
1) DATA STRUCTURE (자료구조)
Q) 자료구조는 왜 배워야 하는가?
A) 나는 앞으로 프로그래밍을 하면서 앞으로 많은 데이터들을 추가하고, 삭제하고, 수정하는 등의 작업을 다각도에서 다루게 될 것이다. 이러한 프로그래밍과 필연적 관계를 맺고 있는 데이터들을 다루면서 이 데이터가 어떤 구조를 가지고 있고, 어떻게 생성되는지도 모른채 데이터를 다룬다는 것은 적어도 내 상식선에서는 '모순이다' 라고 지적하고 있다. 물론 누구는 단순 취업 면접에서 나올 수 있는 질문에 대비하기 위해 자료구조를 공부한다고 말할 수 있다. 하지만 내가 이 프로그래밍에 입문하게 된 것은 논리적 사고에 의한 결과 도출 방식이 마음에 들었기 때문이고 단순 누군가의 질문에 답변하기 위해 공부한다는 것은 내가 입문하게 된 계기와 굉장히 상반된 태도를 가지고 있다. 따라서 나는 이 "프로그래밍에 자료구조 라는 것이 왜 필요한가?" 라는 물음에서 시작했고 그에 대한 나만의 답은 이러한 데이터들의 특징을 파악해 케이스마다 어울리는 데이터 구조를 적용해 코드의 효율성을 높히는 것에 목적이 있다고 생각했다.
나는 이것을 '냉장고 정리' 에 비유하고 싶다. 채소는 채소칸에, 육류는 고기칸에, 음료는 음료칸에 구분해서 넣어두면 다음에 냉장고 문을 열었을 때 음료수를 꺼내기 위해 적어도 채소칸을 뒤적이는 시간을 줄일 수 있는 것처럼 자료구조 또한 이 구조를 알아야 우리가 원하는 데이터를 꺼내고, 보관하고, 수정하는 것에 효율성을 높일 수있다고 생각한다.
서론이 길었지만, 나는 앞으로도 계속 이러한 질문을 먼저 내 스스로에게 던지고, 단순 지식의 습득을 넘어서 그 자체를 이해하는 것에 목적을 둘 것이다. 이 블로그는 누군가에게 보여주기 위한 블로그가 아닌 내 스스로의 학습을 위한 블로그이기 때문이다.
QUEUE
QUEUE 는 선입선출 방식이다.
QUEUE 구조는 우리 실생활에 가장 잘 적용되어 있어 이해하기 쉽다.
우리가 맛집을 방문해 줄을 선다고 생각해보자. 우리의 상식선에서는 먼저 줄을 선 사람이 당연히 먼저 입장에 식사를 하는 것이 당연하다고 생각한다.
QUEUE 구조는 이러한 방식을 따른다.
먼저 들어오는 것이 먼저 나가는 First in First Out 의 방식을 따르고 있는 것이다. (줄여서 FIFO 라고도 부른다)
STACK
STACK 은 선입후출 방식이다.
STACK 구조는 우리의 실생활에 적용한다면 많은 도덕적 문제를 야기할 수 있는 방식이다.
STACK 구조를 실생활에 적용한다면 맛집을 방문해 먼저 줄을 선 사람은 가장 마지막에 식사하게 될 것이다.
먼저 들어온 것이 나중에 나가는 First in Last out 의 방식을 따르고 있는 것이다. (줄여서 FILO 라고도 부른다)
콘서트의 상황을 STACK 구조에 비유하는 것이 적절할 것 같다.
콘서트에 방문한 관객 중 어떤 관객은 좋아하는 가수를 가까이서 보기 위해 비싼 금액을 지불하고 맨 앞 좌석에 앉는다.
하지만 무사히 콘서트가 끝나고 집으로 귀가하기 위해 밖을 나가려면 마지막에 입장한 관객이 문에 가장 가까우므로 처음 입장한 관객은 퇴장하기까지 아마 많은 시간을 기다려야 할 것이다.
HASH TABLE
해시함수(hash function)는 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수입니다. 이 때 매핑 전 원래 데이터의 값을 키(key), 매핑 후 데이터의 값을 해시값(hash value), 매핑하는 과정을 해싱(hashing)이라고 합니다.
특정 데이터를 받아오면 이 데이터를 HASH FUNCTION 을 거쳐 데이터를 매핑한다. 그리고 이렇게 매핑된 데이터를 보관해 두는 곳을 HASH TABLE 이라고 한다.
(매핑 (Mapping) 이란 하나의 값을 다른 값으로 대응하는 것을 의미한다)
HASH TABLE 은 배열과 마찬가지로 인덱스, 값 으로 분류한다.
하지만 명칭이 조금 다른데 인덱스가 저장되는 곳을 버킷(bucket) 혹은 슬롯 (slot) 이라고 부른다.
HASH TABLE 의 장점
1. 빠른 데이터 검색
해쉬 함수를 거친 데이터는 일정한 규칙을 따라 일정한 고정값을 가지게 된다.
예를 들어 내가 Yongho 라는 단어를 해쉬 함수를 통해 매핑하여 HASH TABLE 에 보관할 경우, 이 값은 01 이라는 값을 가진다고 가정해보자.
그렇다면 다음에 내가 Yongho 라는 단어가 어느 곳에 저장돼있는지 확인하기 위해서는 단지 해쉬 함수에 Yongho 를 넣어보면 01 을 리턴하므로 그 데이터의 위치를 쉽게 파악할 수 있게 된다.
2. 효율적인 데이터 관리
무한에 가까운 데이터를 보관할 때 해시 함수를 통해 해시값으로 매핑함으로써 작은 크기의 캐쉬 메모리로도 저장이 가능하다.
3. 보안에 유리
해시 함수는 일방향 함수로 암호화 과정만 있고 복호화 과정이 없는 특징이 있어서 일반적으로 해당 값을 복호화하는 것은 불가능에 가깝다.
따라서 보통 비밀번호를 암호화 하는데 많이 사용된다. (비밀번호 + 해시 값으로 저장)
HASH TABLE 의 단점
1. 해시 충돌
가장 큰 단점은 해시 충돌 이다.
해시 함수를 통해 Yongho 라는 단어를 01 이라는 해시 값으로 매핑했다고 가정하자.
이후 해시 함수를 통해 Kimchi 라는 단어를 넣었더니 Yongho와 똑같이 01 이라는 값이 나와버릴 수 있는 상황이 발생할 수 있다.
이렇게 되면 한 버킷에 두 개의 값이 들어가게 되므로 데이터를 검색할 때 원하는 값이 나오지 않는 문제가 생길 수 있다.
2. 이후에 발견 된 보안상의 문제
과거에는 패스워드 암호화를 위해 해시 함수를 많이 사용했다고 한다.
하지만 이러한 방식에는 문제가 있는데 아까 언급했듯이 해시 함수는 입력값에 대한 고정값을 리턴한다는 것이다.
실제로 레인보우 테이블이라는 해시 함수를 통해 만들어 낼 수 있는 값을 대량으로 저장한 표가 있는데
이걸 악용하면 레인보우 테이블을 이용해 해시값으로 매핑된 데이터를 쉽게 복호화 할 수 있다는 문제가 발생한다.
그래서 요즘은 비밀번호 + 해시 + 솔트 (Salted Function) 방식을 사용한다.
솔트 함수란 해시함수를 돌리기 전에 원문에 임의의 문자열을 덧붙이는 것을 말한다. 단어 뜻 그대로 원문에 임의의 문자열을 붙인다는 의미의 소금친다(salting) 는 것이다.
이 방식을 왜 사용하느냐?
솔트 함수는 문자열 값을 랜덤하게 생성한다는 점 때문이다.
이 말인 즉슨, 해커가 해싱 된 비밀번호를 알아내기 위해 레인보우 테이블을 참조하더라도 그 비밀번호에 랜덤한 문자열 값이 더해졌기 때문에 복호화가 거의 불가능에 가까워 진다는 것이다.
해시 충돌 극복 방법
1. 분리 연결법 (Separate Chaining)
-
한 버킷당 들어갈 수 있는 엔트리의 수에 제한을 두지 않는 방법으로 모든 자료를 해시 테이블에 담는다.
-
해당 버킷에 이미 데이터가 있다면 체인처럼 노드를 추가하여 다음 노드를 가리키는 방식이다.
-
Linked List를 이용하는 방식이라고 생각하면 된다.
❗️ 단점: 메모리 문제를 야기할 수 있다.
2. 개방 주소법 (Open Addressing)
개방 주소법의 여러가지 방식 중 가장 간단한 Linar probing 방식은 index에 대해서 충돌이 발생했을 때, index 뒤에 있는 버킷 중에 빈 버킷을 찾아서 데이터를 넣는 방식이다.
예를 들어 Yongho 데이터가 1 인 해시값으로 나왔는데 이미 버킷에 1인 값이 있을 경우 그 다음 버킷이 비어있는지 확인한다. 만약 그 다음 버킷이 비어있지 않다면 그 다음다음 버킷을 확인하는 식의 방식이다.
3. 리스트 크기 재배열
해쉬 테이블의 수용률은 10인데 들어오는 데이터는 20인 경우, 아예 리스트 자체의 크기를 키운 뒤에 재배열을 하는 방법이다.
다만, 이 과정은 시간이 상당히 많이 소요되므로 실시간으로 빠르게 처리해야 하는 환경에서는 무리가 있는 방법이다.
LINKED LIST
연결 리스트, 링크드 리스트(linked list)는 각 노드가 데이터와 포인터를 가지고 한 줄로 연결되어 있는 방식으로 데이터를 저장하는 자료 구조이다. 이름에서 말하듯이 데이터를 담고 있는 노드들이 연결되어 있는데, 노드의 포인터가 다음이나 이전의 노드와의 연결을 담당하게 된다.
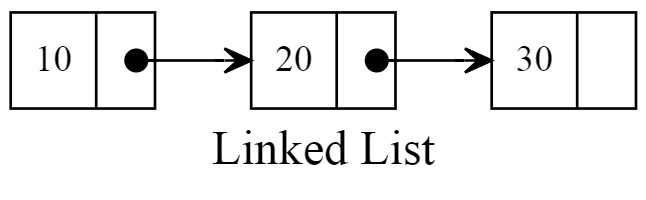
위 사진과 같이 데이터들이 각각 연결돼있는 구조다. 여기서 데이터를 구성하는 각 요소들을 노드 라고 한다. 즉, Linked List 는 각각의 노드들이 연결돼있는 구조인 것이다.
Linked List 구조의 가장 큰 장점은 추가와 삭제에 용이하다는 것이다.
위 사진에서 각 숫자는 데이터, 화살표는 주소라고 할 수 있다.
만약, 20의 값을 없애고 싶다면 10의 주소를 30에 연결해주면 끝인 것이다.
(자바스크립트는 안쓰는 데이터는 자동으로 삭제하는 기능이 존재하지만 C 나 C++ 은 그 데이터를 보관하므로 꼭 따로 지워주는 작업을 해야한다고 한다)
또 만약, 20과 30 사이에 25라는 값을 넣고 싶다면, 20의 주소를 25에 연결하고 25의 주소를 30에 연결하면
10 -> 20 -> 25 -> 30 과 같은 구조가 완성되는 것이다.
하지만 이러한 방식은 특정 데이터를 검색하는데 많은 시간이 소요된다.
Linked List 에서 첫 노드는 HEAD, 마지막 노드는 TAIL 이라고 표현하는데
특정 노드를 찾기 위해서는 무조건 이 첫 노드의 값을 알아야만 검색할 수 있다. (Linked List 구조는 연결돼있는 구조라는 것을 잊지말자)
그리고 특정 값을 찾기 위해서는 첫 노드의 값부터 내가 찾고자 하는 값이 나올 때 까지 데이터를 탐색해야 한다. 이러한 점이 Linked List 의 단점으로 꼽힐 수 있다고 할 수 있다.
LINKED LIST 종류
1. 단일 연결 리스트
단일 연결 리스트는 각 노드에 자료 공간과 한 개의 포인터 공간이 있고, 각 노드의 포인터는 다음 노드를 가리킨다.

위 사진과 같이 모든 데이터를 선형적으로 연결한 방식이다.
이러한 방식은 처음에 설명했듯이 추가와 삭제에는 용이하지만 특정 데이터를 검색하는데는 많은 시간을 소요한다.
2. 이중 연결 리스트
이중 연결 리스트의 구조는 단일 연결 리스트와 비슷하지만, 포인터 공간이 두 개가 있고 각각의 포인터는 앞의 노드와 뒤의 노드를 가리킨다.

단일 연결리스트의 단점을 어느정도 보완한 방식이라고 생각해도 좋을 것 같다.
각 노드들은 다음 노드의 주소만 참조하는 것이 아닌 이전의 노드의 주소도 참조할 수 있게 만든 방식이다.
이에 따라 특정 데이터를 검색하는 시간을 많이 줄일 수 있다.
단, 이러한 방식은 데이터를 추가하거나 삭제할 때 단일 연결 리스트보다 수행해야 할 과정이 더 많으므로 더 많은 메모리를 차지하게 된다. (잠재적으로는 더 효율적인 방식)
TREE
트리 구조(tree 構造, 문화어: 나무구조)란 그래프의 일종으로, 여러 노드가 한 노드를 가리킬 수 없는 구조이다. 간단하게는 회로가 없고, 서로 다른 두 노드를 잇는 길이 하나뿐인 그래프를 트리라고 부른다.
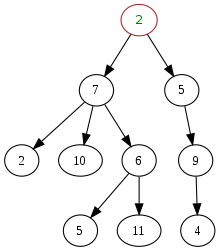
-
트리에서 최상위 노드를 루트노드, 뿌리노드라고 한다. (2는 루트노드)
-
각 노드의 바로 위 노드를 부모 노드, 바로 아래의 노드를 자식 노드라고 한다. (7, 5 의 부모노드는 2, 7의 자식노드는 2, 10 ,6)
-
자식노드가 없는 노드를 잎 노드 (leaf node) 라고 부른다. (5, 11, 4 는 잎 노드)
-
잎 노드가 아닌 노드를 내부 노드 (internal code) 라고 부른다. (5, 11, 4 를 제외한 노드)
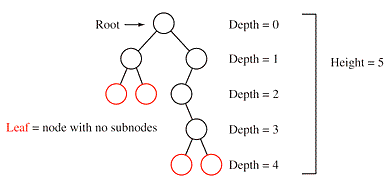
-
루트를 기준으로 다른 노드에 접근하기 위한 거리를 depth (깊이) 라고 한다.
-
트리의 depth 를 모두 더한 길이를 height (높이) 라고 한다.
-
같은 부모를 가지면서 같은 depth 에 존재하는 노드들은 sibling (형제) 관계이다.
BINARY TREE (이진 트리)
이진 트리(二進-, 영어: binary tree)는 각각의 노드가 최대 두 개의 자식 노드를 가지는 트리 자료 구조로, 자식 노드를 각각 왼쪽 자식 노드와 오른쪽 자식 노드라고 한다.
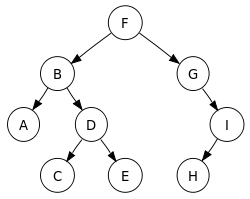
(크기가 9이고 높이가 3인 이진 트리의 모습)
BINARY TREE 의 종류
1. Full Binary Tree (정 이진 트리)
정 이진 트리(整二進-, 영어: full binary tree, 때로는 proper 또는 plane 이진 트리라고도 함)는 모든 노드가 0개 또는 2개의 자식 노드를 갖는 트리다.
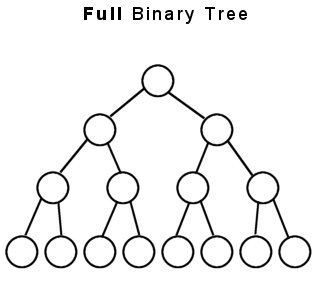
자식 노드를 가질거면 2개를 갖던가, 아니면 아예 갖지를 말던가! 하는 방식을 추구한다.
(이러한 이분법적 사고를 지닌 인간과 일을 해야한다고 생각하면......... 끔직하다.)
2. Complete Binary Tree (완전 이진 트리)
완전 이진 트리는 마지막 레벨을 제외하고 모든 레벨이 완전히 채워져 있으며, 마지막 레벨의 모든 노드는 가능한 한 가장 왼쪽에 있다. 또 다른 정의는 가장 오른쪽의 잎 노드가 (아마도 모두) 제거된 포화 이진 트리다.

자식 노드들이 왼쪽부터 채워져야 완전 이진 트리 라고 할 수 있다. 만약, 위 사진에서 L 이 부모인 F 노드의 오른쪽에 위치해있다면 그 때는 완전 이진 트리라고 할 수 없다.
3. Perfect Binary Tree (포화 이진 트리)
포화 이진 트리(飽和二進-, 영어: perfect binary tree)는 모든 내부 노드가 두 개의 자식 노드를 가지며 모든 잎 노드가 동일한 깊이 또는 레벨을 갖는다(이는 애매모호하게 완전 이진 트리라고도 불린다). 각각의 사람이 정확히 두 명의 생물학적 부모(한 명의 어머니와 한 명의 아버지)를 갖는 것처럼, 주어진 깊이에 대한 한 사람의 가계도가 포화 이진 트리의 예가 될 수 있다.
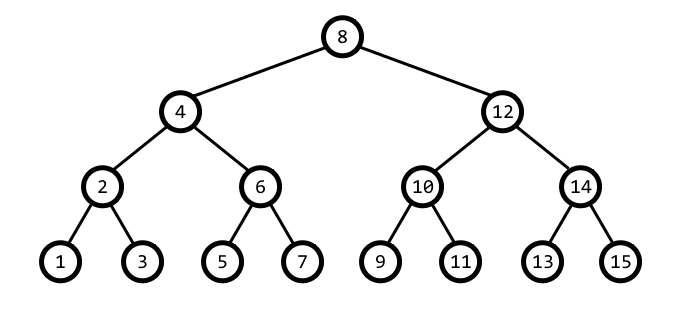
딱 봐도 심리적 안정감이 드는 이진 트리 구조다. 모든 노드가 최대로 수용할 수 있는 개수를 소유하고, 레벨 또한 딱 맞는 방식을 추구한다.
BINARY SEARCH TREE
이진 트리의 모든 노드를 방문하는 것 혹은 방문하여 어떤 작업을 하는 것을 이진 트리 탐색 (Binary Search Tree) 이라고 한다.
-
pre-order(전위 순회) : 내 노드(P) → 왼쪽 자식노드(L) → 오른쪽 자식노드(R) 순서로 방문한다.
(F, B, A, D, C, E, G, I, H) -
in-order(중위 순회) : 왼쪽 자식노드(L) → 내 노드(P) → 오른쪽 자식노드(R) 순서로 방문한다.
(A, B, C, D, E, F, G, H, I)
- post-order(후위 순회) : 왼쪽 자식노드(L) → 오른쪽 자식노드(R) → 내 노드(P) 순서로 방문한다.
(A, C, E, D, B, H, I, G, F)
- level-order(레벨 순회) : 내 노드(P), 내 노드로부터 깊이 1인 노드들, 내 노드로부터 깊이 2인 노드들, ... , 내 노드로부터 깊이 N인 노드들 (N: 나(트리)의 깊이)
(F, B, G, A, D, I, C, E, H)
GRAPH
2) TIME COMPLEXITY (시간 복잡도)
시간 복잡도는 문제를 해결하는데 걸리는 시간과 입력의 함수 관계를 가리킨다.
시간 복잡도는 Big-O 로 측정되는 두 가지 복잡성 (시간 복잡성, 공간 복잡성) 중 하나이다.
BIG-O (빅오 표기법)
빅오 표기법은 불필요한 연산을 제거하여 알고리즘 분석을 쉽게 할 목적으로 사용된다.
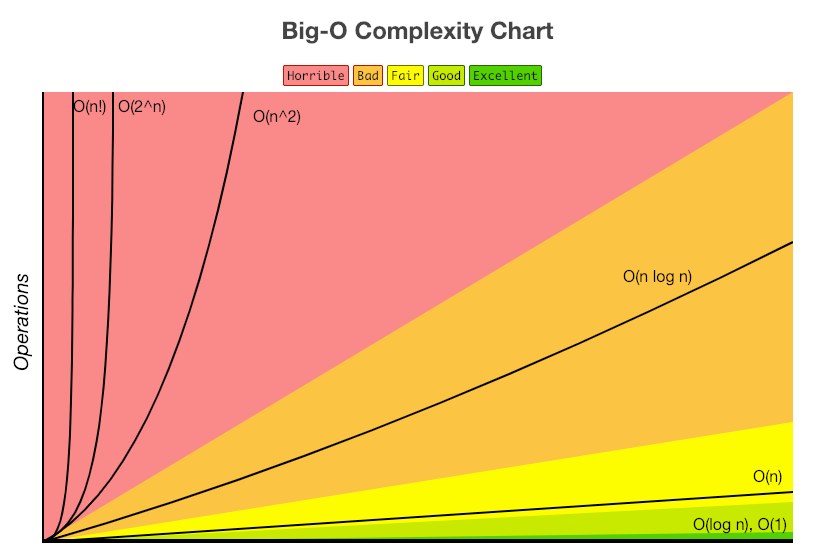
왼쪽부터 데이터를 처리하는 시간이 빠른 순서이다.
| O(1) | O(log n) | O(n) | O(n*log n) | O(n^2) | O(2^n) |
|---|---|---|---|---|---|
| 상수 시간 | 로그 시간 | 직선적 시간 | 선형로그형 | 2차 시간 | 지수 시간 |
| 문제를 해결하는데 오직 한 단계만 처리함 | 문제를 해결하는데 필요한 단계들이 연산마다 특정 요인에 의해 줄어듦 | 문제를 해결하기 위한 단계의 수와 입력값 n이 1:1 관계를 가짐 | 문제를 해결하기 위한 단계의 수가 N*(log2N) 번만큼의 수행시간을 가짐 | 문제를 해결하기 위한 단계의 수는 입력값 n의 제곱 | 문제를 해결하기 위한 단계의 수는 주어진 상수값 C 의 n 제곱 |
| STACK 에서 Push, Pop | BINARY TREE | for 문 | 퀵 정렬(quick sort), 병합정렬(merge sort), 힙 정렬(heap Sort) | 이중 for 문 | 피보나치 수열 |
3) OBJECT ORIENTED PROGRAMMING (객체 지향 프로그래밍)
4) 두 개의 스프린트
이번 스프린트에서는 객체 지향 프로그래밍을 주제로 하였다.
그 중 상속 패턴 개념을 주로 다뤘는데 ES5와 ES6 에서 각각 어떻게 상속 패턴을 구현하는지 배웠다.
1. beesbeesbees
ES6, Pseudoclassical 폴더 2개에 각각 4개의 js 파일이 주어진다.
Grub → Bee → ForagerBee → HoneyMaker 순으로 상속을 구현하면 됐다.
ES6 는 class ~ extends ~ 메소드를 통해 상속을 해준 뒤
super 메소드를 통해 부모 노드의 속성과 메소드를 모두 불러왔다.
Pseudoclassical 에서는 ~.call(this) 를 통해 부모의 메소드를 호출하고 자식의 프로토타입을 Object.create(부모.prototype) 을 통해 부모의 프로토타입을 참조하게 해줬다. 그 뒤 자식.prototype.constructor = 부모 를 통해 constructor 까지 부모를 참조하게 바꾼 것을 다시 자기 자신으로 바꾸는 작업을 해줬다. (이 과정을 해주지 않으면 꼬이게 되지만 왜 꼬이는지는 아직 정확하게는 모른다..)
2. SUBCLASS-DANCE-PARTY
주어진 파일에는 이미 html, css, js 의 작업이 이루어져있다.
단, js 의 작업은 functional instantiation pattern (함수를 이용한 상속 패턴) 으로 구현되어 있다.
여기서 beesbeesbees 스프린트와 같이 주어진 js를 ES6와 Pseudoclassical 한 방법으로 리팩토링 하는것이 이번 스프린트의 목표이다.
처음 스프린트를 진행할 때 ES6와 Pseudoclassical 상속 패턴에 익숙치 않아서 어디서부터 손을 대야할 지 감을 찾지 못했다.
가장 난항을 겪었던 건 super() 키워드인데 나는 분명 constructor의 매개변수와 super 가 받아올 파라미터가 같으면 매개변수를 생략해도 된다고 알고 있었고 beesbeesbees 도 이런식으로 진행했다. 따라서 나는 이번 스프린트에서도 그대로 진행했는데, 테스트는 자꾸 파라미터를 받아오지 못한다는 오류를 냈다. 그래서 consturctor 에 정확한 값을 넣어주고 super 를 통해 그 값들을 받아오니 그제서야 테스트가 통과됐다. 왜 이러는지는 후에 추가적으로 TIL 을 작성해야 겠다.
추가적으로 공부해야 할 것들
call,this,bind메소드의 정확한 이해- 각 케이스 마다 this 의 유효 범위
- 기본적인 CSS 메소드 만지는법
💻 OVERALL
이번 2주차를 통해 앞으로의 과정들은 기존의 개념에서 더욱이 깊이 들어간다는 느낌을 강하게 받았다. 이 느낌은 곧 내 머릿속에 저장된 기존의 개념을 탄탄하게 해두지 않으면 나중에 더 힘들어질 것이라는 결론을 내리게 했고 잠시동안 나무를 감상하던 내 시선을 조금 더 멀리있는 숲에 돌리게 해줬다. 특히 subclass dance party 에서 내가 JS에만 너무 신경을 쓴 것이 아닌가 할 정도로 CSS 에 대한 기본적인 지식이 많이 부족했다. 지금 하고 있는 교육이 어느정도 풀스택을 지향하지만 거의 Front-end 교육에 가깝고 나중의 나는 Full-Stack 개발자가 되기를 원하기 때문에 어느 하나를 게을리하면 안되는 입장이다. 그래서인지 현재 나에게 가장 부족한 개념인 CSS 의 중요성을 더욱 더 느끼게 됐다.
배움을 즐겁게 받아들이기 위해선 배움을 통해 나만의 무엇을 만들어야 한다.
문제는 이런 사실을 알면서 안하는 나 자신이다 😔
