- 마켓과 머신러닝
- 첫번째 머신러닝 프로그램
- 정리
✅ 1. 마켓과 머신러닝
맛보기 (생선 분류 문제)
초보 엔지니어가 한 마켓에서 생선을 분류하는 문제를 머신러닝을 활용하여 해결해보기로 했다. 생선을 분류 하는 일이니 생선의 특징을 알면 쉽게 구분할 수 있다. 초보 엔지니어는 우선 가장먼저 크기로 분류하는 방법을 선택했다.
if fish_length >= 30:
print("도미")문제점
30cm보다 큰 생선이 무조건 도미라고 할 수는 없는 문제가 발생했다. 이런 문제들을 머신러닝은 스스로 기준을 찾아서 해결할 수 있다.
- 도미 데이터 준비하기
1.1 머신러닝은 여러 도미 생선을 보면서 스스로 어떤 생선이 도미인지 구분할 기준을 찾는다. 따라서 우선 많은 생선이 필요하다.
1.2 도미와 방어를 준비해 저울에 올려놓고 무게와 길이를 재어본다. (표본채취)
1.3 colab을 열고 무게와 길이를 파이썬 리스트로 작성한다.
1.4 이 과정에서 도미의 특징을 길이와 무게로 표현한 것을 특성이라고 부른다.
1.5 특성을 x축과 y축의 2차원 그래프로 나타낸다. 이런 그래프를 산점도 라고 한다.
- 그래프 그리기
2.1 산점도(scatter plot)을 그리는 대표적인 패키지는 맷플롯립이다. 이 패키지를 import하고 scatter()함수를 사용하여 만들 수 있다.
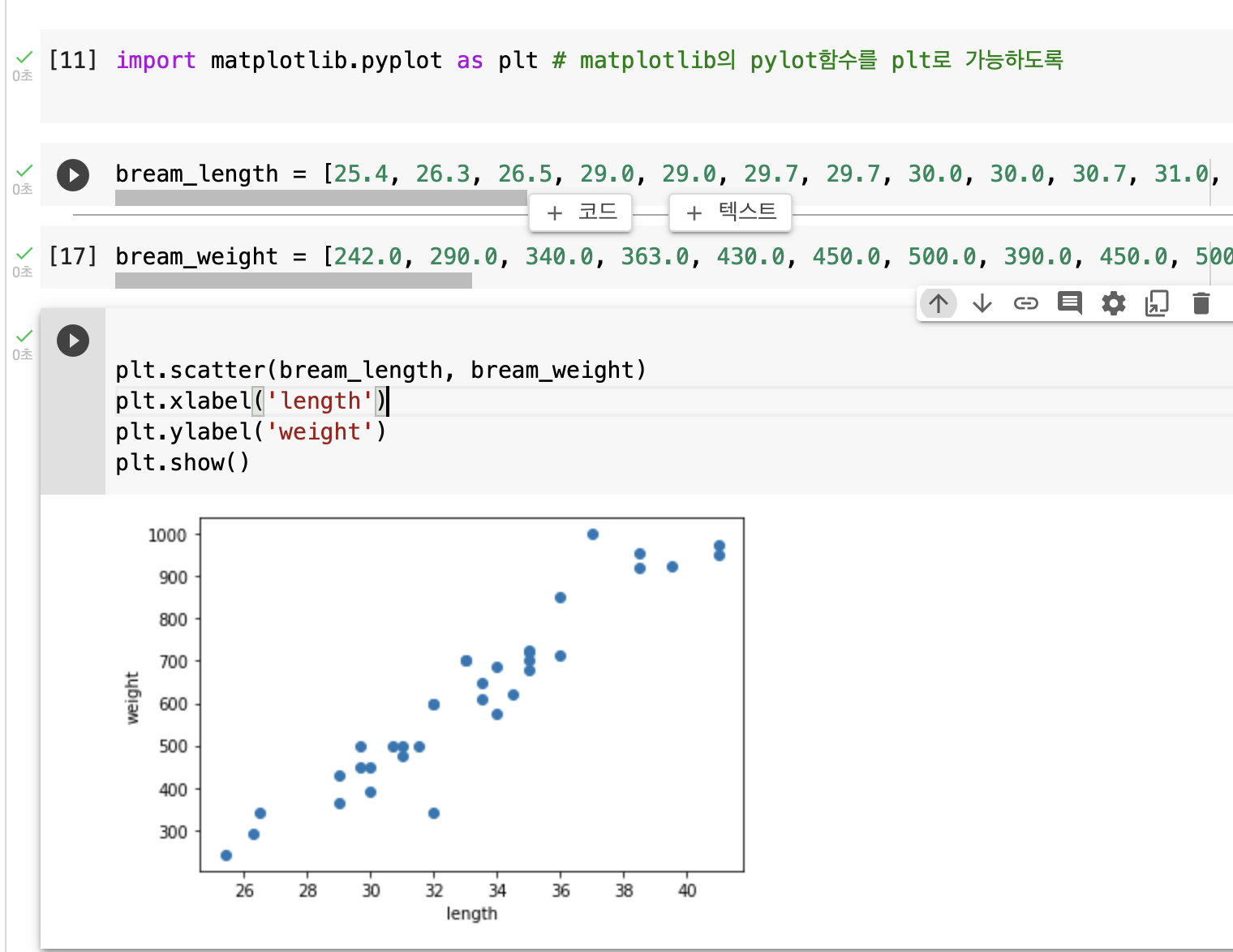
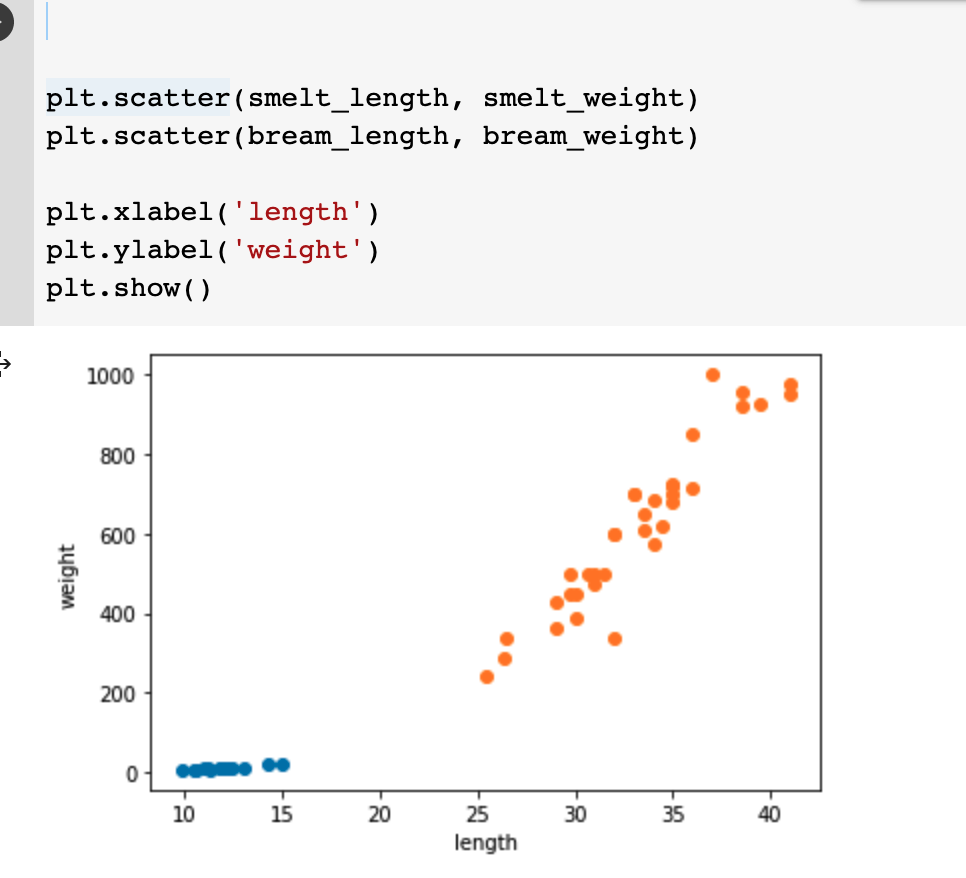
2.2 위 방법을 동일하게 사용하여 방어의 데이터도 준비한다.
✅ 2. 첫 번째 머신러닝 프로그램
이제 머신러닝 프로그램을 만들어보자. 가장 간단한 k-최근접 이웃(k-Nearest Neightbors)알고리즘을 이용한다. 이 알고리즘을 사용해 도미와 방어 데이터를 하나로 합쳐보자.
length = bream_length + smelt_length
weight = bream_weight + smelt_weight사이킷런(scikit-learn)이라는 패키지를 사용하려면 각 특성의 리스트를 세로 방향으로 2차원 리스트를 만들어야 한다.
파이썬의 zip()함수를 이용하면 쉽게 2차원 리스트로 만들 수 있다.
fish_data = [[l,w] for l, w in zip(length, weight)]
print(fish_data)결과
[[25.4, 242.0], [26.3, 290.0], [26.5, 340.0], [29.0, 363.0], [29.0, 430.0], [29.7, 450.0], [29.7, 500.0], [30.0, 390.0], [30.0, 450.0], [30.7, 500.0], [31.0, 475.0], [31.0, 500.0], [31.5, 500.0], [32.0, 340.0], [32.0, 600.0], [32.0, 600.0], [33.0, 700.0], [33.0, 700.0], [33.5, 610.0], [33.5, 650.0], [34.0, 575.0], [34.0, 685.0], [34.5, 620.0], [35.0, 680.0], [35.0, 700.0], [35.0, 725.0], [35.0, 720.0], [36.0, 714.0], [36.0, 850.0], [37.0, 1000.0], [38.5, 920.0], [38.5, 955.0], [39.5, 925.0], [41.0, 975.0], [41.0, 950.0], [9.8, 6.7], [10.5, 7.5], [10.6, 7.0], [11.0, 9.7], [11.2, 9.8], [11.3, 8.7], [11.8, 10.0], [11.8, 9.9], [12.0, 9.8], [12.2, 12.2], [12.4, 13.4], [13.0, 12.2], [14.3, 19.7], [15.0, 19.9]]
이제 머신러닝 알고리즘에게 생선의 길이와 무게를보고 도미와 방어를 구분하는 규칙을 알려줘야 한다. 위 데이터를 보면 도미와 방어를 순서대로 나열했기에 도미는 앞에서부터 35번 뒤로 빙어는 14번 등장하게 된다.
fish_target = [1] * 35 + [0] * 14
print(fish_target)결과
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
👉1은 도미, 0은 방어의 데이터라는것을 알려줄 데이터 준비]
이제 사이킷런 패키지에 K-최근접 이웃 알고리즘을 구현한 클래스인 KNeighborsClassifier을 import해주고 import한 클래스의 객체를 만들어준다.
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()위 객체에서 fish_data, fish_target을 전달하고 도미를 찾는 기준을 학습시킨다. fit()함수를 사용하면 사이킷런에서 주어진 데이터로 알고리즘을 훈련시킨다.
kn.fit(fish_data, fish_target)이제 훈련이 잘 되었는지를 평가해본다.
0~1사이값을 반환하며 1로갈수록 정확도가 올라간다.
kn.score(fish_data, fish_target)

이제 머신러닝 프로그램은 도미와 빙어를 구분할 수 있게 되었다.
코드 링크
https://github.com/dreamjh1111/machine-running/blob/main/fish_models.ipynb
✅ 3. 간단 정리
matplotlib
- scatter()는 산점도를 그리는 맷플롯립 함수
scikit-learn
- KNeighborsClassifier()는 k-최근접 이웃 분류 모델을 만드는 사이킷런 클래스
- fit()은 사이킷런 모델을 훈련할 때 사용하는 메서드
- predict()는 사이킷런 모델은 훈련하고 예측하는데 사용하는 매서드
- score()는 훈련된 사이킷런 모델의 성능을 측정한다.
