오늘의 목표
- 수도코드
- 시간복잡도
- 탐욕 알고리즘(Greedy)
- 완전탐색(Brute-Force)
- 이진탐색(BinarySearch)
내용
수도코드
수도코드(의사코드)는 실제 소스코드를 작성하기전에 자연어나 자연어와 프로그래밍 언어를 섞은 언어를 먼저 로직에 따라 작성해 보는 코드를 의미합니다. 딱히 정해진 문법은 없지만 논리 문제를 풀듯이 컴퓨팅적 사고 과정을 적는 것이 좋습니다.
수도코드의 장점
- 시간 단축 : 수도코드를 작성하는 것은 언 뜻 바로 소스코드를 작성하는 것보다 시간이 더 걸릴 수 있는 것처럼 보입니다. 하지만 내용이 방대해지거나 구조가 복잡해지는 코드를 작성시 작성해 두었던, 또 생각해두었던 코드나 로직을 잊을 수 있습니다. 미리 작성해두면 해매이지 않아도 되니 헤메는 시간이 줄어들 것입니다.
- 디버깅 용이 : 작성한 코드가 처음부터 에러 없이 잘 작동할 수 도 있지만 극히 드문 경우이고 보통 작성 후 디버깅 과정을 수행해야 할 것입니다. 디버깅 시 작성해 두었던 코드를 따라가며 에러가 난 부분을 찾아야 합니다. 이때 미리 작성해 두었던 수도코드를 참고하면 큰 도움이 됩니다.
- 비전문가와 소통 : 프로그래밍 언어를 개발자는 보고 이해할 수 있지만, 개발자가 아닌 사람은 프로그래밍 언어를 보고 이해하기 어려울 것입니다. 이럴 때 수도코드를 활용해 사람이 읽고 이해하기 쉬운 언어로 작성해 로직을 설명한다면 비 전문가와도 의사소통이 가능할 것입니다.
라면을 끓인다고 예를 들때 사람에게 설명을 하면
// 라면을 꺼낸다
// 물을 끓인다
// 면과 스프를 넣는다
// 마저 끓인다.로 설명할 수 있지만 사람이 아닌 컴퓨터에게 처음부터 모든것을 명령해야한다면
// 서랍에서 라면을 꺼낸다.
// 라면 봉지를 뜯어서 면과 스프 후레이크를 꺼낸다
// 냄비에 물 500ml를 넣고 100도로 5분간 끓인다
// 면과 스프 후레이크를 차례대로 냄비에 넣는다
// 3분간 더 끓이고 불을 끈다.로 자세히 설명해야 합니다. 이럴 때 수도코드를 이요하여 각 로직마다 자연어로 자세히 설명한다면 개발하는 사람과 제3자 모두 이해하기 훨씬 용이할 것입니다.
시간복잡도
알고리즘 문제를 풀 때 가장 중요한 것은 문제에 대한 해답을 찾는 것입니다. 다만 개관식이나 단답식과는 다르게 알고리즘 문제는 보통 시작 부터 본인이 만든 코드로 input을 넣어 실행함으로써 output이 정답과 일치하게 나오는지 확인합니다.
정답을 찾는 것 다음으로 중요한 것이 효율성입니다. 얼마나 효율적으로 구현 하였는가라는 뜻입니다. 효율적으로 구현하였다는 뜻은 시간이 적게 걸렸다는 뜻과 일맥상통합니다.
즉, 효과적으로 문제 풀음 = 효율이 좋은 구현 = 시간이 적게 걸림입니다. 시간이 얼마나 걸렸는지 확인하는 지표가 시간 복잡도입니다.
입력값의 변화에 따라 연산을 실행할 때, 연산 횟수에 비해 시간이 얼마만큼 걸리는가?
입력값 수가 많아지면 당연히 연산 횟수가 증가 합니다. 입력값수 증가에 비례해서 연산 횟수가 얼마만큼 증가하냐에 따라 시간복잡도를 측정하게 됩니다.
| 표기법 | 설명 |
|---|---|
| Big-O(빅-오) | 이 정도 시간까지 걸릴 수 있다.(최악) |
| Big-Ω(빅-오메가 | 최소한 특정 시간 이상이 걸린다.(최선) |
| Big-θ(빅-세타) | 이정도 시간이 걸린다(평균) |
이 중에서 Big-O(빅-오)가 가장 많이 사용됩니다. 예상치 못한, 시간이 엄청 더 걸린 경우를 대비하기 위해 그런 시간이 엄청 더 걸리는 경우를 발생하지 않기 바라는 것 보단 시간 복잡도 계산시 그런 시간이 엄청 더 걸리는 경우를 미리 고려하여 계산 함으로써 어떤 경우에도 대처할 수 있게 하는것이 더 바람직 하기 때문입니다.
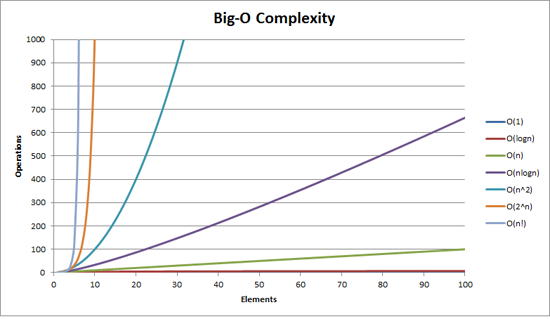
O(1): 입력값 변화에 상관없이 항상 일정한 시간이 걸리는 연산입니다. 보통 배열의 인덱스 참조시 배열의 길이가 무한정 늘어나도 인덱스 값 하나로 한번에 참조하는 경우입니다.O(N): 입력값 변화에 정비례하여 늘어난 만큼만 같은 비율로 늘어나는 연산입니다. 배열의 처음부터 끝까지 순회하는 for문이 대표적인 O(N)입니다.O(Log n): 입력값 변화에Log 2 n만큼만 증가하여 입력값이 무수히 많아질 경우 유리한 시간 복잡도 입니다. 예를들어 입력값이2^30 = 1073741824이지만 연산횟수는Log 2 2^30 = 30밖에 되지 않습니다.O(N^2): 입력값 변화에 제곱만큼 연산횟수가 늘어나는 시간복잡도 입니다.다중 for문에서의 시간복잡도이며 for문이 2중첩이면 N^2, 3중첩이면 N^3, m중첩이면 N^m입니다.O(N!): 입력값 변화에 팩토리얼로 N(N-1)(N-2)...321만큼 연산횟수가 늘어나는 시간 복잡도 입니다. 시간복잡도중 가장 기하급수적으로 연산횟수가 많이 늘어 납니다.
시간복잡도 연산시 변수앞의 상수나 계수는 생략합니다. 예를들어 하나의 FOR문의 시간 복잡도는 O(N)입니다. 2개의 FOR문이 각각 존재한다면 O(2N)으로 생각하실 수 있으나 시간복잡도 연산에서는 O(N)입니다. N의 수가 엄청나게 커진다면 계수의 영향력은 미미하기 때문에 생략합니다.
탐욕 알고리즘(Greedy)
Greedy는 탐욕 스러운, 욕심 많은 뜻을 가지고 있습니다. 와 닿지 않는다면 우리가 자주 인용하는 이야기를 하나 소개해 드리겠습니다.
마시멜로를 지금 먹으면 1개만 먹을 수 있지만 1분을 기다리면 1개 더 받아 2개를 먹을 수 있다.
Greedy 알고리즘은 탐욕 스럽고 욕심이 많아서 1분을 기다리지 않고 마시멜로를 바로 먹는 알고리즘입니다.
앞으로의 상황은 고려하지 않고 지금 현재 상태에서만 최적의 답을 선택합니다.
선택 절차(Selection Procedure): 현재 상태에서의 최적의 해답을 선택합니다.적절성 검사(Feasibility Check): 선택한 최적의 해답이 문제의 조건을 만족하는지 점검합니다.해답 검사(Solution Check): 만족하면 선택 절차 단계로 돌아가 다음 해답을 선택합니다.
Greedy 조건과 문제
Greedy로 문제를 해결할 수 있는 경우는 두가지 조건이 모두 충족되어야 가능합니다. 한가지라도 충족되지 못한다면 Greedy보단 동적 프로그래밍이나 완전 탐색 알고리즘등을 사용 하여야 합니다.
탐욕적 선택 속성(Greedy Choice Property): 이전의 선택이 이후의 선택의 영향을 주지 않습니다.최적 부분 구조(Optimal Substructure): 부분의 최적 방법들이 모여 문제의 최종 최적 방법을 구성합니다.
| 문제 | Greedy로 풀 수 있는 이유 |
|---|---|
| 동전 문제 | 우리가 사용하는 500원 100원 50원 10원은 모두 배수 관계에 있으므로 다음 선택에 영향을 주지 않는 선택을 할 수 있습니다 |
| 곱 또는 합 | 곱셈과 덧셈중 1이하는 덧셈, 2이상은 곱셈이 무조건적으로 더 큰 수로 연산할 수 있기 때문에 곱셈을 최대한 많이 하는 것이 최적 문제 해결 방법입니다. |
| 1로 가는 최소 연산 | 뺄셈과 나눗셈 중 나눗셈이 더 작은 수로 낮출 수 있으므로 나눗셈을 최대한 많이 하는것이 최적의 해결 방법입니다. |
| 모험가 수 | 모험가당 최소 그룹수기준으로 오름차순 정렬하면 최소 그룹수와 현재 그룹인원간 최소로 파티가 가능합니다. |
완전탐색(Brute-Force)
완전 탐색은 시행착오와 모든 값 대입입니다. 특정한 패턴이나 분석을 요구하지 않고 단순히 최솟값부터 최댓값까지 차례로 될 때 까지 실행하는 알고리즘입니다.
잠물쇠를 풀때 0000 부터 9999까지 +1씩 대입하며 비교해 보는 것, 배열내 최댓값을 찾기 위해 모든 요소들을 뒤져보는 것이 완전탐색의 대표적인 예시입니다.
완전탐색 알고리즘은 범용성이 좋지만 반대로 효율성이 좋지못합니다 여러 상황에서 사용 될 순 있으나 데이터의 범위가 커질 수록 상당히 비효율적이며 프로세스의 영향을 많이 받습니다
완전탐색 경우와 문제
완전 탐색(Brute Force Algorithm)은 크게 두가지 경우에 사용됩니다.
- 사용할 수 있는 다른 알고리즘이 존재하지 않을 때
- 여러 솔루션을 비교 분석시 확인할 때
| 문제 | 내용 |
|---|---|
| 순차 탐색 | 배열안의 특정값이 존재하는지 0번인덱스 부터 차례로 검색합니다 |
| 문자열 매칭 | 문자열 안의 특정 패턴이 존재하는지 맨 앞 문자 부터 차례로 비교합니다 |
| 선택정렬 | 0번 인덱스부터 차례로 현재요소보다 작으면서 최소인 값과 위치를 바꾸며 정렬합니다 |
| 체스 기사 | 2차원 배열에서 이동범위 중 이동이 가능한 위치인지 차례로 비교하며 갯수를 셉니다 |
| 시간내 특정 숫자 | 해당 숫자에서 시간,분,초를 각각 10의자리 1의자리로 특정 숫자가 있는 초를 세알립니다 |
이진탐색(BinarySearch)
이진 탐색은 중간의 값과 찾고자하는 값을 비교하며 절반 씩 줄여나가는 탐색입니다.
한단계가 지날 때 마다 절반씩 줄어드므로 시간복잡도는 O(logn)인 효율이 좋은 알고리즘이나, 정렬된 배열에서만 사용가능한 단점이 있습니다.
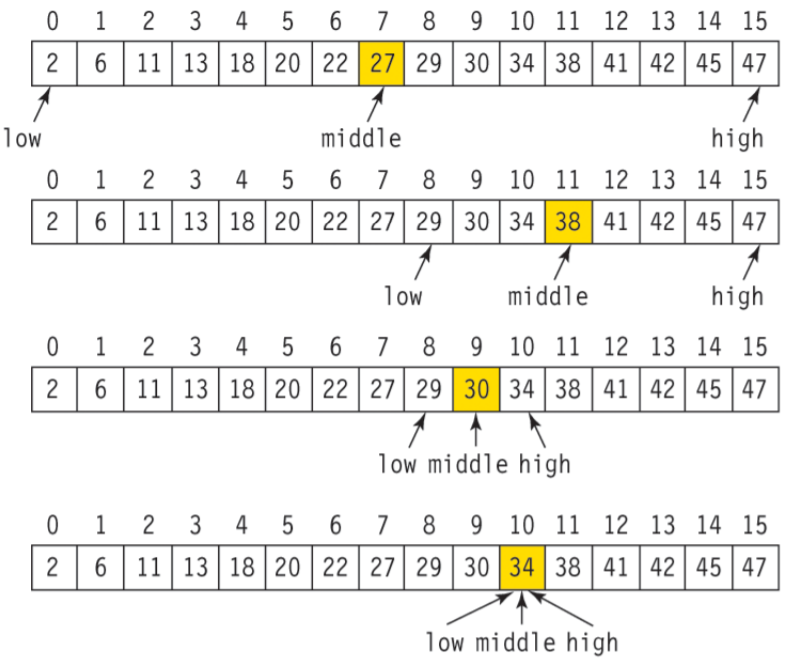
- 위치로 크기를 구분하기 때문에 배열은 사전에 정렬이 되어 있어야 합니다.
- 배열의 중간 인덱스의 값을 구합니다.
- 배열의 중간 인덱스의 값과 구하고자 하는 값이 동일한지 비교합니다.(동일시 종료)
- 동일하지 않다면 배열의 중간 인덱스의 값보다 구하고자 하는 값이 큰지 작은지 비교합니다.
- 값이 없는 부분을 버립니다.
- 값이 있는 부분에서 다시 1번부터 반복합니다.
이진탐색의 사용과 이진트리와의 관계
| 사용 | 설명 |
|---|---|
| 사전 검색 | 사전에서 단어를 찾을 때 사용 |
| 도서관 도서 검색 | 도서관에서 도서코드로 도서를 찾을 때 사용 |
| 대규모 시스템 | O(logn)으로 효율이 좋은만큼 대규모 시스템에서 사용이 유리 |
| 반도체 측정 | 디지털,아날로그 레벨을 측정하는데 사용 |
이진 트리는 자신보다 작은 값들을 왼쪽 서브트리로 가지고 큰 값들을 오른쪽 서브트리로 가지는 자료구조이며 이진 탐색트리는 배열에서 특정값을 찾는 탐색 알고리즘입니다.
후기
이번 챕터에선 Greedy가 가장 어려웠습니다. 이전에도 그리디가 유독 어려웠던 점이 있지만 아무래도 Greedy가 수행되기 위한 조건들을 구체화 하는게 어려웠습니다. 포기하지말고 열심히 하겠습니다!
GitHub
https://github.com/ds02168/CodeStates/tree/main/src/JAVA_Algorithm
