
영속성 컨텍스트
Persistence Context
Spring의 Bean을 로딩, 관리하는 일은 Spring context에서 일어난다.
Persistence는 사라지지 않고 지속적인 데이터를 말한다.
데이터 영속성을 위해서는 DB에 저장하는 방법을 주로 사용한다.
Entity LifeCycle
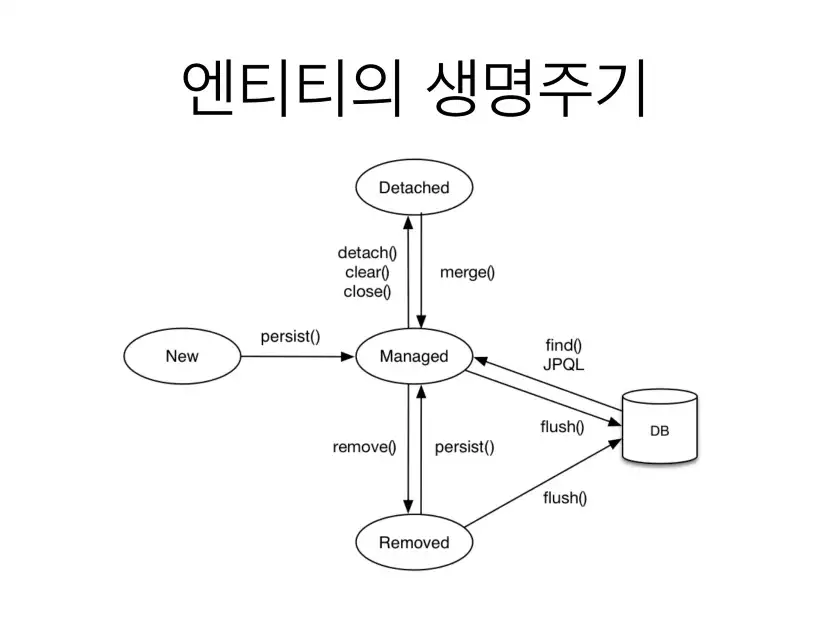
- 비영속 : 영속성 컨텍스트와 관계가 없는 새로운 상태 (DB에 저장되지 않는 상태)
- Entity를 관리하고 있는 상태 Duty check, 조회 쓰기 지연 등을 지원
- 영속(Managed) : 엔티티 매니저를 통해 엔티티가 영속성 컨텍스트에 저장되어 관리되고 있는 상태
- 준영속(Detached) : 영속성 컨텍스틍에서 관리되다가 분리된 상태
- 삭제(Removed)
: 영속성 컨텍스트에서 삭제된 상태
영속성 컨텍스트의 이점
- 1차 캐시 영속성 컨텍스트는 1차 캐시가 존재한다. 엔티티를 영속성 컨텍스트에 저장하는 순간 1차 캐시에 객체가 key, value 값으로 저장된다. 엔티티 매니저가 조회를 할 때 먼저 영속성 컨텍스트에 있는 1차 캐시에서 해당 엔티티를 찾고 엔티티가 존재할 경우 DB에 접근 하지 않고 반환한다.
- 동일성 보장 영속성 컨텍스트에서 꺼내온 객체는 동일성이 보장된다. 1차 캐시로 반복 가능한 읽기 등급의 트랜잭션 격리 수준을 데이터베이스가 아닌 애플리케이션 차원에서 제공한다.
- 트랜잭션을 지원하는 쓰기 지연 트랜잭션 내부에서 persist()가 일어날때, 엔티티를 1차 캐시에 저장하고, 쓰기 지연 SQL 저장소라는 곳에 INSERT QUERY를 생성해서 쌓아 놓는다. 이후 commit(), flush() 를 할 때 쓰기지연된 SQL QUERY를 DB에 보낸다.
- 변경 감지 JPA에서는 엔티티를 업데이트 할때 update(), persist() 와 같은 메소드로 영속성 컨텍스트에 알려주지 않아도 된다. 이것이 가능한 이유는 변경감지(Dirty Checking) 덕분이다.
- 플러시 플러시는 영속성 컨텍스트의 변경내용을 데이터베이스에 반영한다. 트랜잭션 커밋 시점에서 플러시가 발생하는데 이때 쓰기 지연 저장소에 쌓여 있는 SQL문을 데이터베이스에 전송한다.
DB 연결하기
- MySQL dependency 추가
runtimeOnly 'mysql:mysql-connector-java' - application.yml 에 db 경로를 추가 한다.
spring: sql: init: mode: always datasource: url: jdbc:mysql://127.0.0.1:3306/book_manager username: root password: *******
generate-ddl: true
generate-ddl은 jpa의 하위 속성이다. 즉 generate-ddl은 구현체와 상관없이 자동화된 db를 사용할 수 있도록 도와준다.
ddl-auto: create, create-drop, update, validate, none
- create : 기존 테이블 삭제 후 다시 생성 (drop + create)
- create-drop : create와 같으나 종료 시점에 테이블 drop
- update : 변경분만 반영
- validate : 엔티티와 테이블이 정상 매핑 되었는지만 확인
- none : 사용하지 않음
- 주의 사항
- 운영 장비에서는 create, create-drop, update 를 사용해서는 않된다.
- 개발 초기 : create, create-drop
- 테스트 서버 : update, validate
- 스테이징과 운영 서버 : validate, none
- 로컬 환경을 제외하고는 직접 쿼리 명령을 하는 것이 좋다.
ddl-auto가 generate-ddl보다 우선순위가 위이며 ddl-auto가 설정되면 generate-ddl은 무시된다.
Entity Cache
Jpa는 EntityManager을 이용하여 작동 된다.
영속성 캐시가 flush가 되는 시점
- flush 메소드를 명시적으로 호출하는 시점
- 트랜잭션이 끝나서 commit이 수행되는 시점
- 복잡한 조회의 조건에서 JPA 쿼리가 실행되는 시점
Entity Cache Test code
- Test 1
@Test void entityManagerTest(){ System.out.println(entityManager.createQuery("select m from Member m").getResultList()); }- Jpa query method는 entityManager을 통해서 실행 된다. 결과적으로 jpa의 findAll 과 같은 결과를 확인할 수 있다.
- EntityManager을 통해서 쿼리문을 더 빠르게 최적화할 수 있다.
- Test 2
@Test void findCache(){ // FEAT: Entity Cache 에 의하여 한 번만 select 문이 실행된다. 1차 캐시를 활용해 성능이 상승한다. System.out.println(memberRepository.findById(1L).get()); System.out.println(memberRepository.findById(1L).get()); System.out.println(memberRepository.findById(1L).get()); }- Entity Cache에 의하여 findById의 쿼리는 한번만 수행되게 된다.
- 쿼리 수행을 줄임으로써 성능을 향상 시킬 수 있다.
- 단, 키 값이 아닌 값에 대하여 조회시 entity cache를 유효하게 얻기 어렵다.
detach, clear, close 메서드 사용시에도 entity context에 들어간 메서드를 다시 꺼내게 되며 clear과 close는 datach보다 파괴적이다.
clear는 반영하려고 했던 것도 삭제된다.

같이 공부합시다~