Context-Aware Visual Compatibility Prediction(CVPR 2019)
Abstract
compatibility 예측시 visual feature뿐 아니라 context도 고려함 (context는 논문에서 정의)
context를 고려하여 gnn으로 product embedding 생성 → 다른 metric learning처럼 pairwise하게 비교하지 않는다.
fitb : 96.9 / comp : 0.99 로 SOTA 달성
Intro
-
Issue & Motivation
item들을 pairwise하게(독립적으로) 비교하면 최종적인 final prediction은 각 item을 독립적으로 비교한 후 모아놓은 것이다.
이 방법은 context를 고려하지 않기 때문에 주어진 clothing pair에 대해 항상 같은 예측을 하게된다.
Compatibility는 패션 감각과 트렌드가 변하면 함께 변하기 때문에 항상 같은 예측을 하는것은 문제가 있다. -
Solution & How
함께 입었을 때 어울리는 옷들에 대한 "context"를 정의하여 compatibility 예측시 visual feature와 context를 함께 고려하도록 했다.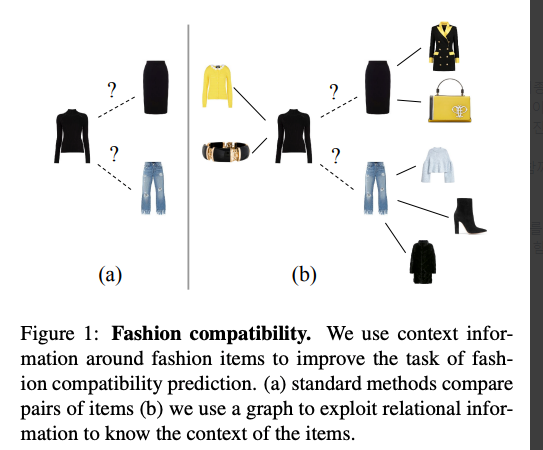
clothing item은 노드로, item들간의 compatibility 관계는 간선으로 해서 graph표현→ product embedding을 neighbors에 conditioning(?)함으로써 robust한 representation을 얻고 정확한 compatibility 예측 가능
proposed method
graph auto-encoder (GAE) :
encoder가 불완전한 그래프를 입력으로 받아서 각 node의 embedding을 생성한다.
생성된 embedding은 decoder가 그래프의 missing edge를 예측할 때 사용된다.
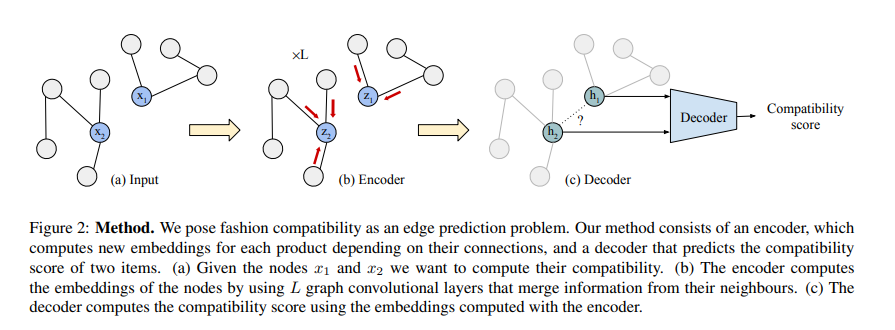
G = (V,E)를 undirected graph 라고 할 때 각 노드는 feature vector를 의미한다.
는 행렬(그래프의 모든 노드의 feature를 가진다)이다.
= 하나의 노드의 feature , ex) 은 i 번째 노드의 feature를 의미한다.
그래프는 의 인접행렬로 표현되며, 의 값이 1인 경우는 두 노드가 연결되어 있음을 뜻한다. (0일 경우 연결 안됨)
모델의 목표는 encoding function H = 와 decoding fucntion A = 를 학습하는 것이다.
인코더는 인접행렬 A를 참고하여 initial feature X를 새로운 표현인 H (Nx F') 행렬로 변환한다.
새로운 행렬은 초기 행렬 X와 똑같이 i번째 row가 i번째 노드의 정보를 가진다.
디코더는 인접행렬을 재구성하기 위해 새로운 representation H를 사용한다.
이 전체 과정을 input feature를 new space로 보내는 encoding으로 볼 수 있는데, 두 point간의 거리가 둘 사이에 edge가 있을지 없을지의 확률로 해석될 수 있다. 그리고 디코더가 각 노드의 feature를 활용하여 그 확률을 계산해서 item i,j 의 compatibility를 구한다.
이 때 인코더는 Graph Convolutional Network이며, 디코더는 pairs of products (i; j) 의 compatibility score를 예측하는 metric을 학습한다.
Encoder와 Decoder의 동작과정을 자세히 살펴보자.
- Encoder
the model computes item embeddings depending on their connections.
single node i의 입장에서 보면 인코더는 initial visual feature x를 h로 변환한다. CNN feature extractor에 의해 생성된 initial feature는 item이 어떻게 생겼는지-모양,색상,사이즈와 같은 vision informataion을 담고 있다. 하지만 논문에서는 product의 속성 뿐만 아니라 encoder에 의해 생생성된 다른 item들간의 호환성과 같은 구조적인 정보(structural information)도 필요하다. 즉 item 그 자체의 정보 + 해당 노드와 연결된 이웃노드들에 대한 정보가 필요하다. 후자는 인코더에 의해 생성되기 때문에 new representation이라고 칭한다.
따라서 Encoder는 특정 node h_i 주변에 있는 neighbourhood를 모으는(aggregate) 함수이다. 이 함수는 GCN(Graph Convolutional Network)으로 구현된다. GCN의 final value h_i는 GCN의 각 hidden layer에 의해 생성된 값의 composition이다.
- Paper capture

GCN은 위와 같은 Graph Convolution 연산을 여러번(Multi layer) 진행한다.: l번째 layer의 Hiddin state이며, (그래프 노드의 initial feature) 이다.
: A + I_N으로, 인접행렬(A)에 자기 자신으로의 연결(I_N)을 추가한 것이다.
: Dii = Aij 의 summation으로, 각 노드의 degree를 나타내는 대각행렬이다.
: l번째 layer의 학습가능한 parameter이다.
: 비선형 함수인 ReLU를 사용했다.
Context information 은 neighbourhood의 depth를 나타내는 parameter S에 의해 controll된다. s가 의미하는 바는 특정 노드에서 s개의 edge를 연결해서 갈 수 있는 노드가 있을 때 그 깊이를 s라고 한다.
논문에서는 바로 인접한 이웃의 정보만 사용하도록 S=1로 설정했다.
GCN은 인접행렬을 입력으로 이용하여 어떤노드들이 연결되어 있는지에 대한 정보를 직접적으로 이용하고, 이를 통해 product간의 context = 즉 compatibility 정보를 효과적으로 학습할 수 있다.
최종적으로 인접행렬 A에 적용되는 정규화 기법은 확률 p_drop을 사용하여 행렬 A의 일부 노드의 모든 incident edges(?)를 무작위로 제거한다.
이 기법의 목적은 두가지 인데,
(1) 그래프 구조에 약간의 변화를 주어 noise에 robust하도록 한다.
(2) 모델로 하여금 이웃이 없는 노드에 대해 잘 동작하도록 학습해서 low relational information 인 경우에도 robust하게 한다.
- Decoder
the decoder uses item embeddings from encoder to compute the compatibility between item pairs
Decoder는 두 노드가 연결될 확률을 계산하는 함수이다. metric learning 과 같이 두 item간의 silmilarity, compatibility를 학습하는게 목표.
metric learning에서의 일반적인 공식은 두개의 n차원 벡터사이의 거리를 뜻하는 함수를 학습한다. 마찬가지로 논문에서도 item pair 의 comaptibility를 학습하길 원했고, 함수의 outdit은 0,1 사이의 확률값이다.
두 노드 h_i,h_j 의 representation(encoder가 생성)이 주어지면, decoder는 두 노드가 연결될 확률 p를 계산한다.
절댓값을 쓰는 이유는 d(h_i, h_j) , d(h_j, h_i) 가 같도록 decoder를 symmetric하게 하기 위해서.
Training
학습과정은 다음과 같다.
1. 인접행렬 A의 edge를 무작위로 삭제하여 불완전한 인접행렬 A_hat을 얻는다. 삭제된 set of edge는 E+라고 표시하고 원해 연결되어 있던 edge이기 때문에 posotive edge라고 부른다.
2. set of negative edge E-(노드 (i,j)가 연결되어 있지 않음을 뜻함)를 무작위로 생성한다.
3. 모델은 E_train = (E+, E-) : positive, negative edges를 모두 학습한다.
4. 주어진 불완전한 인접행렬 A_hat 과 initial feature X 를 통해 디코더는 E_train에 정의된 edge를 예측한다. 모델은 예측된 edge와 GT edge 의 cross entropy loss를 minimize하도록 optimize 되는데, 이때 E+
는 1, E- 는 0 이 되도록 한다.
Compatibility 계산 알고리즘은 아래와 같다. 
Experiment
-
Tasks
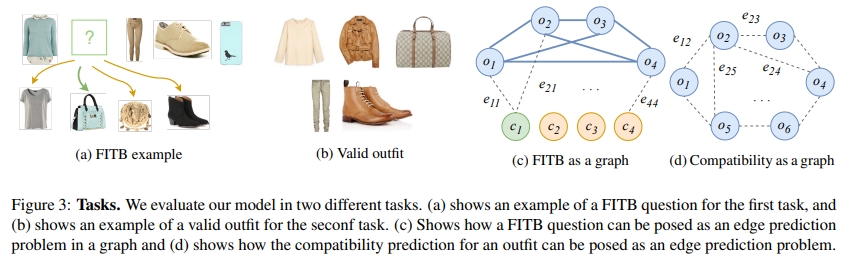
주어진 fashion outfit의 N개 set item을 로, 두 노드 i,j의 edge를 로 표기한다.-
FITB
(c) edge prediction : partial outfit question {c0, ... ,cM-1} , 모든 i, j 에 대해 모델이 item pairs (oi, cj)간의 확률을 예측한다. 각 j에 대한 score는 으로 계산되며, 가장 높은 score를 가지는 item이 fitb의 예측이다. -
Compatibility Predict
(d) edge prediction : 모델이 모든 가능한 item pair간의 모든 edge에 대해 확률을 예측한다. 이는 각 outfit에 대해 N(N-1)/2 번의 확률을 예측하는 것을 의미한다.
compatibility score는 : 모든 pairwise edge확률의 평균이다.
-
-
Evaluation by neighbourhood size
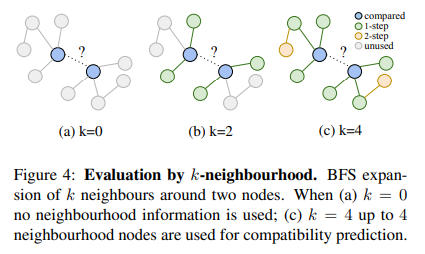
노드 i의 k-neighbourhood 를 i 부터 시작해서 BFS로 k번 이내에 방문할 수 있는 노드라고 해보자. 각 item 주변의 relational structure의 영향을 평가하기 위해 k를 바꿔가며 test했다.
k=0일 때(이웃 정보를 안쓸 때) 부터 늘려가면서 evaluation 했다. 학습때는 모든 가능한 edge를 사용했다.
Results & Conclusion
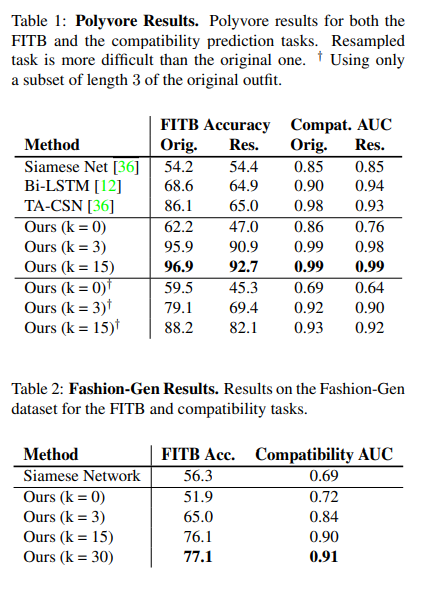 Polyvore 데이터를 사용했을 때는 k가 15일 때 이전 논문의 방법론에 비해 가장 높은 score를 달성했다.
Polyvore 데이터를 사용했을 때는 k가 15일 때 이전 논문의 방법론에 비해 가장 높은 score를 달성했다.
FashionGen 데이터를 사용했을 때도 k가 30일때 score가 가장 높다.
- Context matters
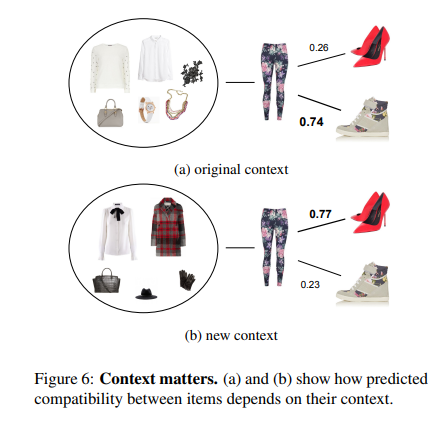
Context정보가 Compatibility 예측에 얼마나 중요한 영향을 미치는지 Polyvore 예시로 본다.
6(a) : original context if the trousers, 신발도 제대로 된걸로 뽑힘, 그런데 trousrs에 매칭되는 context를 다른 옷들로 바꿨을 때,
6(b) 처럼 다른 신발을 예측한다. 즉 논문에서 제안한 방법론으로 노드의 연결상태(context)가 바뀌면 예측 또한 바뀔 수 있다.
Take a home Message
fashion compatibility 예측분야에서 graph 모델을 통해 fashion item간의 관계를 표현하는 것이 compatibility 예측 성능에 도움이 된다.
Comment
해당 논문에서 제안한 방법론은 하나의 outfit을 구성하는 item들을 연결하여 그래프를 구성하고, 이 연결상태를 context로 사용한다.
따라서 노드의 연결이 많을수록, 즉 하나의 outfit을 구성하는 item이 다른 outfit에도 사용이 되는 중복현상이 많을수록 그래프가 표현하는 context가 풍부해지고, 그에 따라 predict 성능도 향상한다.
이는 데이터셋을 제작할 때부터 중복 item이 많아야 성능의 향상을 기대할 수 있다는 말이므로, 어떤 데이터를 사용하는지가 성능에 중요한 이슈이다.
또한 예측 시 모델이 참고하는 context의 hop을 조절하는 파라미터 k가 15정도로 상당히 큰데, 이 때 해당 그래프가 모두 메모리에 올라와 있어야 하므로 메모리도 충분히 확보되어야 한다.
