강의를 보면서 개인적으로 적고 싶은 부분만 적어보았다 😄
교양
→ 여기에서 모델을 만들고
→ 여기에 업로드하면 블록코딩을 할 수 있다
댑악............ 재밌따 ㅎ
→ 이거 보면서 프로젝트 주제 찾아봐도 괜찮을 것 같다
교양 끝 직업 시작
아이디어를 현실화하려면 데이터가 필요하다!
데이터를 처리하는 방법 중에 하나가 머신 러닝!
복잡한 현실에서 관심사만 가져다가 단순한 데이터로 만들어야.. 통찰 가능!
이를 통해 현실을 변화시키는 일을 하는 것이 "데이터 산업"
- 데이터 과학은 데이터를 만들고, 만들어진 데이터를 이용 ⇒ 작가
- 데이터 공학은 데이터를 다루는 도구를 만들고, 도구를 관리 ⇒ 책의 출판, 도서관, etc.
- 이 둘은 구분되는 것처럼 보이지만, 사실은 하나! (한 쪽이 없으면 다른 한 쪽이 존재할 수 x)
독립변수 → 원인, 종속변수 → 결과
두 feature에 관계가 있을 때 - 상관관계
한 feature가 변하면 다른 한 feature가 변할 때 - 인과관계
상관관계 > 인과관계
완전 명언...
보다 보면 공부를 그만두고 싶은
생각이 드는 지점이 나타날 것입니다.
이런 감정이 드는 것은 인내심이 부족하기 때문이 아닙니다.
이 정도 공부면 충분하다는 뇌의 명령입니다.
우리의 뇌에는 어떤 행위의 경제성을 판단하는,
고도로 정교한 모델이 내장되어 있는 것 같습니다.
이 모델이 ‘지금 하고 있는 행위는 경제성이 없어’라고 결정하면
1차 경고로 지루함을 발송합니다.
시정이 안되면 2차 경고로 절망감을 발송합니다.
이 경고를 계속 묵살하면
뇌는 묵살당했던 행위의 그림자만 봐도
그 일을 피하기 위해서 몸부림을 치게 됩니다.
뇌를 이기는 장사는 없습니다.
뇌의 말을 경청하세요.
지루함이 감지되면 과감하게
이 수업의 졸업식이라고 할 수 있는
‘수업을 마치며' 챕터로 순간이동 하시면 됩니다.
미래에 언젠가 이 공부를
다시 할 수 있는 준비가 되었을 때
다시 찾아오면 됩니다.
수동적으로 포기하는 것이 아니라,
능동적으로 유보하는 전략을 취한다면,
그만두는 순간이 기쁜 졸업이 될 것입니다.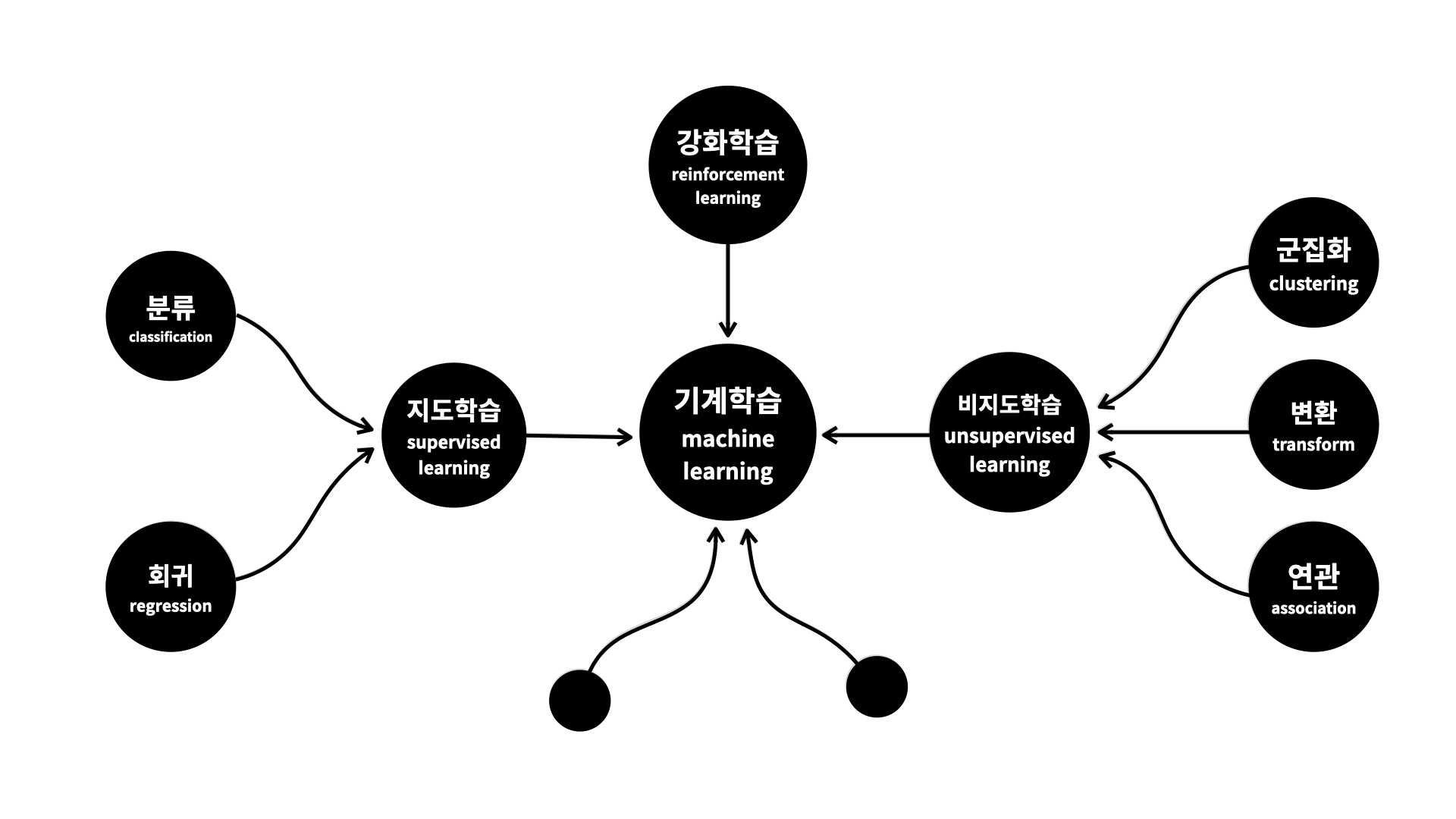
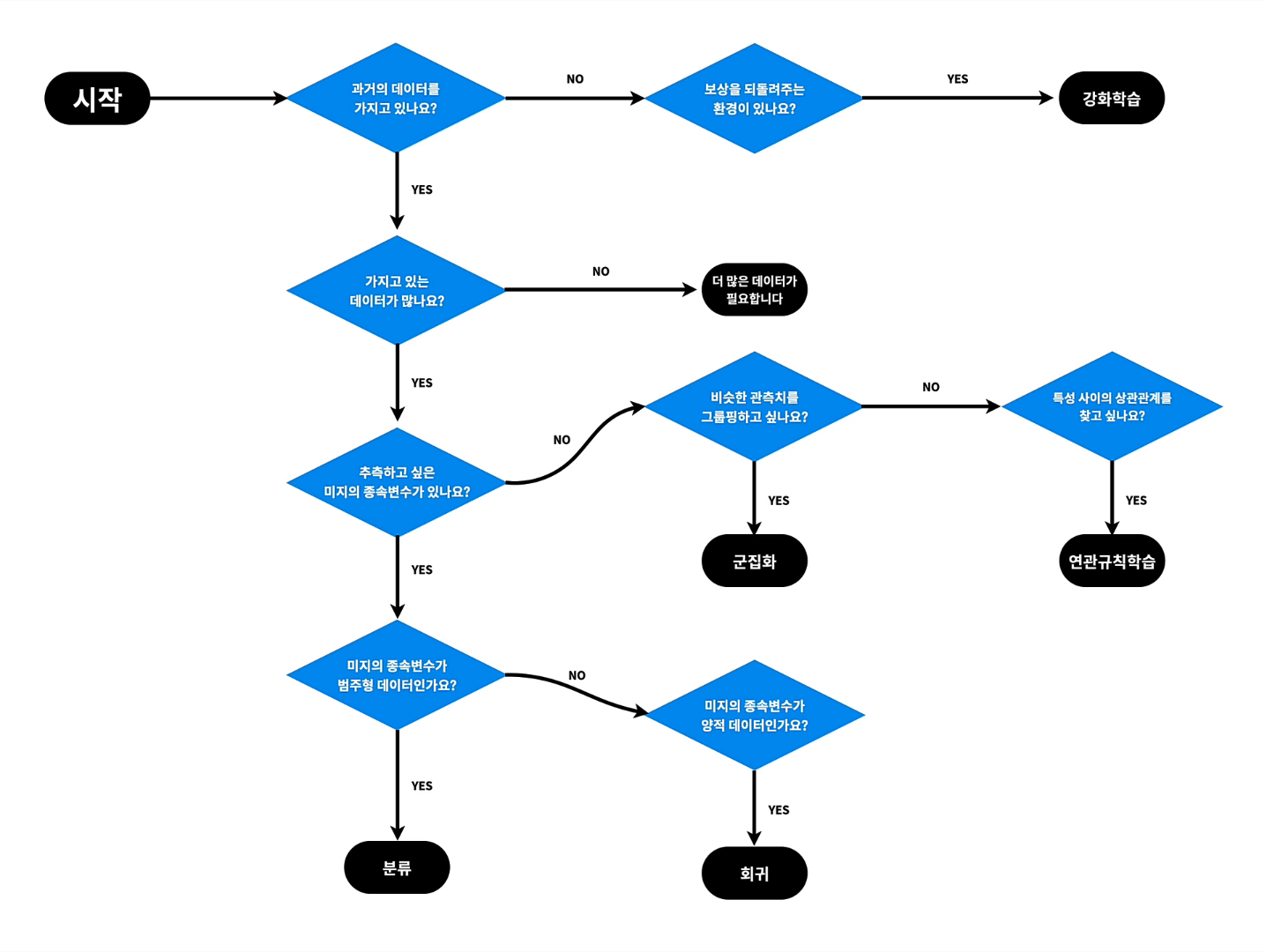
- 지도학습 : 기계를 가르치기 with 문제와 정답
- 비지도학습 : 기계에게 데이터에 대한 통찰력을 부여하기
- 강화학습 : 기계를 가르치기 without 정답 with 보상
지도학습
→ 과거의 데이터를 독립변수(원인)과 종속변수(결과)로 분리
→ 독립변수와 종속변수의 관계를 컴퓨터에게 학습시키기
→ 컴퓨터는 모델을 만들어낸다!
⇒ 그 모델로 미래의 데이터를 추측 가능!
회귀 Regression
→ 보통 예측하고 싶은 종속 변수가 숫자일 때 사용
→ 양적(Quantitative) 데이터
분류 Classification
→ 보통 예측하고 싶은 종속 변수가 이름/문자일 때 사용
→ 범주(Categorical)형 데이터
비지도학습
데이터의 성격을 파악하는 것이 목적. 즉, 그룹핑!
(독립/종속변수 구분 x)
군집화 Clustering
→ 비슷한 행을 그룹핑하는 것
cf) 분류: 어떤 그룹에 속하는지 판단!
연관규칙학습 Association
→ 서로 관련이 있는 특성(열)을 찾는 것
ex) 고객의 장바구니를 보고 살 가능성이 높은 상품 추천
변환 Transformation
→ 데이터를 새롭게 표현하는 것 ex) GAN
→ Dimensionality Reduction 특성 추출 (꼭 필요한 특성만 남기고 수 줄이기) ex) 텍스트에서 주제 추출
→ 데이터 전처리 (다른 머신러닝 알고리즘이 더 쉽게 해석할 수 있도록)
Ref. https://dev-jm.tistory.com/31
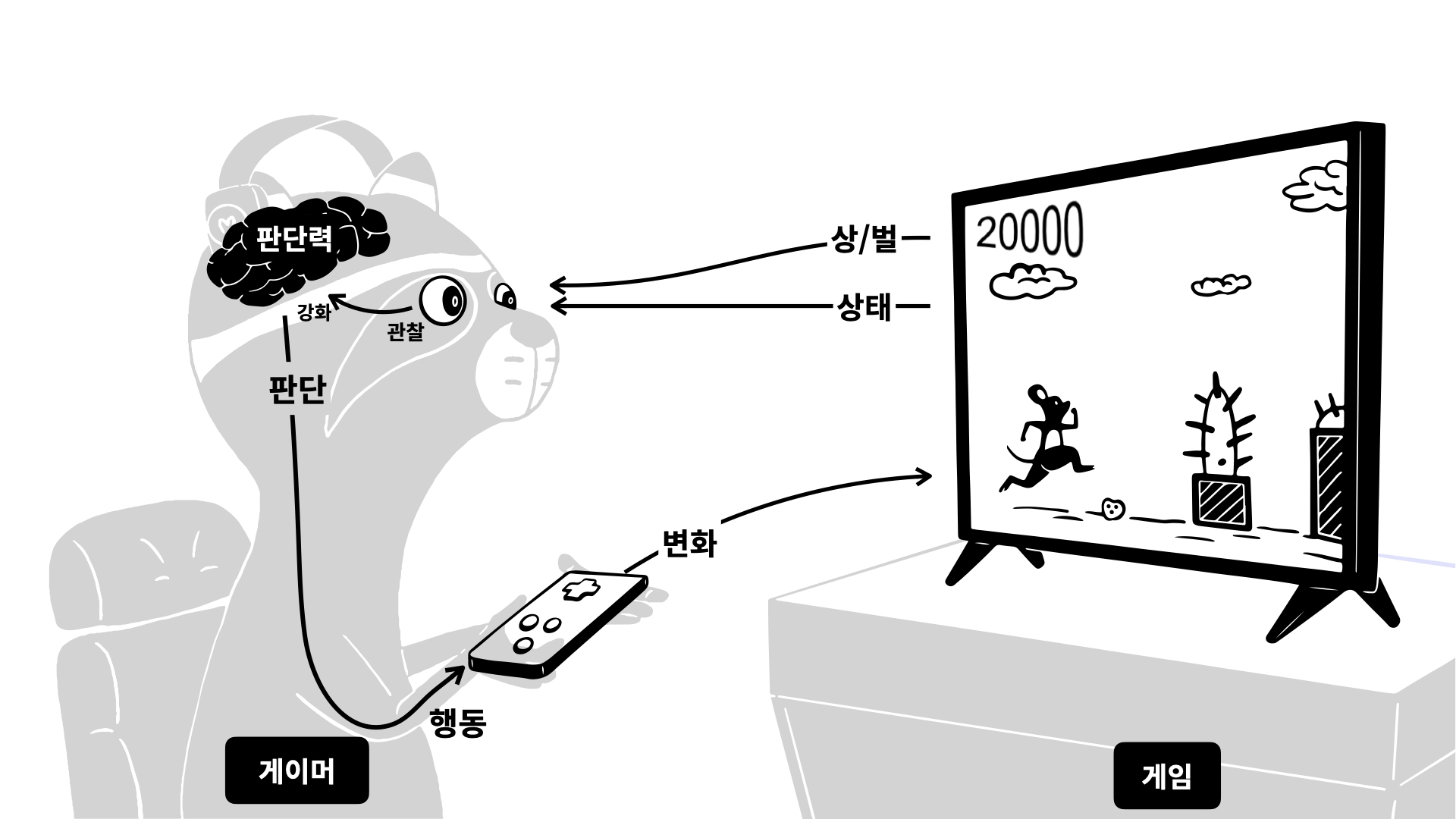
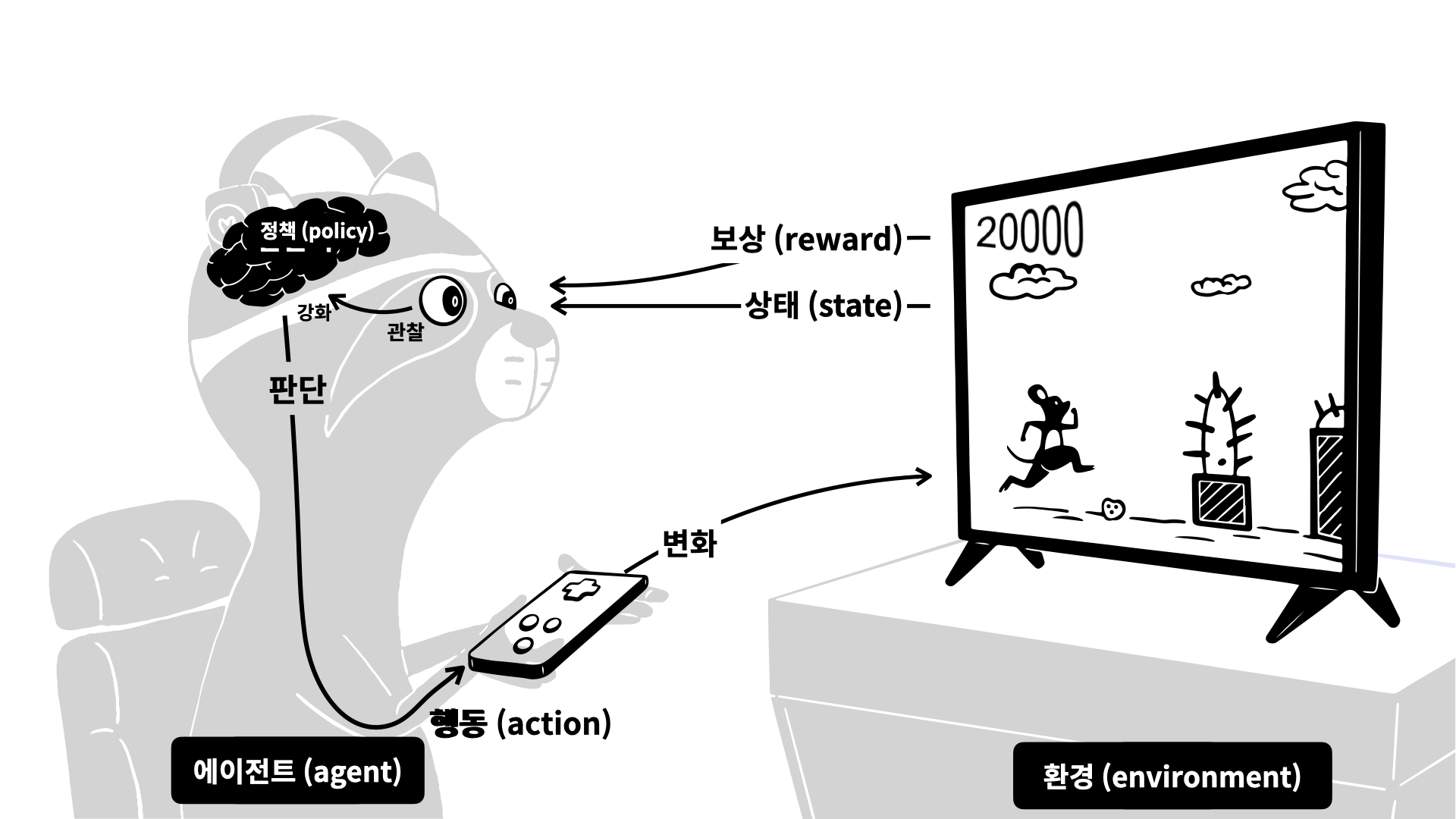
강화학습
→ 일단 해보면서 경험을 통해 실력을 키워나가기... ^^ like 게임 실력 키우기
머신러닝 지도
특별한 전공지식 없이 개념 잡기? 에 좋았다.
가볍게 쭉 보기에도 부담스럽지 않았고!
인공지능을 대강 알고는 있었지만,
정리되지 않고 머릿속을 둥둥 떠다니던 내용들이
뭔가 정리된 기분? 😆
오픈튜토리얼스 언제나 감사합니다 🙏
