Kafka
Kafka 란
Publish-Subscribe Model 을 구현한 Distributed Messaging System
=> Data 만드는 Producer , 소비하는 Consumer 와 둘 사이 중재자 역활 하는 Broker로 구- 성
- Producer(App)는 Broker를 통해 Message를 Publish
- Consumer 가 Subscribe 할 Message를 Brker에게 요청
( 블로그 글 작성 후 발행시 블로그 글을 독자가 구독해 따로 읽는 형태 )
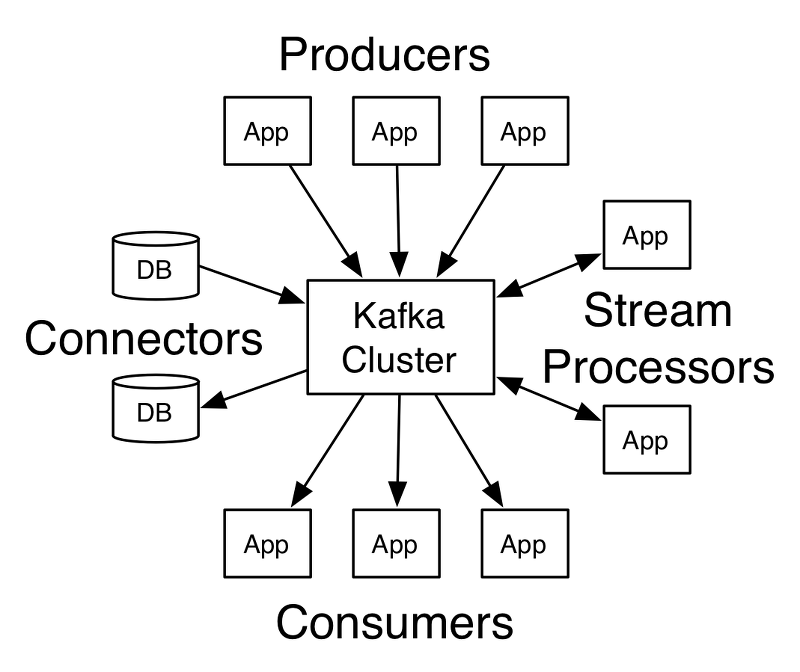
Kafka 용어
- Zookeeper : Kafka의 Metadata 관리 및 Broker 정상상태 점검 담당
- Kafka cluster : 여러 대 Broker를 구성한 Cluster
- broker : Kafka Application이 설치된 Server or Node
- Producer : Kafka 로 Message 보내는 Client
- Consumer : Kafka에서 Message 꺼내가는 Client
- Topic : Kafka는 Message Feed들을 Topic으로 구분 ( 고유해야함 , Folder와 유사 )
- Partition : Parallel Processing 및 High Performancy 위해 하나의 Topic을 여러 개로 나눈 것 ( Message 저장하는 물리적 File )
- Segment : Producer 가 전송한 Message가 Broker의 Local Disk에 저장되는 File
- Message(Record) : Producer 가 전송하거나 Consumer가 읽어가는 Data Fragment
Kafka 특징
- 다중 Producer , Consumer
- 여러 Producer 가 동시 Message 전송 가능 ( 여러 Consumer 가 동시 Reading도 가능 )
- 하나의 Producer 가 여러 Topic에 Message Push 가능 , 하나의 Consumer 가 여러 Topic에서 Message Pull 가능
- FileSystem에 저장
- 기존 Messaging System 은 Memory 내 Queue에 유지
( Consumer 가 Message를 읽을 시 Queue에서 Message 제거 ) - 빠른 시간 내 소비될거라 가정- Producer 와 Consumer 간 속도 차이가 있을때 유용
( Consumer 쪽 장애가 생기거나 , Network Traffic 생길때 영향을 주지 않으며 속도 조절 )- Consumer 쪽에서 Error 생길시 이전에 읽은 Data 다시 읽기 가능
- Scalabillity
- 운영중 확장 가능 ( 수평적 확장 )
- Group에 추가할 시 소유권을 재분배 하는 Rebalacning 을 거쳐 고르게 Partition을 할당 받음.
- Replication
- 각 Message 들 여러 개 복제해서 Kafka Cluster 내 Broker들에 분산시키는 동작 의미
( 하나가 종료 되더라도 안정성 유지 가능 )
=> 개수가 많아질수록 안정성이 높아지나 , Overhead 발생하므로 적절한 개수 설정해서 사용해야 함.
추가 정보
- 파티션은 추가만 가능한 파일 ( Append-only )
=>Message는 삭제 X (일정 시간 지난뒤 자동 삭제)- Message는 파티션 맨 뒤 추가 ( 오프셋 기준 메시지를 순서대로 읽음 )
- 한 개 파티션은 컨슈머그룹의 한 개 컨슈머만 연결 가능
( 그룹에 속한 컨슈머들이 파티션 공유 불가능 ! )
=> 파티션 메시지가 순서대로 처리 되는걸 보장
성능
- 파티션 파일은 O.S Page Cachcing 사용
=> Memory 내 File I.O가 처리되기 때문에 매우 빠름- Zero Copy 기법 사용 ( Disk -> Network 보내는 속도가 빨라짐 )
- Broker가 하는 일이 단순 ( Producer , Consumer가 직접 함 )
- 묶어서 처리 가능 - batch ( 처리량 증가 )
( producer : 일정 크기만큼 Message 모아서 전송 )
( consumer : 최소 크기만큼 Message 모아서 조회 가능 )
그래서 왜 사용하는가? - in LINE
1. 단순한 Distributed Queuing System
Web Application Server에서 처리하는 데 바쁜 업무 발생시 , 내부에서 처리하지 않고 Background Task Process에 요청하기 위한 Queue로 사용 가능
2. Data hub
Data Update 발생 시 , 해당 Data 사용하는 다른 Service에 전파하는 Hub로 사용하는 방법
사용자 A - 사용자 B 친구 추가시 , 처리 수행 및 업데이트 관계를 Event로 입력해 다른 System 및 Timeline Service에 사용
출처
https://engineering.linecorp.com/ko/blog/how-to-use-kafka-in-line-1/
https://zeroco.tistory.com/105

https://youngsu5582.today/ 로 블로그 이동중입니다~
역활 에반데