
페이지네이션은 많은 양의 데이터를 사용자에게 효과적으로 보여주기 위해서 사용된다.
페이지네이션을 이용해서 데이터를 보여주는 방식으로는 대표적으로 페이지네이션과 무한 스크롤 방식이 존재한다.
-
페이지네이션

-
무한 스크롤
페이지네이션을 구현하는 방식으로는 Offset 과 Cursor 방식이 있다.
Offset 페이지네이션
offset 페이지네이션은 limit과 offset을 이용하여 페이지네이션을 구현한다.
SELECT *
FROM POST
WHERE memberId = :memberId
ORDER BY Id
LIMIT :offset, :size오프셋 기반의 방식은 마지막 페이지를 구하기 위해서 전체 갯수를 알아야 한다. 또한 offset을 사용하는 과정에서 불필요한 데이터 조회가 발생하게 된다.
Offset 조회 예시
public Page<Post> findAllMemberId(Long memberId, Pageable pageable) {
MapSqlParameterSource params = new MapSqlParameterSource()
.addValue("memberId", memberId)
.addValue("size", pageable.getPageSize())
.addValue("offset", pageable.getOffset());
var sql = String.format("""
SELECT *
FROM %s
WHERE memberId = :memberId
ORDER BY %s
LIMIT :size
OFFSET :offset""", TABLE, PageHelper.orderBy(pageable.getSort()));
List<Post> result = namedParameterJdbcTemplate.query(sql, params, POST_ROW_MAPPER);
return new PageImpl<>(result, pageable, getCount(memberId));
}
// 전체 포스트의 개수를 알아내기 위한 함
private Long getCount(Long memberId) {
var sql = String.format("""
SELECT count(*)
FROM %s
WHERE memberId = :memberId
""", TABLE);
var param = new MapSqlParameterSource()
.addValue("memberId", memberId);
return namedParameterJdbcTemplate.queryForObject(sql, param, Long.class);
}
// Order By 를 사용하기 위해서 Pageable의 Sort로 부터 정렬 기준 추출
public class PageHelper {
public static String orderBy(Sort sort){
// 정렬 기준이 없는 경우
if (sort.isEmpty()){
return "id DESC";
}
List<Sort.Order> orders = sort.toList();
// 정렬 기준이 있는 경우 ','를 이용하여 join
List<String> orderBys = orders.stream().map(order -> order.getProperty() + " " + order.getDirection())
.collect(Collectors.toList());
return String.join(", ", orderBys);
}
}Cursor 페이지네이션
Cursor은 데이터의 유일무이한 컬럼(ex: PK)를 이용하여 데이터를 조회할 수 있다.
단, 조회를 위해서는 반드시 정렬을 하여 진행하여야만 한다.
- PageReadService
public PageCursor<Post> getPosts(Long memberId, CursorRequest cursorRequest) { var posts = findAllBy(memberId, cursorRequest); var nextKey = posts.stream().mapToLong(Post::getId).min().orElse(CursorRequest.NONE_KEY); return new PageCursor<>(cursorRequest.next(nextKey), posts); }- 다음 페이지 조회를 위해서 조회된 posts중 가장 마지막 id를 key로서 지정
- PageCursor Class
public record PageCursor<T> ( CursorRequest nextCursorRequest, List<T> body ) { }- 다음 페이지를 조회를 위한 key, size와 데이터를 반환
- CursorRequest Class
public record CursorRequest( Long key, int size ) { public static final Long NONE_KEY = -1L; // End Data public CursorRequest next(Long key) { return new CursorRequest(key, size); } public boolean hasKey() { return key != null; } }- NONE_KEY는 더 이상의 데이터가 없음을 의미
- Post 조회 Repository
해당하는 회원에 대한 post 조회public List<Post> findAllByLessThanIdAndMemberIdAndOrderByIdDesc(Long id, Long memberId, int size) { var sql = String.format(""" SELECT * FROM %s WHERE memberId = :memberId and id < :id ORDER BY id desc LIMIT :size """, TABLE); var params = new MapSqlParameterSource() .addValue("id", id) .addValue("memberId", memberId) .addValue("size", size); return namedParameterJdbcTemplate.query(sql, params, POST_ROW_MAPPER); }
Offset, Cursor Tip!
-
Offset 기반 페이징의 경우 조회 이후 데이터가 추가되면 다음 페이지에서도 중복해서 데이터가 보일 수 있다.
-
Cursor 기반의 경우 Offset과 달리 id 정렬을 이용하여 조회하므로 데이터가 중간에 추가 되더라도 중복해서 데이터가 보이지 않는다.
-
Cursor 기반의 경우 검색하고자 하는 컬럼을 기반으로 정렬이 이루어져야 한다.
-
Cursor 기반 페이징은 키를 기준으로 데이터 탐색범위를 최소화 할 수 있다.
-
Offset 기반의 경우 전체 데이터의 개수를 조회해야 하는 단점이 있지만

전체 개수를 알지 못하므로 아래와 같은 UI 구현이 어렵다. 대신 무한 스크롤 방식 또는 더보기 버튼 UI를 사용해 볼 수 있다.
커버링 인덱스
검색조건이 인덱스에 부합하다면, 테이블에 접근 하는 것보다 인덱스를 통해 접근하는 것이 매우 빠르다.
예를 들어 30세 미만 회원들의 나이를 알고 싶을 경우
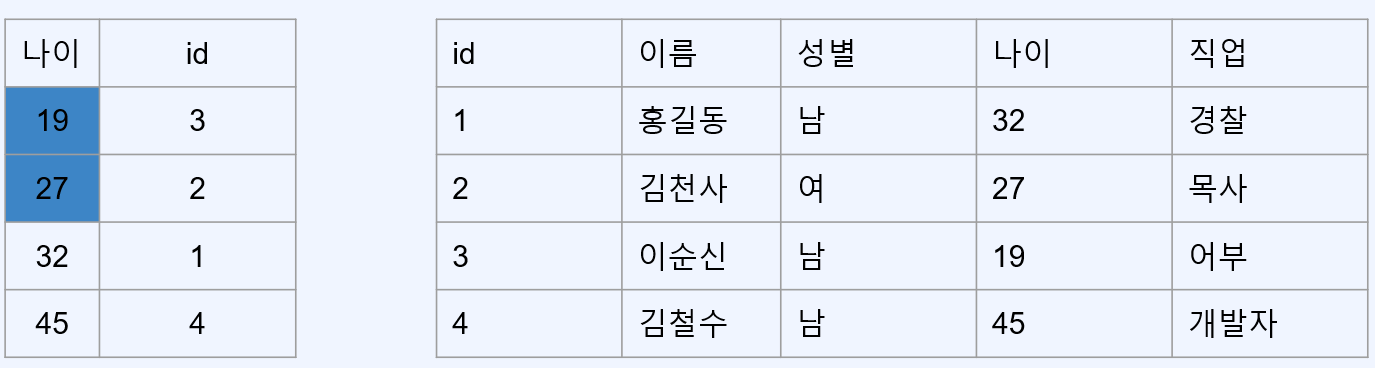
위와 같이 인덱스와 데이터가 있다면 인덱스 테이블만을 보고 19, 27세의 회원이 있다는 것을 알 수 있다.
MySQL에서는 PK가 클러스터 인덱스이기 때문에 커버링 인덱스에 유리하다.
커버링 인덱스를 사용하면 order by, offset, limit절로 인한 불필요한 데이터블록 접근을 최소화 할 수 있다.
커버링 인덱스 사용 예시
나이가 30 이하인 회원의 이름 2개만 조회
with Covering as (
SELECT id
FROM 회원
WHERE 나이 < 30
LIMIT 2
)
SELECT 이름
FROM 회원 INNER JOIN Covering on 회원.id = Covering.idwith절을 사용해서 커버링 인덱스 조회 쿼리 생성 및 조건에 해당하는 id를 조회- 조회된 id에 해당하는 데이터의 이름만
JOIN을 이용하여 조회
