Character Region Awareness for Text Detection(CRAFT), CVPR 2019
Abstract
Scene Text Detection 에서 이전의 방법들은 단어 수준으로 labeling되어 있어 arbitrary shape을 나타내는 것에는 한계가 있음
CRAFT는 문자 단위 탐지와 문자간의 afffinity score를 이용하여 효율적으로 text detection 을 수행함
-
weakly-supervised learning
존재하는 dataset이 대부분 word level annotaion → character level GT 없음
word level annotation된 데이터셋에서 character level pseudo label을 생성하는 interim model 제안 -
Affinity representation
affinity 계산을 위해 model은 새롭게 제안된representation 을 학습 -
Contribution
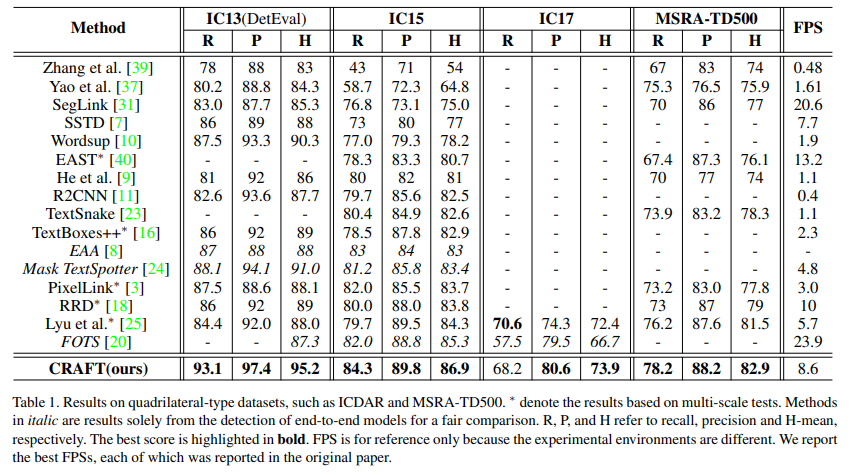
TotalText , CTW-1500 dataset을 포함한 6개의 benchmark에서 SOTA 달성
Intro
CRAFT 에서 character producing
region score
: 해당 픽셀이 문자(character)의 중심일 확률, 각 문자를 localize하는데 사용됨
affinity score
: 해당 픽셀이 인접한 두 문자의 중심일 확률, 각 문자를 word instance로 연결하는데 사용됨
Architecture
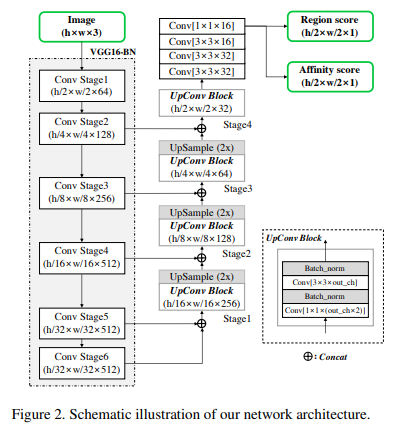
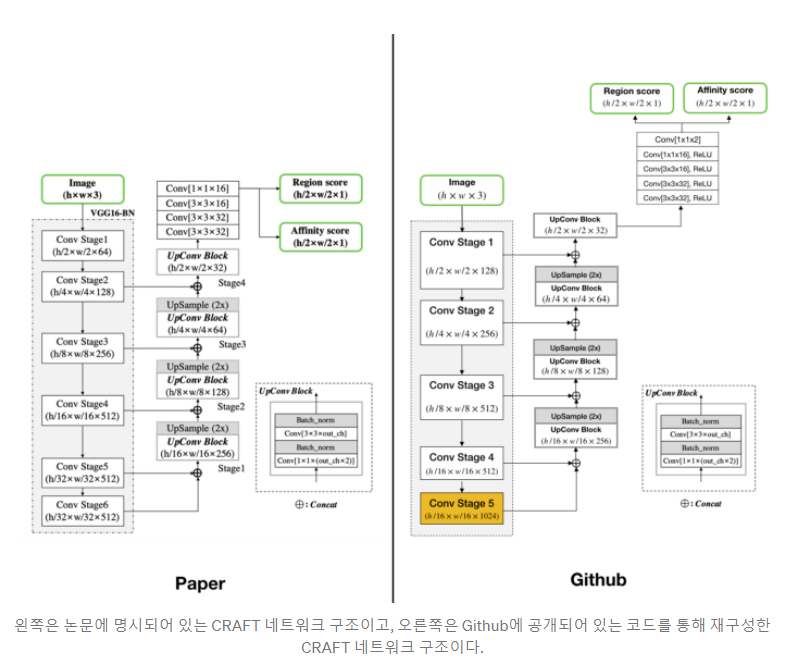
fully convolutional network architecture
backbone : VGG16 with BN
skip connections in the decoding part (similar to U-net)
Training
training은 총 3단계로 이루어 짐
(1) Ground Truth Label Generation : word level→ character level pseudo label 생성
(2) Weakly-Supervised Learning : (1)에서 생성한 label 로 interim model 학습 (Interim model은 word-level GT로 이미 학습되어 있음)
(3) Inference : region score와 affinify score를 가지고 최종 결과 도출
하나씩 자세히 살펴보면
(1) Ground Truth Label Generation
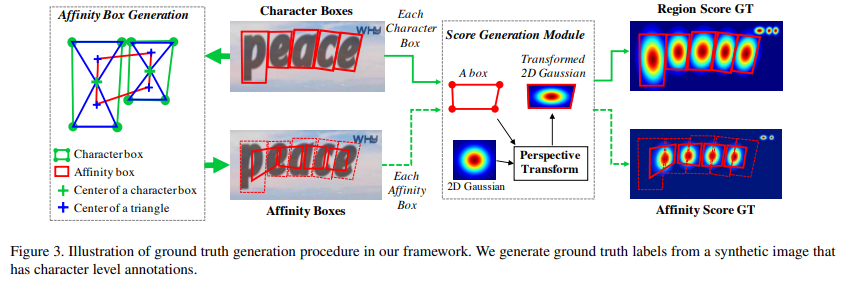
<Region score GT 만드는 방법>
각 픽셀을 별개로 labeling하는 binary segmentatino map과 다르게, Gausian heatmap으로 문자의 중심일 확률을 encode
1) 2차원의 isotropic Gaussian map을 준비
2) character box에 맞게 Gaussian map의 perspective transform 을 계산
3) box area에 맞게 warping = Transformed Gaussian map을 원본 이미지의 박스 좌표에 맞게 위치시켜 Label Map 얻음
<Affinity score GT 만드는 방법>
인접한 character box에 의해 정의됨.
1) character box의 대각선을 이어 만들어진 두 삼각형
2) 두 삼각형의 중심을 인접한 삼각형의 중심과 이어 Affinity Box를 만듬
3) Region Score GT 1) ~ 3) 과 같음
(2) Weakly-Supervised Learning
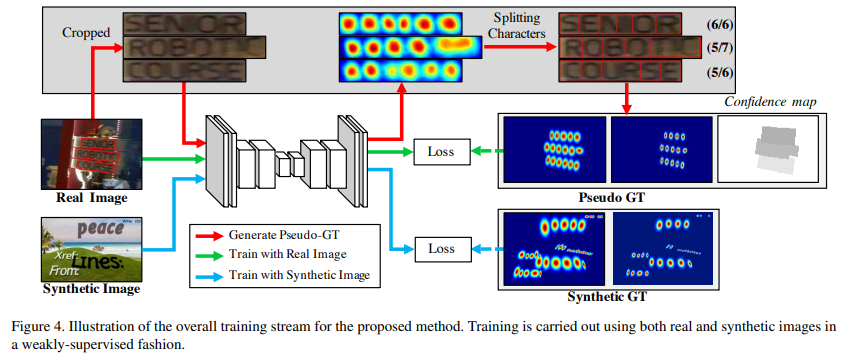
GT를 생성하려면 character level annotation이 필요한데, 보통 dataset은 word level annotation.
따라서 각각의 word-level annotation에서 character-level annotation을 생성하여 학습하는 weakly-supervised learning
→ word-level annotation이 있는 real image 가 주어지면 학습된 interim model이 cropped word image의 character region을 예측 (character-level bounding box를 만들기 위해)
< entire procedure for splitting the characters >
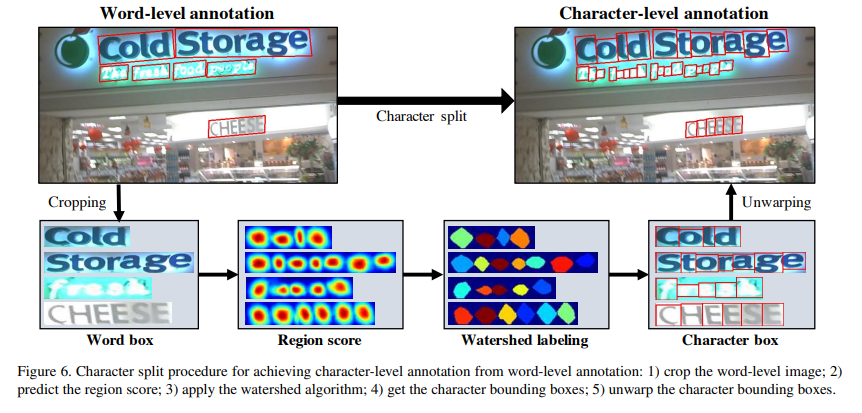
1) the word-level images are cropped from the original image
2) the model trained up to date predicts the region score
3) the watershed algorithm [35] is used to split the character regions, which is used to make the character bounding boxes covering regions
4) the coordinates of the character boxes are transformed back into the original image coordinates using the inverse transform from the cropping step.
이렇게 생성한 Pseudo-GT는 완벽하지 않기 때문에 정확하지 않은 character box를 생성함
interim model 의 prediction에 대한 신뢰도(confidence score)를 계산하여 loss에 곱해줌으로써 Word-box에 대응되는 픽셀들은 Interim model의 문자 영역 예측 정확도에 비례하는 가중치가 부여됨.
→ 학습을 반복할 수록 interim 모델의 예측정확도를 높임
신뢰도는 word의 길이-ㅣ(w)- 와 interim model이 예측해서 나온 문자의 갯수 -lc(w)- 차이를 비율로 계산함
→ 
그런데 만약 이 신뢰도가 0.5보다 낮다면 학습에 악영향을 줄 수 있기 때문에
word안의 각 character의 길이(width)는 일정할 것이라는 가정 하에 word box 를 문자의 갯수만큼 n등분하여 character box를 생성하고, 신뢰도는 0.5로 설정함.
하나의 이미지 안에서 pixel-wise confidence map Sc는 다음과 같이 계산.
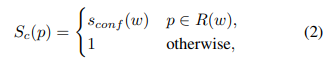
해당 픽셀이 word box안에 있으면 그 word box의 신뢰도, 아니면 1
loss는 다음과 같음
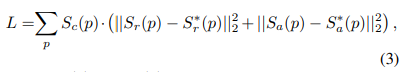
각 픽셀 p에 대한 Region score의 예측값 Sr(p)와 정답 Sr(p)의 유클리드 거리 오차와 각 픽셀 p에 대한 Affinity score의 예측값 Sa(p)와 정답 Sa(p)의 유클리드 거리 오차의 총합을 Loss로 정의하며, 이 함수를 최적화하는 것이 학습의 방향
여기까지가 CRAFT모델이 이미지 내의 문자 영역(Character Region)을 인식(Awareness)할 수 있도록 학습하는 방법
(3) Inference
Inference = 마지막으로 모델을 통해 예측한 Region Score(Sr)와 Affinity Score(Sa)를 이용해 최종 결과물을 도출해내는 방법
최종 결과물 = word-level bounding boxes QuadBox
1) 이미지와 같은 크기의 0으로 초기화 된 binary map M. 만약 픽셀 p의 Sr or Sa 가 각각의 threshold보다 크다면 M (p) 를 1로 설정
2) Connected Component Labeling 수행
3) 각 Label을 둘러싸는 최소 영역의 회전된 직사각형 찾기(OpenCV에서 제공하는 connectedComponents()와 minAreaRect()를 활용)
Word-Level QuadBox를 다음과 같은 과정을 통해 문자 영역 주위에 다각형을 만들어 곡선 텍스트를 효과적으로 처리
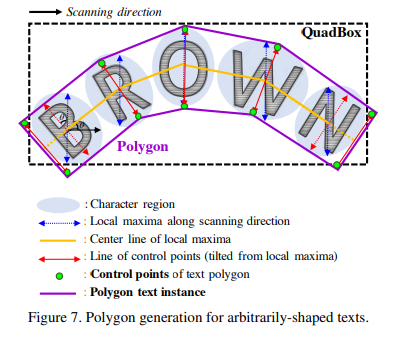
1) scanning direction을 따라 local maxima line (파란색 선)을 찾음
2) 최종 polygon 결과가 울퉁불퉁해지는 것을 막기 위해 local maxima의 길이는 local maxima중에 제일 긴 길이로 동일하게 설정
3) local maxima의 중심을 이어 center line(노란색 선)을 찾음
4) local maxima line 이 중심선에 수직이 되도록 회전하여 문자의 기울기 각도를 반영 (빨간색 선)
5) local maxima line의 endpoint는 text polygon control points의 후보
6) 두 개의 가장 바깥쪽으로 기울어진 Local maxima line을 Center line을 따라 바깥쪽으로 이동하여 최종 Control point를 결정한다.(텍스트 영역을 완전히 커버하기 위함)
CRAFT의 장점 : nms와 같은 후처리 필요없음
Experiment
<데이터 셋>
ICDAR2013, 2015, 2017, MSRA-TD500, Total Text, CTW-1500
<학습 전략>
Synth Text dataset 사용
ADAM optimizer
During fine-tuning, the SynthText dataset is also used at a rate of 1:5 to make sure that the character regions are surely separated.
In order to filter out texture-like texts in natural scenes, On-line Hard Negative Mining [32] is applied at a ratio of 1:3.
basic data augmentation techniques like crops, rotations, and/or color variations are applied
Weakly-supervised training 을 위한 두가지 데이터
-- quadrilateral annotations for cropping word images
-- transcriptions for calculating word length
를 만족하는 데이터셋 : IC13, IC15, IC17 이기 때문에 CRAFT를 ICDAR 데이터로만 학습함
Conclusion
character-level annotation이 주어지지 않았을 때 각 character를 detect하는 text detecter CRAFT 제안.
region score와 affinity score를 통해 bottom-up 방식으로 다양한 모양의 text 탐지 .
interim model 이 pseudo GT를 생성하여 weakly - suprervised learning
SOTA 달성으로 fine-tunning 없이 일반화 성능을 증명함
ref
craft paper review
