
oracle 8장
새 행 삽입
INSERT INTO departments (department_id, department_name, manager_id, location_id)
VALUES (70, 'Public Relations', 100, 1700);문자 및 날짜 값은 작은 따옴표로 묶는다.
다른 테이블에서 행 복사
INSERT INTO sales_reps(id, name, salary, commission_pct)
SELECT employee_id, last_name, salary, commission_pct
FROM employees
WHERE job_id LIKE '%REP%';values 절은 사용하지 않는다.
insert 절의 열 수와 서브 쿼리의 열 수를 일치시킨다.
테이블의 행 갱신
UPDATE employees
SET department_id = 70
WHERE employee_id = 113;서브 쿼리로 두 열 갱신
UPDATE employees
SET job_id = (SELECT job_id
FROM employees
WHERE employee_id = 205),
salary = (SELECT salary
FROM employees
WHERE employee_id = 205)
WHERE employee_id = 114;테이블에서 행 삭제
DELETE FROM departments
WHERE department_name = 'Finance';
다른 테이블을 기반으로 행 삭제
DELETE FROM employees
WHERE department_id = (
SELECT department_id
FROM departments
WHERE department_name LIKE '%Pblic%');🎈 조인 : 여러 테이블 걸쳐서 검색
오라클 전용
🎈 primary key는 중복되지도 않고 값을 꼭 가져야 하는 키이다.
표준
select 컬럼명, 컬럼명
fron t1 natural join t2;
select 컬럼명, 컬럼명
fron t1 natural join t2
using 조인컬럼;
select 컬럼명, 컬럼명
fron t1 natural join t2
on 조인 조건
where 행 조건;
SQL 명령어 종류
데이터 질의어 - select
DDL - 데이터 정의어
db 객체 생성, 수정, 삭제 (테이블 자체를, 테이블 구조를)
create table, alter table, drop table ...
DDL 명령어 하나가 트랜잭션 하나이다.
DML - 데이터 조작어
추가, 수정, 삭제 (데이터를)
insert, update, delete ...
DCL - 데이터 제어어.
grant, revoke
권한 부여, 빼앗는 명령어
수업
-- 4-6) 정답
select e.last_name employee, e.employee_id emp#,
m.last_name manager, m.employee_id
from employees e, employees m
where e.manager_id = m.employee_id;
-- 4-7) 정답
select e.last_name employee, e.employee_id emp#,
nvl(m.last_name,' ')as manager, m.employee_id
from employees e, employees m
where e.manager_id = m.employee_id(+);
-- 4-8) 정답
select e.department_id as department, e.last_name as employee, c.last_name as colleague
from employees e, employees c
where e.department_id = c.department_id
and e.employee_id <> c.employee_id
order by e.department_id, e.last_name;
-- 5-10) 정답
select department_name as name, location_id as location,
count(*) as "number of people", round(avg(e.salary),3) as salary
from departments d, employees e
where d.department_id = e.department_id
group by department_name, location_id;
-- 5-11)
/* decode 함수는 오라클 쿼리에서 가장 많이 사용하는 함수 중 하나이다.
프로그래밍에서의 if else와 비슷한 기능을 수행한다.
DECODE(컬럼, 조건1, 결과1, 조건2, 결과2, 조건3, 결과3.......)
*/
select count(to_char(hire_date, 'YYYY')) as total,
count(decode(to_char(hire_date, 'YYYY'),'2005',1))as "2005",
count(decode(to_char(hire_date, 'YYYY'),'2006',1))as "2006",
count(decode(to_char(hire_date, 'YYYY'),'2007',1))as "2007",
count(decode(to_char(hire_date, 'YYYY'),'2008',1))as "2008"
from employees;
select sum(case to_char(hire_date, 'yyyy') when '2005' then 1 else 0 end) "2005"
from employees;
-- 5-12)
select job_id job,
(select sum(salary) from employees where department_id = '20') as "Dept 20",
(select sum(salary) from employees where department_id = '50') as "Dept 50",
(select sum(salary) from employees where department_id = '80') as "Dept 80",
(select sum(salary) from employees where department_id = '90') as "Dept 90",
sum(salary) as total
from employees
group by job_id;
-- 5-12) 정답 1
select job_id,
sum(case department_id when 20 then salary else 0 end ) "Dept 20",
sum(case department_id when 50 then salary else 0 end ) "Dept 50",
sum(case department_id when 80 then salary else 0 end ) "Dept 80",
sum(case department_id when 90 then salary else 0 end ) "Dept 90",
sum(salary) total
from employees
group by job_id;
-- 5-12) 정답 2
select job_id,
sum(decode(department_id, 20, salary, 0)) "Dept 20",
sum(decode(department_id, 50, salary, 0)) "Dept 50",
sum(decode(department_id, 80, salary, 0)) "Dept 80",
sum(decode(department_id, 90, salary, 0)) "Dept 90",
sum(salary) total
from employees
group by job_id;employees 구조만 복사해서 emp 만들기
create table emp
as
select employee_id emp_id, last_name name, salary , hire_date, department_id dept_id
from employees
where 1 = 0;줄은 복사하지 말라고 1=0을 넣어줬다.
그래야 false가 되어서 들어가게 되니까
이 where 1=0 이 없다면 다른 줄들도 복사가 된다.
insert into emp values (4, 'aaaa', 5000, sysdate, 10 );
insert into emp values (3, 'cccc', null, sysdate, null);
insert into emp (emp_id, name, hire_date) values (2, 'bbbb', sysdate);다른 테이블에서 꺼내와서 현재 테이블에 넣기
insert into emp
select employee_id, last_name, salary, hire_date, department_id
from employees
where job_id like '%REP%';프라이머리 키로 삭제하고 수정을 하면 된다.
update emp set salary = 3000 where emp_id = 3;한 번에 여러개 수정도 가능하다
update emp set emp_id=10, salary = 3500, hire_date='12/08/23', dept_id=40
where emp_id=1;
update emp set salary = 4000, dept_id = 40
where emp_id=2;
update emp set dept_id = 80
where emp_id=3;emp_id가 10인 사람의 id와 salary를 employees의 id가 205와 동일하게 바꿈
update emp
set dept_id = (select dept_id from employees where employee_id = 205),
salary = (select salary from employees where employee_id =205)
where emp_id = 10;
delete from emp where emp_id = 10;트랜잭션을 쓰기 완료.
commit;
-- 새 트랜잭션 실행
delete from emp;
-- 롤백 가능
rollback;
-- 현재 트랜잭션의 쓰기 작업을 취소. 실행하면 '롤백 완료'
-- 부서번호 80인 사람 삭제
delete from emp
where dept_id=80;삭제할 때 주의해야 함 외래키 부분
select * from departments;
insert into departments values (280, 'dept1', 1000, 3000);
insert into emp values(11, 'abc', 1000, sysdate, 100);merge 문
데이터베이스 테이블에서 조건에 따라 데이터를 갱신하거나 삽입하는 기능을 제공한다.
해당 행이 존재하는 경우 update를 수행하고, 새로운 행일 경우 insert를 수행한다.
별도의 갱신을 수행할 필요가 없다.
성능이 향상되고 사용하기가 편리하다.
데이터 웨어하우징 응용 프로그램에 유용하다.
JDBC
java databases connectivity interface
오라클용 드라이버 추가
-
드라이버 로드.
드라이버 로드해야 api가 인식이 되기 때문에
-
db에 커넥트(로그인)
-
sql 작성
String sql = "insert into test calues(1, 'minhyun')";그냥 하나의 문자열이기 때문에 String에다가 담는다.
- PreparedStatement 객체 생성
(sql문은 오라클이 인식, java는 sql 인식을 못한다.)
자바에서 sql문을 실행하려면 이를 처리할 객체가 필요
❓ 그거 누가 해주는건데 ❓
→ PreparedStatement 가!!
PreparedStatement pstmt = conn.preparedStatement(sql);-
검색/수정/삭제 등의 sql문 실행
(읽기/쓰기 작업 메소드가 다르다)
-
쓰기 (추가(insert)/수정(update)/삭제(delete))>
int num = pstmt.excuteUpdate(); // sql 실행, 적용된 줄수- conn을 닫는다.
conn.close(); // db 연결 끊음executeUpdate 메서드
데이터베이스에서 데이터를 추가(insert), 삭제(delete), 수정(update)하는 SQL문을 실행한다.
executeQuery 메서드
데이터베이스에서 데이터를 가져와서 결과 집합을 반환한다.
이 메서드는 Select 문에서만 실행하는 특징이 있다.
오류 정리
java.sql.SQLIntegrityConstraintViolationException
→ 무결성 제약조건에 위배되는 예외이다.
원인
무결성 제약 조건에 위배되는 SQL 작성 시 발생
해결 방안
SQL에서 중복열을 제거한다.
SQL에서 무결성 제약조건에 위배되는 행위를 하지 않는다. (중복 PK 삽입 등)
🎈 오늘의 숙제 🎈
create table member(
id varchar2(20) primary key,
pwe varchar2(20) not null,
name varchar2(20),
email varchar2(50)
);
member 클래스로다가 vo, dao, main 클래스를 만드시오
3명 추가
1명 id로 찾아서 수정 (pwd, name)
1명 id로 찾아서 삭제
Java & Oracle 연결
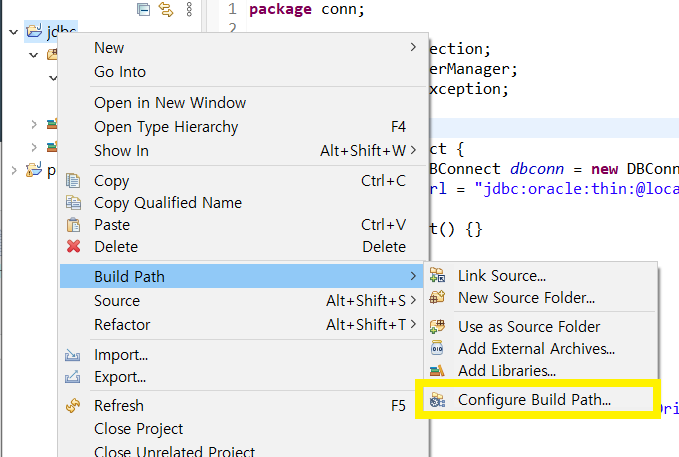
프로젝트(우클릭) → Build Path → Configure Build Path
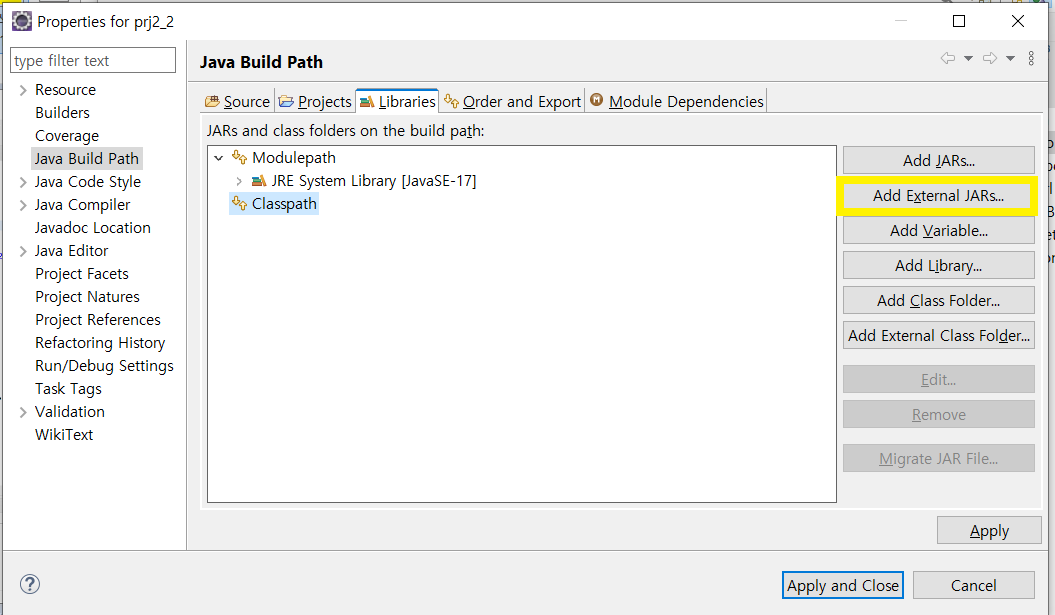
Classpath(클릭) → Add External JARs...(클릭)
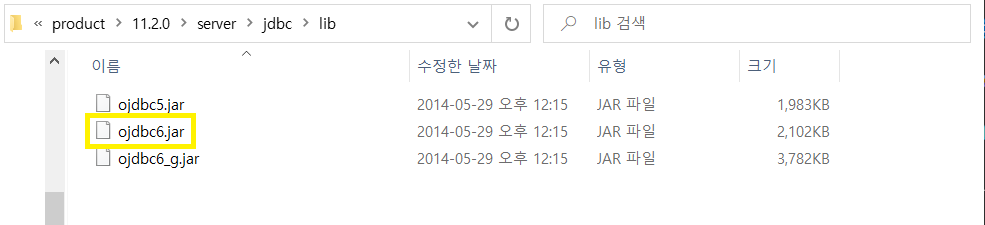
'C:\oraclexe\app\oracle\product\11.2.0\server\jdbc\lib'
이 곳에 있는 ojdbc6.jar(클릭)
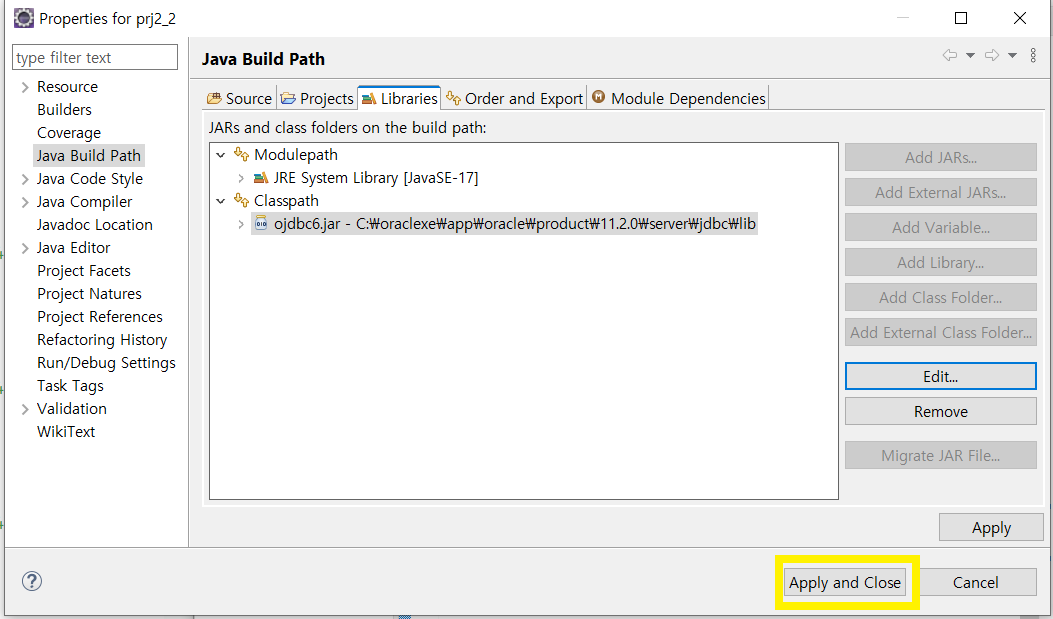
Apply and Close(클릭)
연결하는 소스코드
package dbconn;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
//싱글톤
public class DBConnect {
private static DBConnect dbconn = new DBConnect();
private String url = "jdbc:oracle:thin:@localhost:1521/xe";
private DBConnect() {}
public static DBConnect getInstance() {
return dbconn;
}
public Connection conn() {
try {
//드라이버 로드
Class.forName("oracle.jdbc.OracleDriver");
//세션수립
return DriverManager.getConnection(url, "hr", "hr");
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
}