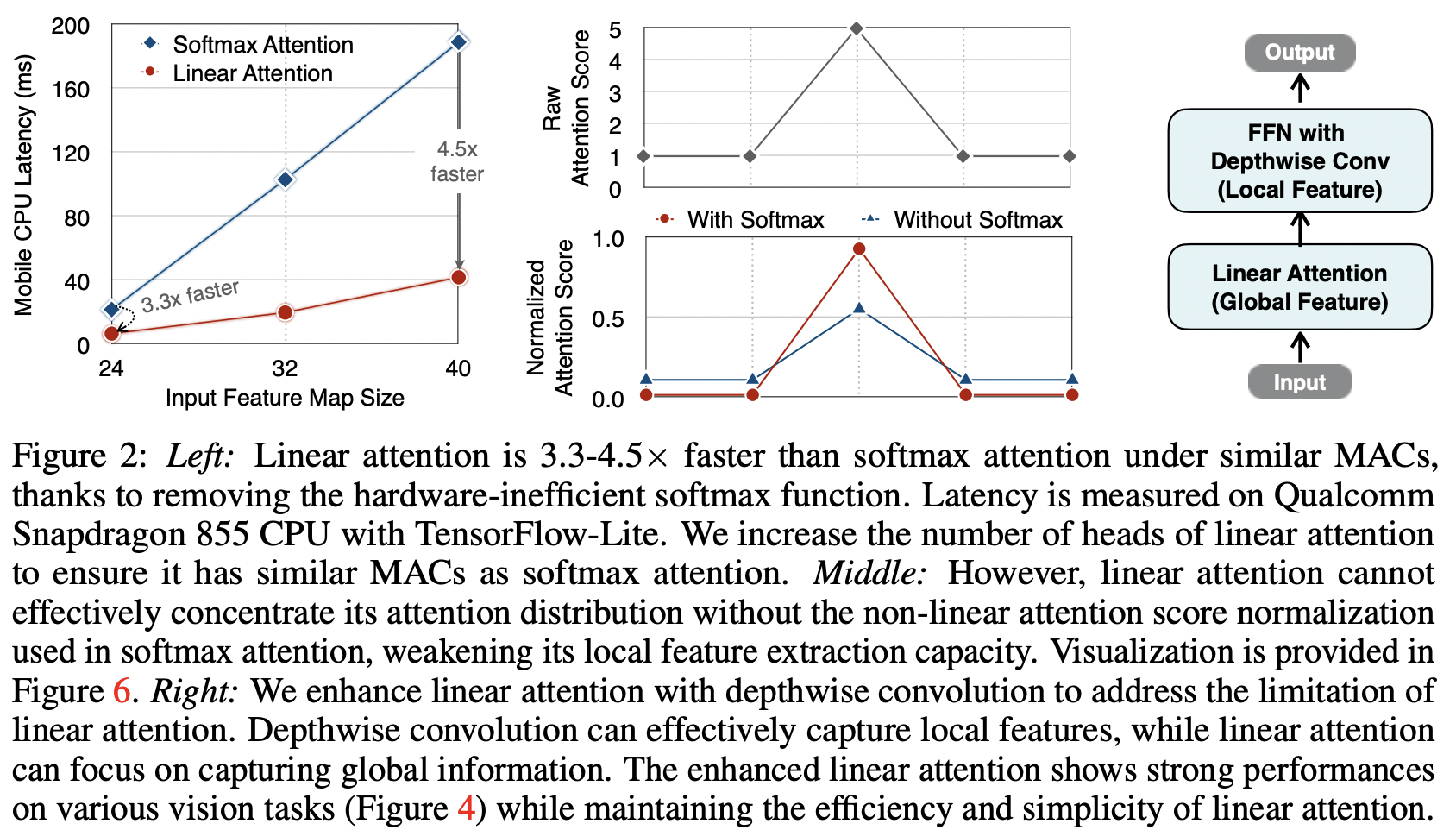
FFN layer with depthwise convolution의 블록구조는 위 Figure2의 맨 오른쪽과 같다. EfficientVIT에서는 이전 연구(SwinTransformer, CoatNet)들과 다르게 relative position bias를 사용하지 않았다. relative position bias는 모델의 성능을 향상시키지만, resolution이 달라지면 성능차이가 크게 난다. 이를 제거하여 EfficientVIT는 input resolution에 flexible하게 했다.relative position bias?
VIT에서의 positional encoding(PE)을 말함. Segformer, NeurIPS 2021 논문에서 resolution of PE는 고정되어 있기 때문에 test 시의 input resolution이 train에 사용한 resolution과 다르면 성능이 하락한다고 하며 A novel positional-encoding-free and hierarchical Transformer encoder 제안.또한 low-computation CNN 이전 연구들과 다르게, downsampling blocks을 위한 extra downsampling shortcut을 추가했다. 각 shortcut은 average pooling과 1x1 convolution을 한다. 이를 통해 학습을 안정화시키고 성능을 높였다.
-
Macro Architecture
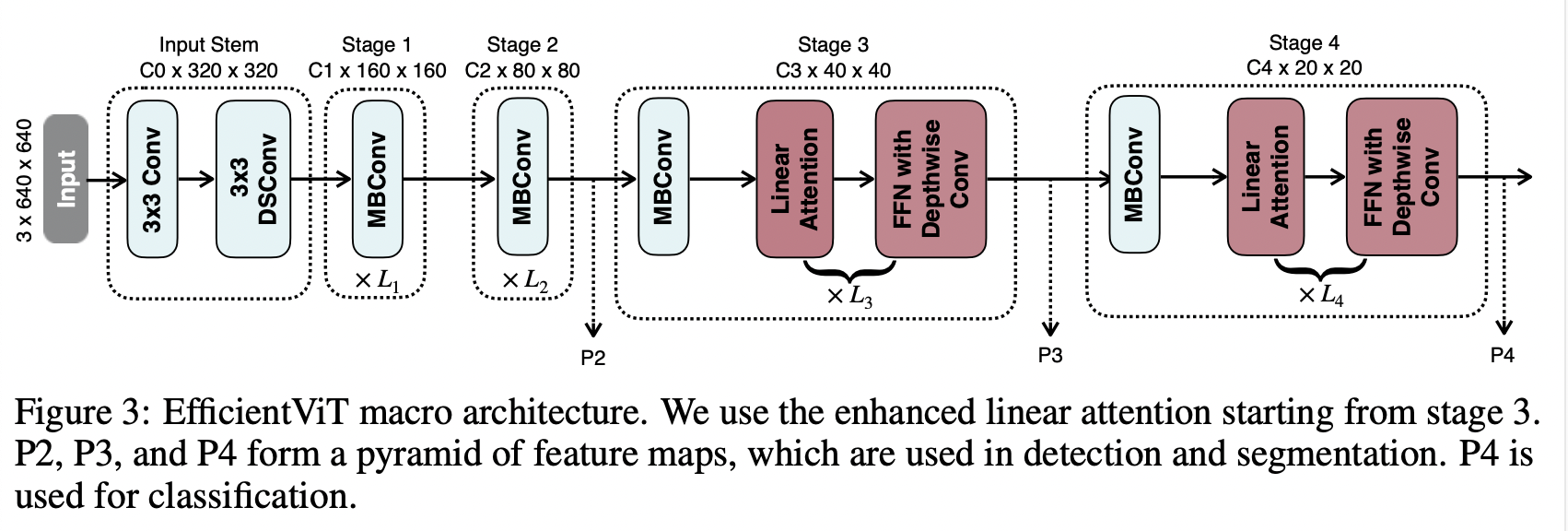 EfficientVIT의 구조는 input stem과 4 stage로 이루어져있다. 최근 연구(CoatNet, Levit, Early convolutions help transformers see better)들에서 early stage에서 convolution을 사용하는 것이 VIT에 더 낫다는 것을 보였으므로, enhanced linear layer를 stage3에서 시작한다.
EfficientVIT의 구조는 input stem과 4 stage로 이루어져있다. 최근 연구(CoatNet, Levit, Early convolutions help transformers see better)들에서 early stage에서 convolution을 사용하는 것이 VIT에 더 낫다는 것을 보였으므로, enhanced linear layer를 stage3에서 시작한다. efficient backbone의 hyper parameter는 MBConv(=MobileNetV2)에서 사용한 ratio e를 그대로 사용(FFN도 e=4 그대로 사용), kernel size k=5 (input stem 제외).
e?
activation function 모든 레이어에 Hard Swish 사용.
그림에서 P2, P3, P4는 feature pyramid를 위한 output feature.
detection을 위해서는 YoloX를 사용, segmentation을 위해서는 Fast-SCNN처럼 P2와 P4dmd fusion한 뒤 몇개의 convolution layer로 이루어진 lightweight head에 전달.
classification을 위해서는 MobileNetV3처럼 P4를 lightweight head에 전달.
요즘 VIT 연구는 trfmer+CNN이 아니라 CNN+ trfmer다?
CoatNet,Levit, Early convolutions help transformers see better
들에서 early stage에서 convolution을 사용하는 것이 VIT에 더 낫다는 것을 보였다.
이유는 ?
Transformer는 초기의 Input이 raw image patches에 대한 feature map의 sequence로 들어가게 된다.
하지만 hybrid model에서는 patch embedding이 특정 backbone model에 의해서 추출된 CNN feature map을 기반으로 적용된다. (원래 이미지에 대해 size가 줄어들고, 응축된 정보를 갖는다.)
4. Experiments
-
Dataset
COCO object detection, Cityscapes semantic segmentation, ImageNet classification -
Model Architecture
build model around 400M MACs under a 224x224 input resolution
detailed configuration : C0=16, C1=24, C2=48, C3=96, C4=192; L1=2, L2=3, L3=5, L4=2 -
COCO object detection
-
Cityscapes semantic segmentation

-
ImageNet classification
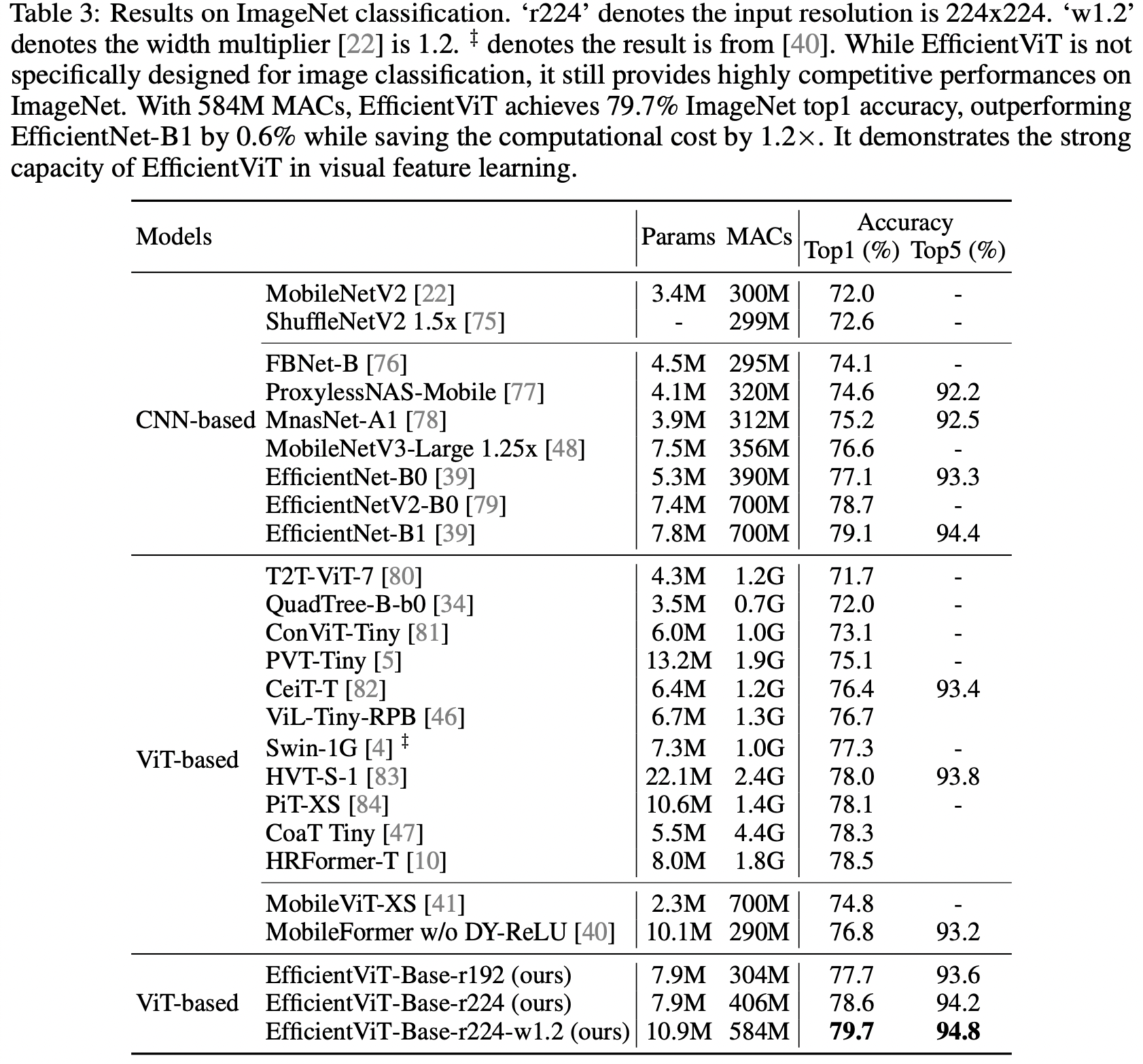
5. Conclusion
enhanced linear attention 구조를 통해
high-resolution low-computation visual recognition에서 비교적 적은 MAC와 더 좋은 성능을 달성함
Ablation Study
enhanced linear attention의 효과를 알아보기 위해 ImageNet에서의 Top1 Acc을 측정했을 때, 0.3의 성능 향상을 보였으며 mobile device에서의 latency도 2.3배 빨랐다.
6. Discussion
Limitations of Paper
- Latency data 부족하여 제대로 된 결과분석 불가
- Limited Novelty : Depthwise Convolution with FFN
- Unfair Comparison
1. Data Augmentation- HardSwish Activation
- MAC vs #Params , What to optimize?
- Latency data 부족하여 제대로 된 결과분석 불가, batch size도 1로 둠.
On Qualcomm Snapdragon 855 CPU, EfficientViT runs 3×faster than EfficientNet while providing higher ImageNet accuracy
- Limited Novelty : Depthwise Convolution with FFN
FFN에 Depthwise 를 섞은게 어떤 의미일까?seq len(spatial) * hidden dim(channel)
FFN은 각 tocken의 channel을 독립적으로 섞음. 여기에 Depthwise를 섞는다는 말은 각 patch tocken의 channl정보를 섞을 때 spatial 하게 옆에 있는 tocken 정보를 본다는 말 아닐까?
- Unfair Comparison - 1. Data augmeantation
VIT는 inductive bias가 부족해서 augmentation 많이 해야한다?는 연구?
-> 각 논문마다 적용한 augmeatation 정도가 달라 절대적 비교가 어렵다.
논문 신뢰도의 문제라기보단 그냥 연구흐름을 파악하는 것에 집중하자.
- Unfair Comparison - 2. HardSwish Activation
hard swish function을 쓰면 왜 좋을까mobile CPU에서 inference를 하게 되면 swish를 쓰는 것보다 hard swish를 쓰는게 latency 측면에서 훨씬 효율적입니다. sigmoid를 계산하는게 꽤나 비싸기 때문에 이를 linear 연산들로 근사한 hard swish가 더 빠릅니다. 이는 MobileNetV3 논문에서 잘 설명해주고 있으니 참고하시면 되겠습니다. (https://arxiv.org/abs/1905.02244)
Unfair Comparison - 3. MAC vs #Params , What to optimize?
Experiments의 표를 보다보면,, 성능은 향상했는데 정작 Parameter 수는 늘어나는 것을 볼 수 있다... (semantic segmentation에서 SegFormer와 비교하는데 MAC는 62.8G -> 19.1G 로 줄었지만 param수는 3.8M -> 6.5M으로 늘었다든가 하는,,,)Efficient AI 연구에서는 어떤 metric을 optimize 해야할까?
너무나 당연히 case-by-case로 달라집니다. task, model, target HW, target performance 에 따라 달라질 수 있겠네요. 예를 들어 MCU처럼 SRAM이나 Flash memory가 극도로 부족한 환경에서는 params나 peak memory usage를 줄여서 느리더라도 돌아갈 수 있게 만드는게 중요할 것이고, GPU 기반으로 실제 서비스를 운영하는 상황인데 메모리는 넉넉하다고 하면 MACs를 줄여서 빠르게 만드는게 좋겠죠. 목표가 있고, 현재 상태를 분석하면 무엇을 줄여야하는지 정해진다고 봅니다. 당연히 둘다 줄일 수 있는게 best 겠고요.
현업에서 모바일에 임배드 할 수 있다고 한다면 혹시 모델의 크기 (param 수 혹은 용량)와 latency (혹은 대략적인 FLOPs)가 어느 정도면 모바일에 임배드할 수 있다고 주장할 수 있을까요? + MAC(=Flop)과 Parameter 수와 latency는 호응 가능한 metric일까?
모바일 기종에 따라 엄청 다릅니다. 갤럭시와 아이폰만 해도 성능 차이가 꽤 나고, 갤럭시 중에서도 S9과 S22 뭐 이렇게 비교하면 성능차이가 어마어마합니다. RAM 크기는 기종에 따라 다르지만 보통 수 GB는 되기 때문에 그 안에 들어오면 어떻게든 올릴 수 있기는 할겁니다. (다른 앱들과 함께 안정적으로 동작시킬 수 있는지는 다른 얘기입니다.)
latency는 또 case-by-case일텐데요, 애초에 real-time을 요구하는 서비스라면 40ms 정도는 되어야겠고, 이번에 아이폰에 업데이트된 누끼 따주는 segmentation 모델같은건 real-time까지는 필요하지 않으니 좀더 여유가 있을겁니다. FLOPs는 기종, 모델이 달라지면 latency로 translate하기 정말 어렵습니다.
Ref
