프로세스와 쓰레드
디스크에 저장된 프로그램이 실행되어 메모리에 load되어 CPU에게 자원을 할당받은 상태
구성
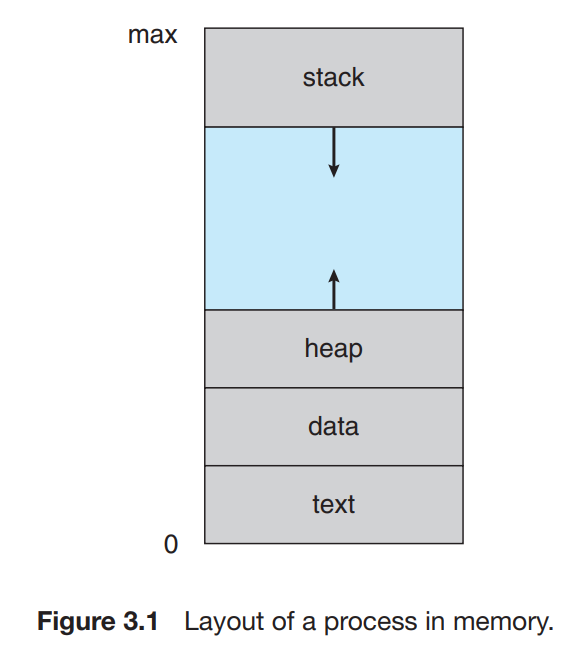
- Stack: 매개변수, 리턴 변수, 복귀주소(PC Counter),지역 변수 저장되어 있는 영역
- heap: 동적 할당에 사용되는 영역
- data: 전역변수가 저장된 영역
- Code: 프로세스가 실행하는 코드 자체가 들어있는 영역
각 프로세스마다 별도의 주소 공간에서 실행되며, 한 프로세스는 다른 프로세스의 변수나 자료구조에 접근할 수 없다. 접근하기 위해선 프로세스 간의 통신(Inter-Process Communication)을 사용해야 한다.
상태
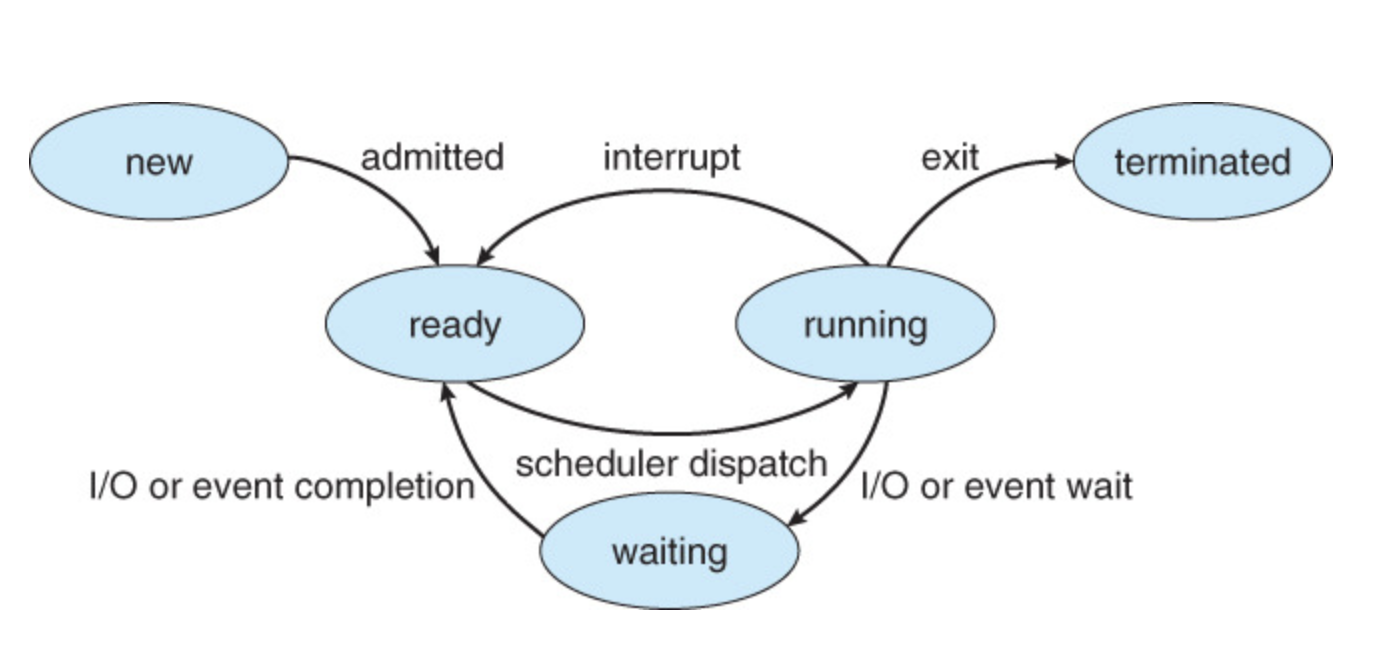
- New: 프로세스가 처음 생성되었을 때.
- Ready: 프로세스가 프로세서에 할당되기를 기다릴 때.
- Running: 프로세스가 할당되어 실행될 때.
- Waiting: 프로세스가 이벤트를 기다릴 때.
- Terminated: 프로세스가 실행을 마쳤을 때.
PCB(Process Control Block)
운영체제가 프로세스를 제어하기 위해 정보를 저장해 놓는 곳으로, 프로세스의 상태 정보를 저장하는 구조체이다.
프로세스 생성 시 만들어지며 주기억장치에 유지된다.
프로세스 고유의 중요한 정보를 가지고 있으며 프로세스 상태와 프로그램 카운터, 메모리 한계, 레지스터 정보 등이 담겨있다.
- 프로세스 식별자(PID)
- Process State: 프로세스 상태(New, Ready, Running, Waiting, Terminated)
- Program Counter: 프로세스가 다음에 실행할 명령의 주소를 가리키는 카운터
- Register: Accumulator, CPU Register, General Register 등을 포함한다.
- Scheduling Infomation: 프로세스 중요도, 스케쥴링 큐 포인터 등의 정보를 포함한다.
- Memory-management Information: 메모리 base, limit 레지스터값, 페이지 테이블 등 메모리 시스템 정보
- Accounting Information: 사용된 CPU 총량, 프로세스 개수, 시간 제한 등
- I/O Status Information: 프로세스에 할당된 입출력 장치 목록, 열린 파일 목록 등
Q. PCB가 필요한 이유는?
👉🏻 CPU가 작업중인 프로세스를 중단하고 다시 작업을 시작하기 위해서이다. 수행중인 프로세스에 대한 정보의 값을 PCB에 저장해둔다.(Context Switching)Q. PCB는 어떻게 관리가 되나요?
👉🏻 LinkedList 방식으로 관리가 된다. PCB List Head에 PCB들이 생성될 때마다 추가되어 붙고 LinkedList로 되어서 삽입/삭제에 용이하다.Context Switching
CPU는 한번에 하나의 프로세스만 실행할 수 있다. CPU에서 여러 프로세스가 돌아가면서(Interrupted) 작업을 처리하는 과정을 Context Switching이라 한다.
스위칭이 발생하면 실행중이던 프로세스 정보들을 PCB에 저장하고, 대기하고 있던다음 순서의 프로세스가 동작하면서 이전에 보관했던 프로세스의 상태를 복구하는 것을 말한다.
프로세서 입장에서 Context는 PCB이므로 PCB정보가 바뀌는 것을 컨텍스트 스위치라고 한다.
인터럽트(Interrupt)
장치 컨트롤러는 CPU에게 이벤트 발생을 알리는데, 이벤트 발생을 알리는 것을 인터럽트(Interrupt)라고 한다.
보통 컴퓨터는 여러 작업을 동시에 처리하는데, 이때 당장 처리해야 하는 일이 생겨서 기존에 작업을 중단하는 경우 인터럽트를 신호를 보낸다.
인터럽트는 하드웨어나 소프트웨어에 의해 발생할 수 있다.
운영체제는 대부분 인트럽트 주도적(Interrupt driven)이다. 만약 인터럽트가 없다면, 컨트롤러는 특정한 일이 발생하였는지 비효율적으로 자주 체크해야 한다.
폴링(Polling)은 주기적으로 이벤트를 감시해 처리 루틴을 실행한다. 이렇게 하면 컴퓨터 자원이 매우 낭비되므로 인터럽트 주도적으로 설계하는 것이다.
스레드(Thread)
CPU 사용의 기본단위로, 프로세스 내에서 실행되는 여러 흐름 단위이다.
구조
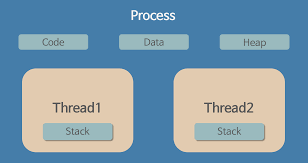
프로세스 내부에 하나 이상의 쓰레드가 존재하며 Code,Data,Heap을 프로세스 내부에서 공유한다. 반면에 프로세스는 다른 프로세스 메모리에 직접 접근할 수 없다.
Stack과 레지스터는 스레드마다 독립적으로 존재한다.
Q. 스레드마다 스택이 독립적으로 존재하는 이유는?
👉🏻 스택에는 함수의 매개변수, 리턴값, 지역변수, 리턴 주소등이 저장되는 영역입니다. 스택을 스레드마다 독립적으로 존재한다는 것은 독립적으로 함수 호출이 가능이 가능하고 독립적으로 실행 흐름을 추가할 수 있다는 말이다.
Q.스레드마다 레지스터가 독립적으로 존재하는 이유는?
👉🏻 PC값은 스레드의 명령어가 어디까지 수행했는지 나타나는데, 스레드는 CPU를 할당받았다가 스케줄러에 의해 선점됩니다. 그렇기 때문에 어느 부분까지 수행했는지 기억하기위해 PC 레지스터가 존재하는데, 위에서 보았듯이 스레드는 독립적인 실행 단위이므로 독립적인 레지스터가 필요합니다.
멀티 프로세스(Multi Process)와 멀티 쓰레드(Multi Thread)
멀티 프로세스
두개 이상의 프로세스가 하나 이상의 작업(Task)를 동시에 처리하는 것이다.(병렬처리)
장점
- 프로세스에 문제가 발생해도 다른 프로세스에 영향을 주지 않아 작업 속도는 느려지는 손해가 발생해도 정지되는 문제가 발생하지는 않는다 (독립된 구조로 안정성이 높다)
단점
- 각각의 독립된 메모리 영역을 갖고 있어 작업량이 많을 수록 오버헤드 발생하여 성능 저하
- Context Switching 과정에서 캐시 메모리 초기화 등 무거운 작업이 진행되고 시간이 소모되는 오버헤드 발생
- 프로세스는 독립된 메모리 영역을 할당받아서 프로세스 끼리 통신하기 위해서 복잡한 통신 기법 IPC를 사용해야 한다.
멀티 스레드
하나의 응용 프로그램을 여러개의 스레드를 할당하여 처리하는 방식
장점
- 독립적인 프로세스에 비해서 자원을 별도로 할당할 필요가 없어 자원소모 측에서 멀티 프로세스보다 효율적이다. (스레드간 통신시 전역 혹은 Heap 영역을 이용하여 데이터를 주고 받는다.)
- 스레드간 데이터를 주고 받는 것이 간단해지고 시스템 자원 소모가 줄어든다. 또한 스레드 사이의 작업량이 작아 Context Swtching이 빠르다.
- Stack을 제외한 모든 메모리르 공유하고 있어서 통신 부담이 적다.
단점
- 다수의 스레드가 공유된 자원을 접근할 때 동기화 문제가 발생할 수 있다( 병목 현상, 데드락 등)
- 하나의 스레드에 문제가 생기면 전체 프로세스가 영향을 받는다.
멀티 프로그래밍
다수의 프로세스를 메모리에 적재하여 프로세스를 번갈아가면서 처리하는 것
멀티 태스킹
다수의 작업을 운영체제 스케줄링에 의해 번갈아가면서 처리하는 것.
