
문제점
일시적으로 DB 노드에 insert가 되지 않는 장애가 발생할 경우 어떻게 처리해야 할까?
크게 DB에서 제공하는 장애 대응과 데이터 파이프라인을 활용하는 방법이 있을 것 같다.
RDB Master Node 장애 대응
-
Failover
- master 노드에 장애가 발생한 경우 standby 노드 중 하나가 master 역할을 대신 수행하도록 하는 한다.
- Failover를 구현하기 위해서는 별도의 클러스터링 솔루션을 사용해야 한다.
-
Repair
- Repair는 장애가 발생한 master 노드를 복구하여 다시 사용할 수 있도록 하는 방식이다.
- 복구를 위해서는 주로 데이터베이스 백업과 복원, 데이터베이스 내부의 로그 또는 레플리케이션 기능 등을 사용한다.
- 데이터베이스 제조사에서 제공하는 복구 도구를 사용하거나, 수동으로 데이터를 복구하고 복원하는 과정을 거쳐야 한다.
장단점
- Failover는 빠른 대응이 가능하지만, standby 노드에서 장애가 발생하거나, master 노드로의 승격에 따른 장애가 발생할 가능성이 있다.
- Repair는 데이터 손실이 없는 복구가 가능하지만, 복구 시간이 오래 걸릴 수 있다.
- 따라서 Failover와 Repair를 모두 고려하여 시스템을 구성하는 것이 좋다.
NoSQL 장애 대응
Retry
- NoSQL에서는 데이터의 일관성이 보장되지 않을 수 있으므로, 일시적인 장애로 인해 insert가 실패하더라도 Retry를 통해 다시 시도하는 것이 가능하다.
- 이때, 일정 시간 간격으로 Retry를 수행하거나, 일정 횟수 이상의 Retry가 실패했을 때 알림을 보내는 등의 로직을 추가하여 안정적인 처리를 할 수 있다.
장점:
- 간단하고 쉽게 구현할 수 있습니다.
- 일시적인 장애에서 데이터 일관성을 유지할 수 있습니다.
단점:
- 너무 자주 Retry하면 서버 부하가 증가할 수 있다.
- 실패가 지속될 경우 일정 시간 후에 Retry를 중단하는 로직을 추가해야 한다.
Write-Ahead Logging (WAL)
- NoSQL에서는 WAL을 통해 데이터의 변경 이력을 로그 파일에 저장하는 방식을 사용하기도 한다.
- 이를 통해 장애 발생 시 로그 파일을 복구하여 데이터 일관성을 유지할 수 있다.
장점:
- 데이터 일관성을 보장할 수 있습니다.
- 장애 발생 시 로그 파일을 이용하여 데이터를 복구할 수 있다.
단점:
- 로그 파일 용량이 증가하여 저장소 부하가 증가할 수 있다.
- 로그 파일을 정기적으로 삭제하지 않으면 디스크 용량을 차지할 수 있다.
Replication
- Replication을 통해 데이터를 다중 노드에 분산하여 저장하는 방식을 사용할 수 있다.
- 이때, 하나의 노드에서 장애가 발생하더라도 다른 노드에서 insert를 처리할 수 있으므로
일시적인 장애에도 대응할 수 있다.
장점:
- 데이터의 안정성을 보장할 수 있습니다.
- 다중 노드를 이용하여 처리 성능을 향상시킬 수 있다.
- 노드 간의 데이터 복제를 통해 데이터 일관성을 유지할 수 있다.
단점:
- 노드 간의 동기화에 대한 부하가 발생할 수 있다.
- 분산 환경에서는 복제에 따른 불일치가 발생할 수 있다.
파이프라인으로 장애 대응
DB에서 제공하는 장애 대응 기능도 오류가 발생한다고 가정해보자.
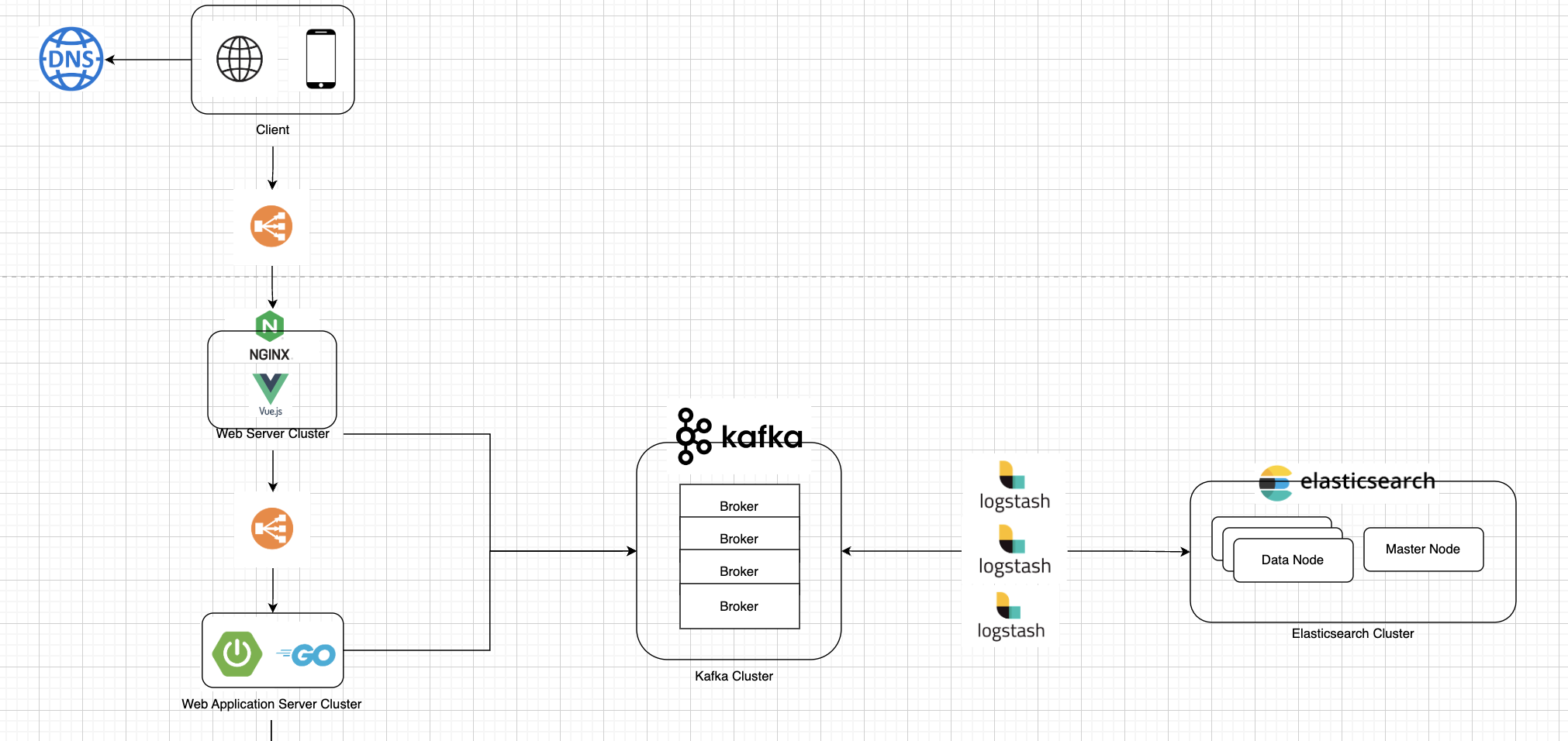
이럴 경우에는 Kafka와 ElasticSearch를 일시적으로 사용할 수 있다.
Nginx 또는 WAS에서 이벤트를 발생시키면, Kafka와 ElasticSearch에 일시적으로 데이터를 저장할 수 있다.
Kafka와 ElasticSearch에서 데이터를 가져와서 복구하는 방법도 적용할 수 있을 것 같다.
