초록스터디 프로젝트를 진행하던 중 100만개의 데이터를 처리할 수 있는가 라는 요구사항을 받게 되었다.
우리가 진행하는 프로젝트는 일정 관리를 도와주는 프로젝트로 여러가지 데이터들이 있었다. 데이터를 넣어야 하는 항목에는 Team, User, Project, Team_Member, Plan, Do 이렇게 총 6개가 있었다.
나머지는 이름만 봐도 알 수 있을것 같아 설명은 생략하고 Plan과 Do에 대해 간단히 설명해보자면 Plan은 해야하는 작업의 큰 가지이고 Do 는 Plan의 상세 내용으로 이해하면 될 것 같다.
예를 들어 Plan을 책 읽기 로 정하고 기간을 2025-02-21 ~ 2025-02-28로 설정해주면 Do는 2025-02-21 : 30페이지 읽기 이런식으로 Plan에 대한 하루하루의 실천사항을 쓰는 형식이다
개념 설명은 이 정도로 하고 이제 이 데이터들을 DB에 100만개를 넣어주어야 다음 작업인 100만개의 데이터를 처리할 수 있는가에 대한 처리를 할 수 있다. 그래서 회의를 통해 데이터들의 적정 비율을 계산해줬다
데이터 비율
위에서 말한것처럼 넣어야 하는 데이터는 Team : User : Project : Team_Member : Plan : Do 이다. 1개의 Team은 6명의 Team_Member를 가지고 1개의 Project를 가진다. 그리고 1개의 Project는 80개의 Plan을 가지고 1개의 Plan은 6개의 Do를 가진다.
이렇게 비율을 정하게 된 계기는 그 동안 해 왔던 프로젝트나 만다라트 등 여러가지를 참고했다

그렇게 정하게 된 비율이 아래의 비율이다!
Team : User : Project : Team_Member : Plan : Do
1 : 6 : 1 : 6 : 80 : 480
이렇게 하면 한 프로젝트 당 데이터의 개수는 574개가 나온다. 내가 원하는 100만개의 데이터에 비하면 턱없이 부족한 수치이다
574개의 데이터로 100만개를 만들려면 1,000,000 ➗ 574 = 1742.16... → 1743개의 프로젝트가 필요하다
SQL문을 만들어서 1743번 수동으로 반복하는 방법이 있지만 그러기는 싫다..
그래서 알아본 방법이 Batch Insert 이다!
Batch Insert
JPA를 사용하여 많은 데이터들을 넣게 되면 장점도 있긴 하지만 단점도 존재한다
JPA를 사용할 경우
- 장점
- 개발자가 SQL을 직접 다루지 않아도 됨
- 유지보수 및 확장 용이
- DBMS에 독립적 → 호환성 좋음
- 단점
- JDBC에 비해 느림
- 복잡한 쿼리를 작성하기 어렵고 쿼리 튜닝이 힘들어 최적화에 제한이 있을 수 있음
JDBC
- 장점
- 성능 최적화와 쿼리 튜닝에 유리, 복잡한 SQL 쿼리에 자유로움
- DB와 직접 연결 → 빠름
- 영속화 과정 X
- 단점
- 쿼리 문법에 대한 이해 필요
- DBMS마다 쿼리 문법이 달라 호환성 문제가 발생할 수 있음
이렇게 각 방식의 장단점이 있는데 빠른 데이터 삽입을 위해 JDBC를 이용한 Batch Insert 를 진행하기로 했다
코드를 보여주기에 앞서 설명이 필요하다. 위에 말한대로 6개 종류의 데이터를 넣는데 선행이 필요한 데이터가 있고 없는 데이터도 있다.
- 처음에 1개의
Team과 6명의User를 집어 넣음 - 그 이후의 데이터들은 선행 관계를 가짐
Team_Member→Project→Plan→Do의 순서
- 이 과정에서
Plan을 생성할때 해당 반복에서 생성된Team_Member로 생성하도록 함 - 같은 값만 들어가면 검색을 할 때 의미가 없을 것 같아서 약간의 랜덤성 추가
- 모두 보고 싶으면 전체가 들어가 있는 키워드(
Do,Plan,Description같은)를 보면 되고 그 외에는 단어는 아닌 랜덤한 문자열 검색
- 모두 보고 싶으면 전체가 들어가 있는 키워드(
위의 설명이 코드의 설명이다
package com.example.braveCoward.batchinsert;
import lombok.RequiredArgsConstructor;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.UUID;
@Service
@RequiredArgsConstructor
public class DataInsertService {
private final JdbcTemplate jdbcTemplate;
private final Random random = new Random();
public void insertLargeData(int numTeams) {
List<Object[]> teamBatch = new ArrayList<>();
List<Object[]> userBatch = new ArrayList<>();
List<Object[]> teamMemberBatch = new ArrayList<>();
List<Object[]> projectBatch = new ArrayList<>();
List<Object[]> planBatch = new ArrayList<>();
List<Object[]> doBatch = new ArrayList<>();
// team 데이터 삽입
for (int t = 0; t < numTeams; t++) {
String teamName = "Team-" + UUID.randomUUID().toString().substring(0, 8);
String teamDesc = "This is " + teamName;
LocalDateTime createdAt = randomDateTime();
LocalDateTime updatedAt = createdAt.plusDays(random.nextInt(30));
teamBatch.add(new Object[]{teamName, teamDesc, createdAt, updatedAt});
}
batchInsert("INSERT INTO team (name, description, created_at, updated_at) VALUES (?, ?, ?, ?)", teamBatch);
teamBatch.clear();
// team_id 가져오기
List<Long> teamIds = getInsertedIds("team", numTeams);
// user 데이터 삽입
for (int i = 0; i < numTeams * 6; i++) {
String userName = "User-" + UUID.randomUUID().toString().substring(0, 6);
String email = userName.toLowerCase() + "@example.com";
LocalDateTime createdAt = randomDateTime();
LocalDateTime updatedAt = createdAt.plusDays(random.nextInt(30));
userBatch.add(new Object[]{"password123", userName, email, createdAt, updatedAt, false});
}
batchInsert("INSERT INTO user (password, name, email, created_at, updated_at, is_deleted) VALUES (?, ?, ?, ?, ?, ?)", userBatch);
userBatch.clear();
// user_id 가져오기
List<Long> userIds = getInsertedIds("user", numTeams * 6);
// team_member 데이터 삽입
int userIndex = 0;
for (Long teamId : teamIds) {
for (int u = 0; u < 6; u++) {
LocalDateTime createdAt = randomDateTime();
LocalDateTime updatedAt = createdAt.plusDays(random.nextInt(30));
teamMemberBatch.add(new Object[]{teamId, userIds.get(userIndex), "Member", "Developer", createdAt, updatedAt});
userIndex++;
}
}
batchInsert("INSERT INTO team_member (team_id, user_id, role, position, created_at, updated_at) VALUES (?, ?, ?, ?, ?, ?)", teamMemberBatch);
teamMemberBatch.clear();
// `project` 데이터 삽입
List<Long> projectIds = new ArrayList<>();
for (Long teamId : teamIds) {
String projectTitle = "Project-" + UUID.randomUUID().toString().substring(0, 5);
String projectDesc = "Description for " + projectTitle;
LocalDateTime startDate = randomDateTime();
LocalDateTime endDate = startDate.plusDays(random.nextInt(30));
LocalDateTime createdAt = randomDateTime();
LocalDateTime updatedAt = createdAt.plusDays(random.nextInt(30));
projectBatch.add(new Object[]{teamId, projectTitle, projectDesc, startDate, endDate, 0.0, createdAt, updatedAt});
}
batchInsert("INSERT INTO project (team_id, title, description, start_date, end_date, progress, created_at, updated_at) VALUES (?, ?, ?, ?, ?, ?, ?, ?)", projectBatch);
projectIds.addAll(getInsertedIds("project", numTeams));
projectBatch.clear();
// plan 데이터 삽입
List<Long> planIds = new ArrayList<>();
// 팀 멤버 ID 가져오기
List<Long> teamMemberIds = getInsertedIds("team_member", numTeams * 6);
for (Long projectId : projectIds) {
for (int p = 0; p < 80; p++) {
String planTitle = "Plan-" + UUID.randomUUID().toString().substring(0, 5);
String planDescription = "Description - " + UUID.randomUUID().toString().substring(0, 10);
LocalDate startDate = LocalDate.now();
LocalDate endDate = startDate.plusDays(random.nextInt(30));
LocalDateTime createdAt = randomDateTime();
LocalDateTime updatedAt = createdAt.plusDays(random.nextInt(30));
// 랜덤한 팀 멤버 선택
Long randomTeamMemberId = teamMemberIds.get(random.nextInt(teamMemberIds.size()));
planBatch.add(new Object[]{projectId, randomTeamMemberId, planTitle, planDescription, startDate, endDate, "NOT_STARTED", createdAt, updatedAt});
}
}
batchInsert("INSERT INTO plan (project_id, team_member_id, title, description, start_date, end_date, status, created_at, updated_at) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)", planBatch);
planIds.addAll(getInsertedIds("plan", numTeams * 80));
planBatch.clear();
// do 데이터 삽입
for (Long planId : planIds) {
for (int d = 0; d < 6; d++) {
LocalDate date = LocalDate.now().minusDays(random.nextInt(30));
String description = "Do " + UUID.randomUUID().toString().substring(0, 5);
LocalDateTime createdAt = randomDateTime();
LocalDateTime updatedAt = createdAt.plusDays(random.nextInt(30));
doBatch.add(new Object[]{planId, date, description, false, createdAt, updatedAt});
}
}
batchInsert("INSERT INTO do (plan_id, date, description, is_completed, created_at, updated_at) VALUES (?, ?, ?, ?, ?, ?)", doBatch);
doBatch.clear();
System.out.println("랜덤 데이터 삽입 완료!");
}
private void batchInsert(String sql, List<Object[]> batchList) {
jdbcTemplate.batchUpdate(sql, batchList);
}
private List<Long> getInsertedIds(String tableName, int limit) {
return jdbcTemplate.queryForList("SELECT id FROM " + tableName + " ORDER BY id DESC LIMIT ?", Long.class, limit);
}
private LocalDateTime randomDateTime() {
return LocalDateTime.now().minusDays(random.nextInt(365));
}
}위의 코드로 1개 프로젝트에 해당하는 데이터를 넣어줬다 → 574개
프로젝트 기능중에 검색 기능도 있어 랜덤 요소를 추가해줬는데 나중에 들어보니 이런 방식으로 랜덤값을 넣는 것보다 다른 툴로 좀 더 실제에 가까운 랜덤한 값을 넣을 수 있다고 한다. 다음에 시도할 때는 해당 방식을 사용해 봐야겠다
시간 측정
서버에 직접 넣기에 앞서 로컬에서 우선 실행을 시켜봤다
내 로컬 환경은 맥북 에어 M2 16gb 이다
실행을 해보니 생각보다 오래 걸리는 것을 볼 수 있었다
반복문을 통해 처음 프로그램 실행 시 1743번의 데이터를 넣는데에 약 133s가 걸리는 것을 확인했다
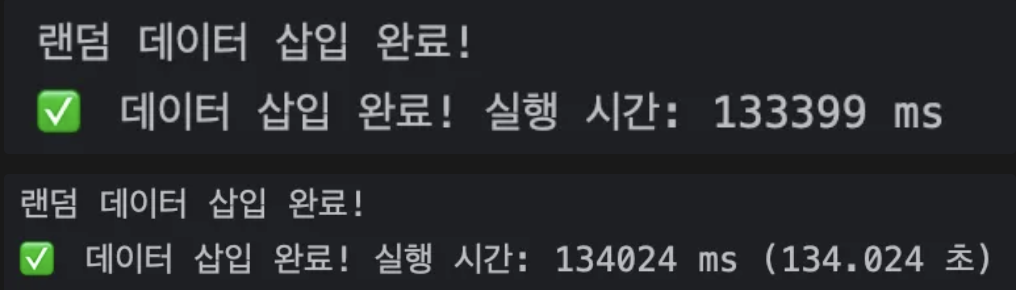
서버는 AWS EC2의 프리티어를 쓰고 있어 훨씬 더 오래걸릴 것이 분명했다. 윈도우 노트북을 사용하는 팀원에게 요청을 했더니 1시간이 걸려도 끝나지 않아서 도중에 중단한 적도 있다
그래서 좀 더 수정해야할 요소를 찾아보다가 rewriteBatchedStatements라는 요소를 발견했다
기본 값은 false로 되어 있고 yml 파일에서 url 부분에 &rewriteBatchedStatements=true를 추가해줬다
해당 값을 true로 바꿔주면 insert 쿼리가 개별적으로 실행되는 것이 아니라 합쳐져서 한번에 실행되는 것을 볼 수 있었다
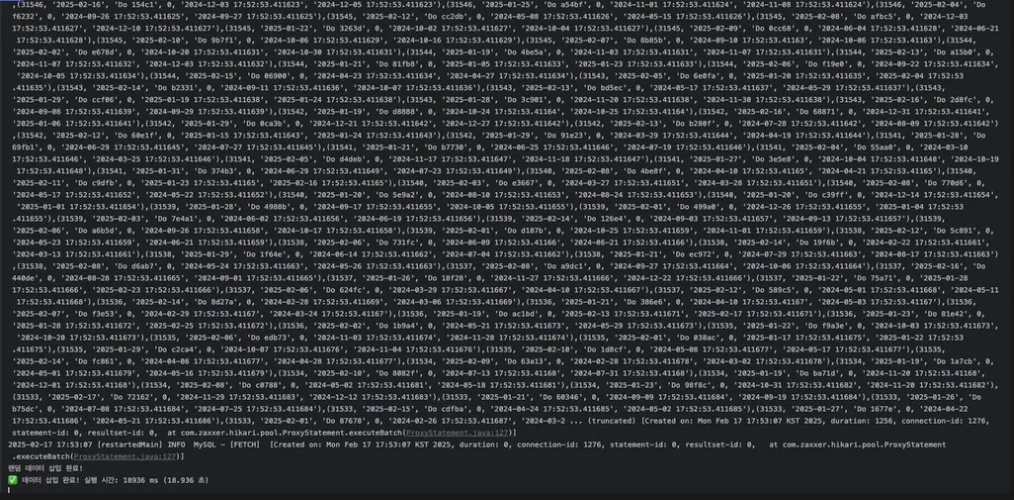
위의 사진처럼 한번에 날아가는 것을 볼 수 있다
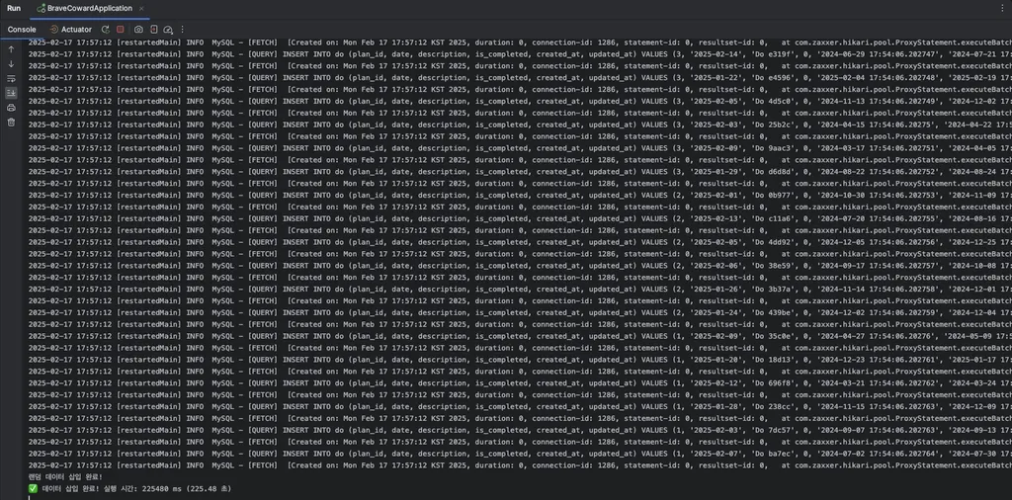
만약 false라면 아래 사진처럼 개별적인 쿼리가 날아간다
저 구문을 추가해주고 다시 시간 측정을 해봤더니 시간단축이 많이 됐다

133s 에서 19s로 데이터 삽입 시간이 굉장히 많이 단축된 것을 볼 수 있다 👍
윈도우 노트북에서는 약 7분정도 걸려서 들어갔다!
서버에 데이터 넣기
이제 로컬에서 실험을 해봤으니 서버에 넣을 차례이다
위에서 말한것처럼 프로그램을 실행할 때 서버에 들어가게 해놓다보니 재배포 할 떄마다 다시 들어가는 상황이 발생할것 같아서 yml값을 통해 관리를 해주려고 했는데 다른 팀에 있는 친구가 api로 따로 빼서 하는 것을 보고 나도 api를 이용해서 데이터를 넣는 방식으로 고쳤다!
왜 이생각을 못했지..
암튼 고치고 파라미터로 몇 회 넣을것인지를 받아 데이터를 넣을 수 있게 되었다
그 다음에 서버에 배포를 하고 실행을 시켜보니 서버가 터졌다!!!!!!!!!!
그럴 것 같긴 했지만 진짜 터졌다.. 아무래도 1743번을 한번에 넣으려다보니 프리티어 서버가 견디지 못한 것 같다
그래서 1743번을 500번, 500번, 500번, 243번으로 나눠 넣으니 다행히 들어간 것을 볼 수 있었다
서버에 데이터를 넣고 DB의 개수를 확인해 봤따
SELECT COUNT(*) FROM 테이블명;
- Team

- User

- Team_Member

- Project

- Plan

- Do
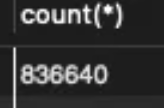
데이터가 다들 잘 들어간 것을 볼 수 있다
후기
이제 대용량 데이터 처리를 위한 기초 작업을 할 수 있게 되었다.
JPA 를 이용한 방식도 해보고 둘의 방식을 한 번 비교해봐야겠다
방법을 한 번 익혀놨으니 다음 작업이 수월하기를..
