Background
-
Instruction Tuning 이란
Instruction Tuning은 자연어 처리(NLP) 분야에서 사용되는 모델 훈련 방식 중 하나로, 모델이 특정 지시(instruction)를 따르는 방식으로 행동하도록 학습하는 과정입니다. 이 방법은 모델에게 명시적인 지시사항을 기반으로 특정 작업을 수행하도록 하는데 초점을 맞추며, 이를 통해 모델의 다양한 NLP 태스크에 대한 유연성과 적응성을 향상시킵니다.
-
Instruction Tuning의 핵심 포인트:
- 지시사항 기반 학습:
모델은 사람이 이해할 수 있는 자연어 지시사항을 받고, 이에 따라 적절한 반응을 생성하는 방식으로 학습됩니다. 예를 들어, "이 문장을 요약해라", "이 질문에 답해라"와 같은 지시를 받았을 때 모델이 해당 태스크를 수행하도록 합니다. - 다양한 태스크에 대한 일반화:
Instruction Tuning을 통해 학습된 모델은 하나의 모델로 다양한 NLP 태스크를 처리할 수 있게 됩니다. 즉, 태스크별로 별도의 모델을 학습시키는 대신, 하나의 모델이 다양한 지시사항을 이해하고 수행할 수 있습니다. - 효율성과 유연성 향상:
모델이 지시사항을 이해하고 수행하는 방식으로 학습함으로써, 새로운 태스크나 약간 다른 형식의 태스크에 대해 모델을 빠르게 적응시킬 수 있습니다.
- 지시사항 기반 학습:
-
Instruction Tuning의 예시:
OpenAI의 GPT-3와 같은 대규모 언어 모델은 다양한 지시사항에 기반한 태스크 수행 능력을 보여주며, 이는 Instruction Tuning과 유사한 방식으로 다양한 지시에 대응할 수 있는 능력을 모델에 부여합니다. 예를 들어, 사용자가 "이 이메일을 정중한 답장 형태로 요약해 줘"라고 지시할 경우, 모델은 이메일 내용을 요약하고 정중한 어조로 답장을 생성할 수 있습니다.
Instruction Tuning은 특히 다양한 형태의 입력과 요구사항에 대응할 수 있는 범용 NLP 모델을 개발하는 데 있어 중요한 접근 방식으로 자리잡고 있으며, 모델의 실용성과 활용 범위를 크게 넓히는 데 기여합니다.
-
-
이미지-텍스트 쌍 데이터와 instruction following 데이터의 차이
이미지-텍스트 쌍 데이터와 instruction following 데이터는 머신 러닝, 특히 자연어 처리(NLP)와 컴퓨터 비전 분야에서 사용되는 두 가지 다른 유형의 데이터입니다. 각각은 다른 목적과 구조를 가지고 있으며, AI 모델을 훈련시키기 위한 다른 종류의 정보를 제공합니다.
-
이미지-텍스트 쌍 데이터
이미지-텍스트 쌍 데이터는 각 이미지에 해당하는 설명이나 캡션을 포함하는 데이터셋입니다. 이러한 데이터셋은 주로 이미지 설명 생성(Image Captioning), 시각적 질문 응답(Visual Question Answering, VQA), 이미지 검색 및 자동 태깅 등의 작업에 사용됩니다. 목적은 모델이 이미지의 시각적 내용을 이해하고, 이를 토대로 관련 텍스트를 생성하거나, 주어진 텍스트 질문에 대해 이미지를 분석하여 답변하는 능력을 개발하는 것입니다.
-
Instruction Following 데이터
Instruction following 데이터는 AI 모델이 특정 지시사항이나 명령을 따르도록 하는 작업을 위해 설계된 데이터입니다. 이 데이터 유형은 모델에게 주어진 지시를 이해하고, 해당 지시에 따라 적절한 작업을 수행하도록 요구합니다. 이러한 작업에는 지시에 따른 이미지 생성, 지시에 기반한 텍스트 생성, 지시에 따른 행동 수행(로봇 제어 등) 등이 포함될 수 있습니다. 목적은 모델이 자연어로 된 지시사항을 이해하고, 이를 토대로 특정 작업을 수행하는 능력을 개발하는 것입니다.
-
차이점
- 용도와 목적:
이미지-텍스트 쌍 데이터는 주로 이미지의 내용을 기반으로 텍스트를 생성하는 작업에 사용되며, 모델이 시각적 정보를 어떻게 이해하고 언어로 표현하는지에 초점을 맞춥니다. 반면, instruction following 데이터는 모델이 주어진 지시사항을 이해하고, 그에 따른 적절한 작업을 수행하는 능력을 개발하는 데 사용됩니다. - 데이터 구조:
이미지-텍스트 쌍 데이터는 이미지와 이에 대응하는 텍스트(설명, 캡션 등)로 구성됩니다. instruction following 데이터는 지시사항(텍스트 형태)과 이를 수행하기 위한 정보(이미지, 텍스트, 또는 기타 형태)로 구성될 수 있습니다. - 응용 분야:
이미지-텍스트 쌍 데이터는 이미지 캡셔닝, 시각적 질문 응답 등의 시각-언어 작업에 주로 사용되며, instruction following 데이터는 자연어 이해, 로봇 제어, 생성적 작업 등 더 다양한 분야에 적용될 수 있습니다.
- 용도와 목적:
-
LLaMA
paper | code | demo | project page
Motivation
기존의 scaling low 법칙은 모델의 파라미터가 많을 수록 성능이 좋을 것이라는 가정하에 특정 training compute budget 내에서 dataset과 모델 크기를 scaling 했음
그러나 이런 연구는 inference budget은 고려하지 않았음.
inference compute budget을 고려했을 때, 가장 최고의 성능은 큰 모델에서 나오는게 아니라 작은 모델을 더 많은 데이터로 학습시켰을 때 였음 (Jordan Hoffmann, , 2022. Training compute-optimal large language models.)
따라서 논문의 목표는 일반적으로 사용되는 것보다 더 많은 토큰에 대해 훈련함으로써 다양한 inference budget에서 가능한 최상의 성능을 달성하는 일련의 언어 모델을 훈련하는 것.
Chinchilla, PaLM, GPT-3와 다르게 오픈 데이터만을 사용함
Takeaways
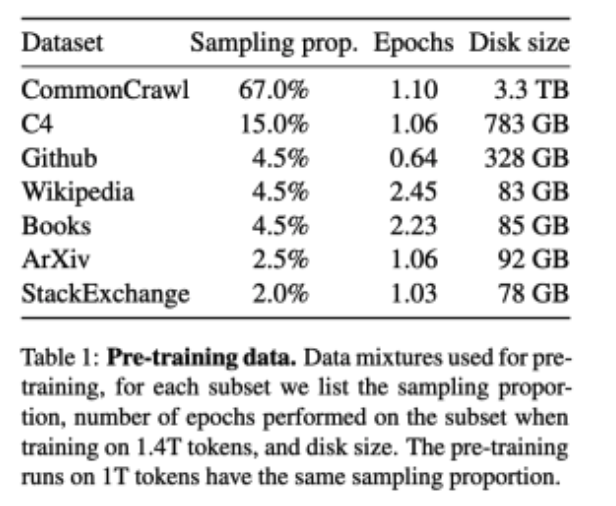
- Datasets
open dataset 활용
-
Tokenizer
byte-pair encoding (BPE) algorithmLLM에서 tokenizer의 역할
LLM(Long Language Models)에서 tokenizer는 텍스트 데이터를 모델이 처리할 수 있는 형태로 변환하는 역할을 합니다. 기본적으로, 대규모 언어 모델은 텍스트를 직접적으로 이해하거나 처리할 수 없기 때문에, 텍스트를 모델이 처리할 수 있는 숫자 형태로 변환하는 과정이 필요합니다. 이 과정을 토큰화(tokenization)라고 하며, 여기서 tokenizer는 이러한 변환 작업을 담당하는 구성 요소입니다.Tokenizer의 주요 역할:
텍스트 분할: Tokenizer는 주어진 텍스트를 작은 단위인 토큰(token)으로 분할합니다. 토큰은 단어, 서브워드(subword), 문자 등 다양한 형태가 될 수 있습니다. 이 과정에서 공백, 구두점 등을 기준으로 텍스트를 나누기도 하며, 보다 세분화된 단위로 나누기 위해 서브워드 토큰화 방법을 사용하기도 합니다.
토큰 인덱싱: 분할된 토큰을 모델이 이해할 수 있는 숫자로 변환하는 과정입니다. Tokenizer는 사전(vocabulary)을 사용하여 각 토큰에 고유한 숫자 ID를 할당합니다. 이 ID는 모델이 토큰의 의미를 학습하고 처리하는 데 사용됩니다.
텍스트 전처리: 토큰화 과정에서 텍스트를 정규화(소문자화, 불필요한 공백 제거 등)하고, 특수 토큰(시작 토큰, 종료 토큰 등)을 추가하는 등의 전처리 작업을 수행합니다. 이는 모델이 텍스트를 보다 효율적으로 처리하고, 문맥을 올바르게 이해하는 데 도움을 줍니다.
입력 형식 준비: LLM은 특정 길이의 입력을 요구하기 때문에, tokenizer는 텍스트를 모델의 입력 길이에 맞게 조정합니다. 이는 텍스트를 잘라내거나(padding) 필요한 경우 패딩(padding)을 추가하여 입력 길이를 조정합니다.
Tokenizer는 LLM을 포함한 다양한 NLP 모델에서 필수적인 구성 요소로, 텍스트 데이터를 모델이 이해하고 학습할 수 있는 형식으로 변환하는 핵심적인 역할을 합니다.
BPE란 ?
BPE(Byte Pair Encoding)는 자연어 처리(NLP) 분야에서 사용되는 토큰화(tokenization) 방법 중 하나로, 특히 서브워드(subword) 토큰화에 사용됩니다. BPE의 핵심 아이디어는 말뭉치(corpus) 내에서 가장 빈번하게 등장하는 바이트 쌍(byte pairs) 또는 문자 쌍을 반복적으로 병합하여, 빈도수가 높은 문자열을 하나의 새로운 토큰으로 만드는 것입니다. 이 방법은 초기에 데이터 압축 분야에서 사용되었지만, 나중에 NLP에서 효율적인 토큰화 방법으로 널리 채택되었습니다.
BPE 토큰화 과정:
초기 사전 구축: 모든 단어를 문자의 시퀀스로 분해하고, 각 단어의 끝에 특수 문자(예: )를 추가하여 단어의 경계를 명시합니다. 이때, 모든 문자(또는 바이트)를 초기 토큰으로 간주하고, 각 토큰의 빈도수를 계산합니다.
가장 빈번한 쌍 병합: 말뭉치 전체에서 가장 자주 등장하는 인접한 토큰(문자 또는 문자열) 쌍을 찾아 하나의 토큰으로 병합합니다. 이 과정은 미리 정한 횟수만큼 또는 사전의 크기가 특정 크기에 도달할 때까지 반복됩니다.
사전 업데이트: 병합된 새 토큰을 사전에 추가하고, 다음 반복에서 사용할 수 있도록 합니다.
토큰화: 학습된 BPE 사전을 사용하여 새로운 텍스트를 토큰화합니다. 이때, 사전에 있는 가장 긴 문자열부터 매칭하여 토큰으로 분리합니다.
BPE의 장점:
OOV(Out-Of-Vocabulary) 문제 완화: BPE는 단어를 서브워드 단위로 분해할 수 있기 때문에, 학습 데이터에 없는 새로운 단어가 등장해도 서브워드 단위로 처리할 수 있어 OOV 문제를 효과적으로 줄일 수 있습니다.
효율적인 어휘 관리: BPE는 빈도수가 높은 서브워드를 동적으로 선택하기 때문에, 모델이 처리해야 할 어휘의 크기를 효율적으로 관리할 수 있습니다.
언어의 형태학적 정보 포착: 서브워드 단위로 텍스트를 분해함으로써, 단어의 형태학적인 특성을 일정 부분 포착할 수 있으며, 이는 특히 유사한 형태를 가진 단어들 사이의 관계 학습에 도움을 줍니다.BPE는 GPT, BERT와 같은 현대의 대규모 언어 모델에서 널리 사용되는 토큰화 방법 중 하나로, 효율적인 텍스트 처리와 모델의 성능 향상에 기여하고 있습니다.
Overall, our entire training dataset contains roughly 1.4T tokens after tokenization
- Architecture
transformer 기반
다른 LLM논문에서 영감을 얻어 수정함, 영감을 얻은 논문은 [] 표시로 표시
Pre-normalization [GPT3]
training stability를 개선하기 위해 transformer sub-layer의 input을 normalize 함
Root Mean Square Layer Normalization(RMSNorm) 사용
http://dmqm.korea.ac.kr/activity/seminar/364
https://kwonkai.tistory.com/144
Batch Norm : mini batch 의 feature 별로 , channel 별로
Layer Norm : mini batch의 sample 별로
RMS Layer Norm :
motivation : RNN 계열 모델에서 Layer Norm 의 expensive computational cost
how
LN의 역할 두가지
re-centering invariance : enables the model to be insensitive to shift noises on both inputs and weights (입력과 가중치 모두에서 shift noise에 둔감할 수 있도록)
re-scaling invariance : keeps the output representations intact when both inputs and weights are randomly scaled (입력과 가중치가 무작위로 scale 될 때 output 출력을 그대로 유지)
LN의 성공요인은 re-scaling invariance 가 더 큰 역할을 했다고 봄, 이유는 안읽어봄
그래서 summed input을 RMS로 나누어 normalize 함
평균 빼는 건 없앴는데 그래도 괜찮다고 함
contribution
Extensive experiments on several tasks using diverse network architectures show that RMSNorm achieves comparable performance against LayerNorm but reduces the running time by 7%∼64% on different models.


-
SwiGLU activation function [PaLM]
non-linearity by the SwiGLU activation function
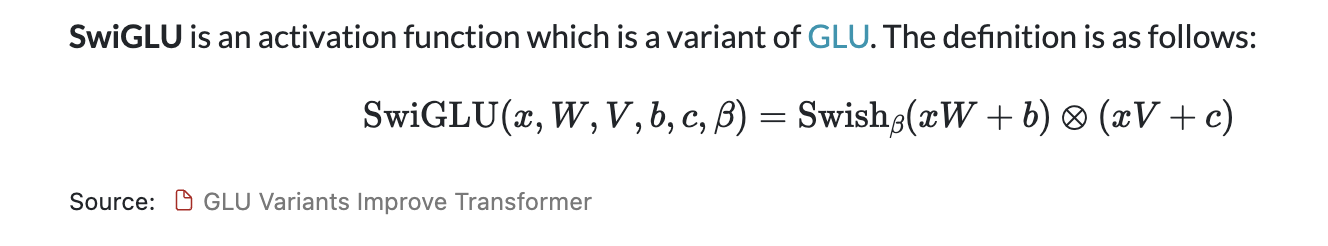
Paper : https://arxiv.org/pdf/2002.05202v1.pdf
PaLM 에서 사용한 4d 대신 2/3 4d 사용
-
Rotary Embeddings [GPTNeo]
absolute positional embeddings을 제거하고 대신 rotary positional embeddings (RoPE) 사용
Absolute Positional Embeddings과 Rotary Positional Embeddings (RoPE)는 트랜스포머 모델에서 위치 정보를 다루는 두 가지 다른 접근 방식입니다. 트랜스포머 모델은 시퀀스 데이터를 처리할 때, 시퀀스 내 각 요소의 위치 정보가 중요한 역할을 합니다. 위치 정보는 모델이 단어의 순서와 문맥을 이해하는 데 도움을 주며, 이를 통해 더 정확한 언어 이해와 생성이 가능해집니다.
Absolute Positional Embeddings
Absolute Positional Embeddings는 트랜스포머 모델의 초기 버전에서 사용된 방식으로, 각 위치에 고유한 임베딩을 할당하여 위치 정보를 제공합니다. 이 임베딩은 입력 시퀀스의 각 토큰과 함께 모델에 입력되며, 모델이 시퀀스 내에서 각 토큰의 위치를 인식할 수 있도록 합니다.
이 방식의 단점은 고정된 길이의 위치 임베딩을 미리 정의해야 하기 때문에, 모델이 처리할 수 있는 최대 시퀀스 길이가 제한된다는 점입니다.
Rotary Positional Embeddings (RoPE)
RoPE는 상대적 위치 정보를 기반으로 하는 더 유연한 방식입니다. RoPE는 각 토큰의 위치 정보를 해당 토큰의 임베딩에 직접 회전(rotation)을 적용함으로써 인코딩합니다. 이 회전은 토큰 간의 상대적 위치 관계를 보존하며, 모델이 이러한 관계를 통해 시퀀스 내에서의 위치를 추론할 수 있게 합니다.
RoPE의 핵심 이점은 위치 임베딩이 입력 시퀀스와 별도로 학습되거나 저장될 필요가 없다는 것입니다. 대신, 위치에 따라 토큰 임베딩에 회전을 적용하여 위치 정보를 동적으로 표현합니다. 이 방식은 모델이 처리할 수 있는 시퀀스의 길이에 대한 제한을 완화하고, 더 긴 시퀀스에 대한 일반화 능력을 향상시킬 수 있습니다.
RoPE 사용의 장점
길이 제한 완화: 모델이 처리할 수 있는 시퀀스 길이에 대한 제약이 줄어듭니다.
동적 위치 정보: 시퀀스 내에서의 상대적 위치 정보를 효과적으로 모델링하여, 문맥 이해력을 강화할 수 있습니다.
유연성과 일반화: 다양한 길이의 시퀀스에 대해 모델이 더 잘 일반화할 수 있도록 돕습니다.RoPE는 특히 긴 문서나 대화, 혹은 시계열 데이터와 같이 긴 시퀀스를 처리해야 하는 경우에 유용하며, 트랜스포머 모델의 효율성과 유연성을 크게 향상시킬 수 있습니다.
- Optimizer
AdamW
We use a cosine learning rate schedule, such that the final learning rate is equal to 10% of the maxi- mal learning rate.
Efficient Optimization
activation checkpointing : backward pass 과정에서 recompute 되는 activation 을 줄임
Linear layer 의 output 처럼 계산 비용이 비싼 activation을 저장해놓음 (pytorch autograd를 사용하지 않고 transformer layer의 backward pass 직접 구현)
이 과정의 이익을 최대한으로 하기 위해 model and sequence parallelism 이 사용하는 메모리 사용량을 줄임
네트워크를 통한 computation of activations and the communication between GPUs (all_reduce operations로 인해)를 최대한 overlap.
65B 매개변수 모델을 훈련할 때 코드는 80GB의 RAM이 있는 2048 A100 GPU에서 약 380개의 token/sec/GPU를 처리
이는 1.4T 토큰이 포함된 데이터 세트를 통해 훈련하는 데 약 21일이 걸린다는 것을 의미
- Instruction Finetuning 파트
아주 적은 양의 fiuetuning 만으로도 massive multitask language understanding benchmark, or MMLU 에서 점수가 아주 잘나오는 것을 발견
- Instruction Finetuning 파트
Contribution
- 6.7B ~ 65.2B까지 다양한 크기의 LLM 제작
- LLaMA-13B outperforms GPT-3 while being more than 10× smaller, and LLaMA-65B is competitive with Chinchilla-70B and PaLM-540B.
(모델의 크기가 작아도 기존의 크기가 매우 큰 모델보다 더 좋은 성능을 낼 수 있음 을 보임 ) - publicly available data만 사용해도 sota 성능을 낼 수 있음을 보임
