
Caching Design
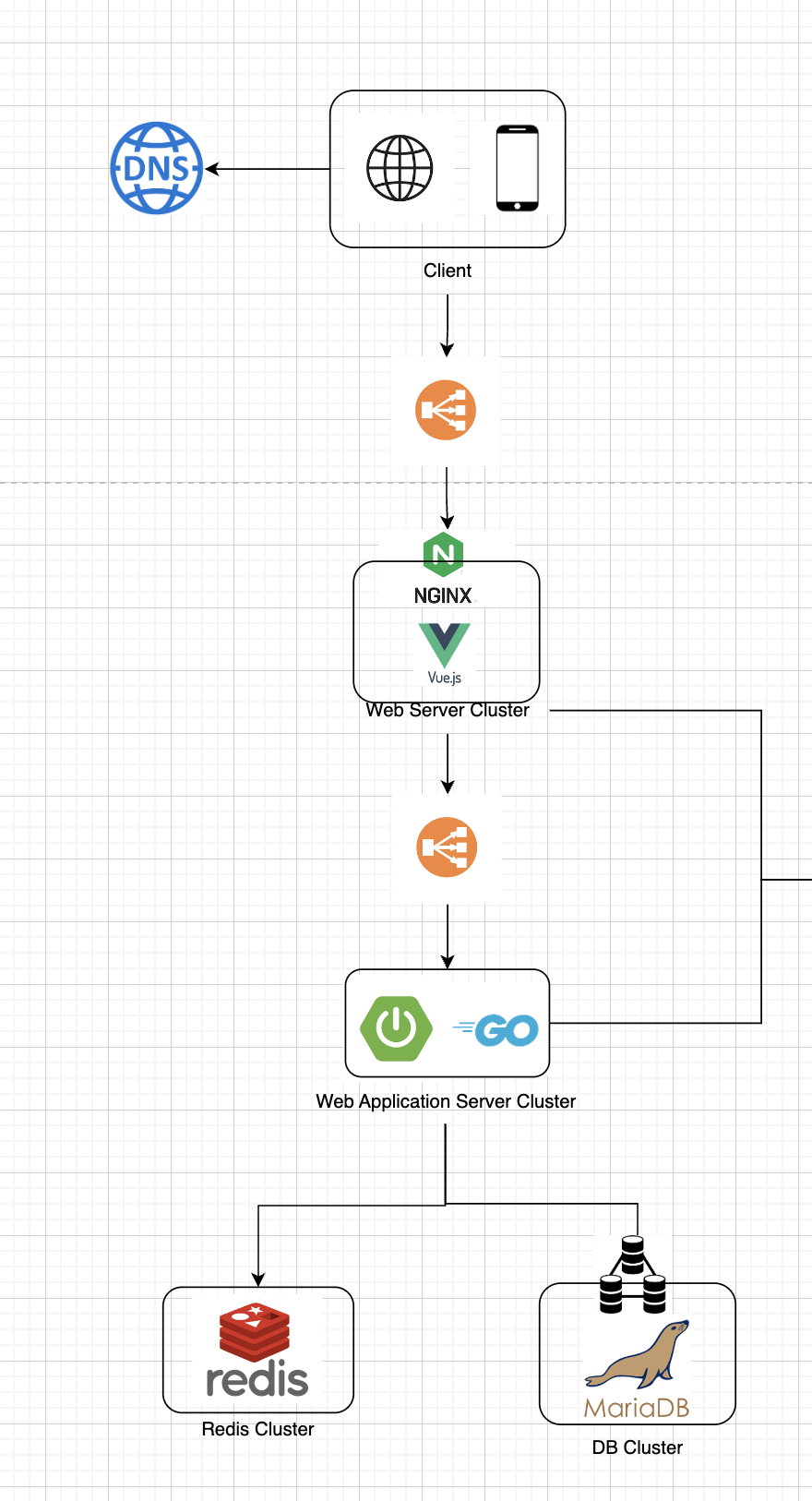
- 해당 도메인은 데이터가 만들어지고 나서부터 데이터(Short Link에 대한 Original Link)가 변경되지 않는다.
- 캐싱의 어려운 점인 데이터 업데이트(캐시과 DB의 동기화)에 대한 고민을 하지 않아도 된다.
- 즉, 캐싱을 적극 활용하여 클라이언트에게 빠른 속도로 제공할 수 있다.
- 1차 캐싱: Nginx 와 같은 웹서버에서 캐싱 (Nginx Caching Reference)
- 2차 캐싱: Redis Clustering
- DB Indexing: RDBMS or NoSQL
위 2단계의 캐싱으로 Caching hit ratio 높을 것으로 예상되고, DB에 접근하지 않는다면 매우 빠른 속도로 응답을 할 수 있을 것으로 보여진다.
DB에 Short Link에 대한 Indexing을 생성하여 DB에서도 조회 속도를 개선한다.
Node Spec
- Web Server
- 최소 노드 개수: 3개
- vCPU: 4~8개
- Memory: 16~32GB
- WAS
- 최소 노드 개수: 3개
- vCPU: 8~16개
- Memory: 16~32GB
- Cache
- 최소 노드 개수: 3개
- vCPU: 4~8개
- 메모리: 32GB
Reason
- 레이어 당 3개의 노드를 사용하는 이유는 고가용성 및 로드 밸런싱을 보장하기 위해서이다.
- 3개의 노드 설정에서 한 노드가 다운되면, 다른 두 노드가 계속해서 요청을 처리할 수 있고 부하가 고르게 분산될 수 있기 때문이다.
- Read 연산이 초당 11458번 발생한다고 예상할 때, 캐시 적중 횟수는 11458 * 0.8 = 9166.4번이다.
- 각 데이터 조각이 500Bytes 라고 가정할 때, 캐싱에 필요한 메모리 양은 9166.4 * 500Bytes = 4.5632MB/s 이다.
- 위 캐싱 처리량을 처리하려면 각 캐싱 노드에 충분한 CPU 및 메모리 리소스가 있어야 한다.
- 정확한 필요 리소스는 예상되지 않지만, 어느정도 예상치로 구축하였다.
- 각 캐시 레이어마다 담당하는 역할에 따른 스펙으로 수정하였다.
Scalability(auto scaling) - Web Server, WAS, Cache Cluster
- CPU 사용량: 60%
- Network In/Out: 70%
- Memory: 60%
- Request Counts: 예상 단위 초당 70%
Reason
- 임계치에 대한 명확한 기준은 예상할 수 없고, 일반적으로 사용되는 임계치를 기준으로 삼았다.
Database Design
Q: 수천억개의 rows를 쌓아야 한다. RDBMS보다 NoSQL 중 어떤 것을 선택해야 하나?
A: RDBMS보다 NoSQL이 더 나은 선택이다.
- 데이터를 업데이트(수정)하는 작업이 존재하지 않는다.
- 데이터 간에 Relationship이 필요로 하지 않기 때문에 복잡한 쿼리나 조인이 필요로 하지 않는다.
- 데이터를 여러 노드에 분산 저장하는 분산 아키텍처이므로 scale out에 용이하다.
- 수천억개의 데이터에서 조회를 해야하기 때문에 여러 노드에서 병렬로 데이터를 읽을 수 있으므로 Read 시간이 더 빠르다.
- 내부적으로 자주 엑세스하는 데이터를 메모리에 저장하는 인메모리 캐싱을 자주 사용한다.
short_url
- PK
- short_id
- original_url
- created_at
- client_ip
- user-agent-
Database 파티셔닝, 복제
- Range Based Partitioning: URL의 문자를 기준으로 범위를 나누는 파티셔닝
- ex) A로 시작하는 URL끼리, B로 시작하는 URL끼리
- unbalanced 문제가 발생할 수 있음
- Hash Based Partitioning: URL을 기준으로 해시 키값을 기준으로 나누는 파티셔닝
- hash로 발생하는 충돌이 발생하고, unbalanced 문제가 발생할 수 있음
- Range Based Partitioning: URL의 문자를 기준으로 범위를 나누는 파티셔닝
-
인덱스
shortId를 기준으로 인덱스를 생성하여 탐색속도를 향상시킨다.
Statistics Design
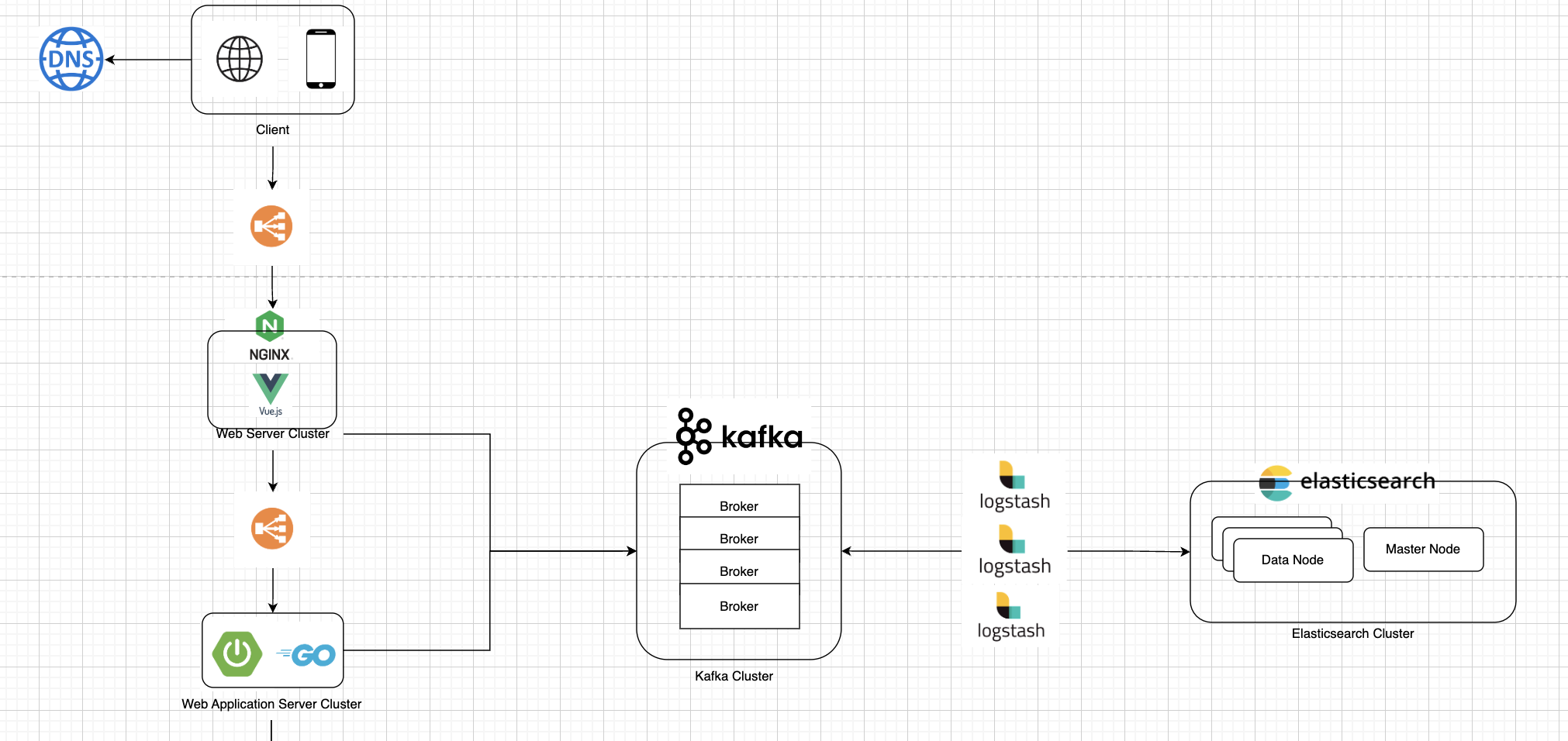
-
Ngnix에서 캐싱된
ShortId로 Read 및 Redirection 발생 시 Kafka Topic으로 Record Produce 후 리턴 -
Ngnix에서 캐싱된
ShortId에 대하여 WAS에서 Redis or DB 조회 후 Kafka Topic으로 Record Produce 후 리턴 -
Logstash에서 Kafka Topic에서 Consume -> 데이터 가공 -> ElasticSearch 데이터 노드로 전송
- ElasticSearch 날짜로 인덱스 생성
-
WAS에서 해당
ShortId를 기준으로 ElasticSearch에 쿼리를 날려 Statistics 제공
