config 변경 및 학습
Custom dataset을 만들었으면 이제 config를 설정하고 학습을 시키면 됩니다.
### Config 설정하고 Pretrained 모델 다운로드
config_file = '/opt/ml/detection/mmdetection/configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'
checkpoint_file = '/opt/ml/detection/mmdetection/checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
from mmcv import Config
cfg = Config.fromfile(config_file)
print(cfg.pretty_text)Config.fromfile(config_file)로 config를 가져오는데, 이를 열어보면 다음과 같습니다.
_base_ = [
'../_base_/models/faster_rcnn_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]이는 base 에 있는 model, dataset, scheduler, base_runtime config가 합쳐진 것임을 알수 있습니다. 따라서 출력하면 4가지의 config가 모두 출력되는 것입니다.
config 대분류
-
dataset
dataset의 type(CustomDataset, CocoDataset등), train/val/test Dataset 유형, data_root,
train/val/test Dataset의 주요 파라미터 설정(type, ann_file, img_prefix, pipeline 등) -
model
Object Detection Model 의 backbone, neck, dense head, roi extractor, roi head 주요 영역별로 세부 설정. -
schedule
optimizer 유형 설정(SGD, Adam, Rmsprop등), 최초 learning 설정
학습 중 동적 Learning rate 적용 정책 설정( step, cyclic, CosineAnnealing등)
train 시 epochs 횟수 -
run time
주로 hook(callback)관련 설정.
학습 중 checkpoint 파일, log 파일 생성을 위한 interval epochs수
/base/ 에 들어가 해당 confug파일을 하나씩 살펴보면 다음과 같습니다.
datasets/coco_detection.py
img_norm_cfg = dict(
# rgb로 먼저 변환후 normalization / framework caffe인 경우 bgr그대로 하기도 함
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_train2017.json',
img_prefix=data_root + 'train2017/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline))
evaluation = dict(interval=1, metric='bbox')fast_rcnn_r50_fpn.py
# model settings
model = dict(
type='FastRCNN',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),
roi_head=dict(
type='StandardRoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=80,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
# model training and testing settings
train_cfg=dict(
rcnn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False)),
test_cfg=dict(
rcnn=dict(
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100)))schedule_1x.py
# optimizer
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
# learning policy
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[8, 11])
runner = dict(type='EpochBasedRunner', max_epochs=12)
default_runtime.py
checkpoint_config = dict(interval=1)
# yapf:disable
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook'),
# dict(type='TensorboardLoggerHook')
])
# yapf:enable
custom_hooks = [dict(type='NumClassCheckHook')]
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
다시 학습 코드로 돌아와서, 위에서 경로를 설정해준 뒤 config 파일을 불러옵니다.
from mmcv import Config
cfg = Config.fromfile(config_file)
print(cfg.pretty_text) # 위의 4가지 config가 모두 출력됨다음은 우리의 데이터셋에 맞게 config를 수정하면 됩니다.
from mmdet.apis import set_random_seed
# dataset에 대한 환경 파라미터 수정.
cfg.dataset_type = 'KittyTinyDataset'
cfg.data_root = './kitti_tiny/'
# train, val, test dataset에 대한 type, data_root, ann_file, img_prefix 환경 파라미터 수정.
cfg.data.train.type = 'KittyTinyDataset'
cfg.data.train.data_root = './kitti_tiny/'
cfg.data.train.ann_file = 'train.txt'
cfg.data.train.img_prefix = 'training/image_2'
cfg.data.val.type = 'KittyTinyDataset'
cfg.data.val.data_root = './kitti_tiny/'
cfg.data.val.ann_file = 'val.txt'
cfg.data.val.img_prefix = 'training/image_2'
cfg.data.test.type = 'KittyTinyDataset'
cfg.data.test.data_root = './kitti_tiny/'
cfg.data.test.ann_file = 'val.txt'
cfg.data.test.img_prefix = 'training/image_2'
# class의 갯수 수정.
cfg.model.roi_head.bbox_head.num_classes = 4
# pretrained 모델
cfg.load_from = 'checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
# 학습 weight 파일로 로그를 저장하기 위한 디렉토리 설정.
cfg.work_dir = './tutorial_exps'
# 학습율 변경 환경 파라미터 설정.
cfg.optimizer.lr = 0.02 / 8
cfg.lr_config.warmup = None
cfg.log_config.interval = 10
# config 수행 시마다 policy값이 없어지는 bug로 인하여 설정.
cfg.lr_config.policy = 'step'
# Change the evaluation metric since we use customized dataset.
cfg.evaluation.metric = 'mAP'
# We can set the evaluation interval to reduce the evaluation times
cfg.evaluation.interval = 12
# We can set the checkpoint saving interval to reduce the storage cost
cfg.checkpoint_config.interval = 12
# Set seed thus the results are more reproducible
cfg.seed = 0
set_random_seed(0, deterministic=False)
cfg.gpu_ids = range(1)
# We can initialize the logger for training and have a look
# at the final config used for training
print(f'Config:\n{cfg.pretty_text}') # 변경된 config 출력train용 dataset을 생성하고 학습을 진행합니다.
from mmdet.datasets import build_dataset
from mmdet.models import build_detector
from mmdet.apis import train_detector
# train용 Dataset 생성.
datasets = [build_dataset(cfg.data.train)]dataset을 출력해보면 다음과 같이 1차원 list안에 학습데이터에 대한 정보가 담겨있습니다.
50개의 학습데이터에 각 class에 해당하는 object가 총 몇개인지 출력합니다.

model을 생성하고 학습을 시키면 결과가 나옵니다.
model = build_detector(cfg.model, train_cfg=cfg.get('train_cfg'), test_cfg=cfg.get('test_cfg'))
model.CLASSES = datasets[0].CLASSES # ('Car', 'Truck', 'Pedestrian', 'Cyclist')
mmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))
# epochs는 config의 runner 파라미터로 지정됨. 기본 12회
train_detector(model, datasets, cfg, distributed=False, validate=True)
inference
from mmdet.apis import inference_detector, init_detector, show_result_pyplot
# BGR Image 사용
img = cv2.imread('./kitti_tiny/training/image_2/000068.jpeg')
model.cfg = cfg
result = inference_detector(model, img)
show_result_pyplot(model, img, result)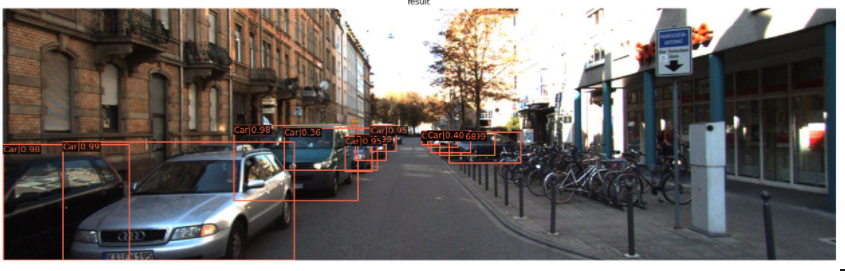
이렇게 해서 새로운 dataset의 format을 mmdetection에 맞게 바꾸어 학습과 infrence를 진행하면 됩니다. config에 대한 더 자세한 내용은 아래 Ref에 있는 공식문서를 참고하시면 됩니다.
Ref
https://mmdetection.readthedocs.io/en/latest/tutorials/config.html

안녕하세요 글이 많은 도움이 되었습니다~!!
한가지 궁금한점이 있는데
마지막 결과가 출력될때 출력양식을 따로 수정한 부분이 있으실까요???
혹은 어떤 스크립트를 수정하면 되는지 알고 계신지 궁금합니다!!!