
이 글은 MySQL에 대한 기초적인 정보를 담고 있습니다.
MySQL?
MySQL은 오픈소스 관계형 데이터베이스 중 하나로, 행과 열로 구성된 테이블에 데이터를 저장합니다.
일반적으로 SQL이라는 쿼리 언어를 통해 데이터를 정의하고, 조작하고, 또 제어 및 쿼리합니다.
관계형 데이터베이스?
데이터가 하나 이상의 열과 행의 테이브 또는 관계로 저장되어 서로 다른 데이터 구조가 어떻게 연관되어 있는지 쉽게 파악할 수 있도록 데이터를 구성하고 있는 정보 꾸러미라고 볼 수 있습니다.
SQL언어
: 관계형 데이터베이스를 제어하고 관리하는데 사용하는 유사 프로그래밍 언어 (프로그래밍 언어X)
SQL 언어는 기능에 따라 언어가 나뉩니다.
0. SQL 공통
# 데이터베이스 목록 보기
SHOW DATABASES;
# 데이터베이스 이용하기
USE 데이터베이스명
# 테이블 목록 보기
SHOW TABLES;
#테이블 구조 보기
DESC 테이블명;1. 데이터 정의어(DDL, Data definition Language)
: 데이터베이스 또는 테이블을 정의하는 언어입니다.
- Create: 데이터베이스, 테이블 등을 생성합니다.
- Drop: 데이터베이스, 테이블을 삭제합니다. (주의 사용)
- Truncate: 테이블을 초기화 시킵니다. (함수 truncate와 별개)
- Alter: 테이블을 수정합니다.
- CREATE TABLE
기본적으로 프로그래밍 언어는 영어 기반이기에 데이터베이스를 만들 때 한글 인코딩도 같이 해줘야합니다.
데이터베이스 만들기 + 한글 인코딩
CREATE DATABASE 이름 DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
테이블 만들기:
CREATE TABLE 테이블명 (
필드1 데이터 형식,
필드2 데이터 형식
);
예:
CREATE TABLE member (
id VARCHAR(10) NOT NULL PRIMARY KEY,
name VARCHAR(10) NOT NULL,
birthday DATE NOT NULL
);- DELETE OR TRUNCATE 테이블/컬럼 삭제/추가
특정 테이블을 지정해 삭제할 수 있습니다.
1. 테이블 삭제, 테이블을 잘못 만들었거나 더 이상 필요없는 경우
DROP TABLE 테이블명;
2. 테이블 초기화하기(체이블의 모든 행 삭제), 초기화해도 기록은 남음
TRUNCATE TABLE 테이블명; - ALTER
테이블의 특정 컬럼을 삭제하거나 추가할 수도 있습니다.
1. 컬럼 삭제
ALTER TABLE 테이블명 DROP COLUMN 컬럼명;
2. 컬럼 추가
ALTER TABLE 테이블명 ADD 컬럼명 타입
3. 컬럼 속성 변경
ALTER TABLE 테이블명 MODIFY 컬럼명 타입;2. ⭐데이터 조작어⭐(DML, Data Manipulation Language)
: 데이터베이스의 내부 데이터를 관리하기 위한 언어입니다.
- INSERT
-
INSERT : 데이터를 추가합니다.
INSERT는 CRUD에서 CREATE 기능을 담당합니다. -
필드1개씩 INSERT할 수도 있지만 아래처럼 한 번에 추가해주는 것도 가능합니다.
1. INSERT INTO 테이블명 (필드1, 필드2, 필드3) VALUES (값1, 값2, 값3);
2. INSERT INTO 테이블명 VALUES(값1, 값2, 값3);
2번의 경우 필드를 명시하고 있지 않으므로 테이블의 모든 컬럼에 값이 추가됩니다.
- SELECT
- SELECT : 데이터를 조회하거나 검색합니다.
SELECT는 질의어(query)라고도 하며 CRUD에서 READ 기능을 담당합니다.
SQL문 중에서 가장 많이 사용되는 문법이기도 합니다.
SELECT 속성이름, ... FROM 테이블이름 [WHERE 검색조건]
예:
SELECT address FROM customer WHERE custname='Kate';- UPDATE
UPADTE: 데이터를 수정합니다.
UPDATE 테이블명 SET 필드1=값1 WHERE 필드2=조건2;- DELETE
DELETE: 데이터를 삭제합니다.
DELETE를 실행하기 전 주의해야 합니다. 실행하더라도 '정말 삭제할 것인가?'라는 안내문구가 안 뜨기 때문에 신중하게 사용해야 합니다.
DELETE FROM 테이블명 WHERE 필드1=값1;- WHERE절 연산자 링크
- ORDER BY & WHERE
ORDER BY를 이용하면 정보 조작 순서를 조정할 수도 있습니다.
- 결과가 출력되는 순서 조절
WHERE절과 함께 사용 가능 (단, WHERE 절 뒤에 나와야 합니다ORDER BY: 1. ASC: Ascending, 오름차순(기본값) 2. DESC: Descending, 내림차순 예: SELECT 속성 이름, ... FROM 테이블 이름 [WHERE 검색 조건] [ORDER BY 속성 이름]
- DISTINCT
DISTINCT를 사용해 중복된 데이터를 제거할 수 있습니다.SELECT 속성 이름, ... FROM 테이블 이름 [WHERE 검색 조건] [ORDER BY 속성 이름]
- LIMIT
출력 개수를 제한할 때는
LIMIT을 사용합니다.SELECT 속성 이름, ... FROM 테이블 이름 [WHERE 검색 조건] [ORDER BY 속성 이름] [LIMIT 개수]
- 집계 함수
세밀하게 조작하고 싶다면
집계 함수를 사용하면 됩니다.(예) 1. SUM(): 합계 2. AVG(): 평균 3. MAX(): 최대값 4. MIN(): 최소값 5. COUNT(): 행 개수 COUNT(속성) -- NULL값 제외 COUNT(*) -- NULL값 포함 COUNT(DISTINCT) -- 중복 제외한 행 개수 7. truncate(): 버림 SELECT TRUNCATE(1234.1234, 1) FROM TABLE_1 -- 1234.1 SELECT TRUNCATE(1234.1234, 3) FROM TABLE_1 -- 1234,123 SELECT TRUNCATE(1234.1234, -1) FROM TABLE_1 -- 1230 8. round(): 반올림 SELECT ROUND(AVG(FEE), 1) FROM TABLE_1 -- 소수 첫째 자리까지 반올림 SELECT ROUND(AVG(FEE), -1) FROM TABLE_1 --- 일의 자리까지 반올림 SELECT ROUND(1234.1234) FROM TABLE_1 -- 1234 9. now(): 현재 시스템의 시간 10. date_fromat: 시간, 날짜 등을 원하는 형태로 표기할 때 SELECT DATE_FORMAT(NOW(), '%Y-%m-%d') as NOW_DATE -- NOW_DATE 컬럼에 현재 시각(2024-02-26 11:36:00)을 2024-02-06으로 변경하기 %Y -- 년도 4자리 표기 %y -- 년도 뒤에 2자리 표기 %M -- 영어로 월 표기 %m -- 숫자로 월 표기 %D -- %%th 로 날짜 표기 %d -- 숫자로 일 표기 %H -- 24시간 표기 (00 ~ 23) %h -- 12시간 표기 (00 ~ 12) %i -- 분 표기 %s -- 초 표기 11.IS NULL: 값이 NULL인 칼럼만 가져옴 12.IS NOT NULL: 값이 NULL인 칼럼은 제외 13.IFNULL('칼럼명', '대체할 값'): NULL 또는 비어있는 칼럼값에 대체값 입력
- GROUP BY & HAVING BY'
: 속성이름이 같은 것끼리 그룹으로_ 묶어서 조작하는 데 사용합니다.
GROUP BY: 속성이름끼리 그룹으로 묶어줍니다.
HAVING BY: GROUP BY 절의 결과를 나타내는 그룹의 조건을 걸어줍니다.
- JOIN (INNER & OUTER)
JOIN을 쉽게 말하면 집합입니다.아래의 그림처럼
INNER JOIN은 교집합,OUTER JOIN은 합집합과 비슷한 개념입니다.
테이블을 만약 결합하여 데이터를 조작하고 싶다면
join을 사용해주면 됩니다.
- 교집합
INNER JOIN:기본문법 SELECT 속성이름, ... FROM 테이블A INNER JOIN 테이블B ON 조인조건 WHERE 검색조건; -- 간단하게 적는 방법: SELECT 속성이름, ... FROM 테이블A, 테이블B WHERE 조인조건 AND 검색조건;예제
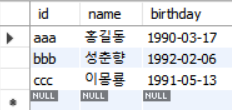
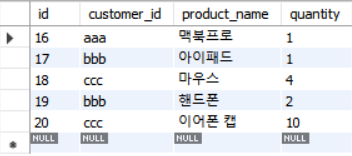
테이블이 두 개 있습니다.
table1: customer
table2: orderlist
두 테이블을
INNER JOIN해보겠습니다.SELECT * FROM customer INNER JOIN orderlist ON customer.id = orderlist.customer_id겹쳐진 부분은 합쳐지고 겹치지 않은 부분은 제외됩니다.
다만, 이 예제에서는 겹치지 않는 부분이 없으므로 제외된 데이터는 없습니다.
- 합집합
OUTER JOIN:기본문법 (INNER JOIN과 유사) SELECT 속성이름, ... FROM 테이블A INNER JOIN 테이블B ON 조인조건 WHERE 검색조건;예제
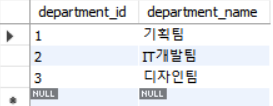
이번에도 테이블을 두개 만들어보겠습니다.
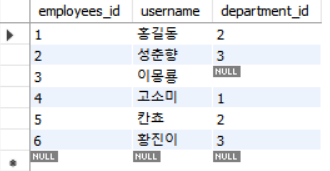
table1: departments
table2: employees
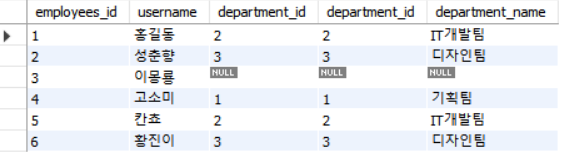
그리고 가장 왼쪽에 있는 칼럼을 기준으로 합쳐보겠습니다.
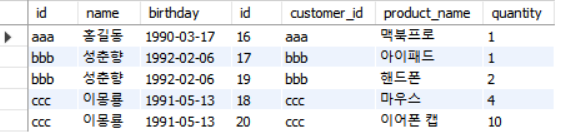
SELECT * FROM employees as a LEFT JOIN departments as b ON a.department_id = b.department_id이때 가장 왼쪽에 있는 모든 행을 조회합니다(1~6 순으로 정렬).
OUTER JOIN은 합집합이기에 employees 테이블에서이몽룡의 department_id값이NULL임에 따라 departments 테이블의 department_id 역시 null로 채워졌음을 확인할 수 있습니다.
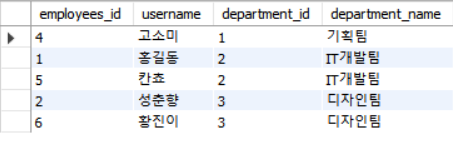
추가로 두 테이블을
INNER JOIN해보겠습니다.SELECT a.employees_id, a.username, a.department_id, b.department_name FROM employees as a INNER JOIN departments as b ON a.department_id = b.department_id;
INNER JOIN은 교집합이기에 두 테이블에서 겹치지 않은 '이몽룡'은 제외되고 합쳐졌음을 확인할 수 있습니다.

DML 예제 모음:
select * FROM kdt11.user WHERE age > 12; -- 나이가 12보다 많은 사람
select * FROM kdt11.user WHERE LENGTH(username) >= 3 ORDER BY age desc LIMIT 4;
select * FROM kdt11.user WHERE address LIKE 'coding%'; -- 주소에 '코딩'이 들어가는 사람
SELECT * FROM user WHERE username LIKE '____2'; -- 마지막 글자가 2인 사람, 기호 _ 는 알파벳 또는 한글 개수만큼 적어줘야
SELECT * FROM user WHERE age BETWEEN 10 AND 13; -- 나이가 10에서 13인 사람
SELECT * FROM user WHERE age IN (10, 14) ORDER BY username DESC; -- 나이가 10인 사람, 나이가 14인 사람
SELECT * FROM user WHERE address IS NOT NULL;
UPDATE user set address = '부산시 해운대구', age = 18 WHERE id = 1; -- 연결해서 바꾸고 싶은 부분은 (,) 쉼표 이용
-- 삭제는 키값을 입력해줘야
DELETE FROM user WHERE id = 8; -- id 8번 데이터 사라짐
-- 그럼 id는 7, 9, 10... 8번이 사라진채로 데이터가 쌓임
SELECT DISTINCT department FROM employees; -- 중복값을 제외하고 보여줌
SELECT department, AVG(salary) AS avg_salary FROM employees GROUP BY department;
-- department와 묶어서 avg_salary라는 새로운 필드 추가
-- 새로 추가한 필드에는 샐러리의 평균값 조작
--*****group by를 쓸 때는 묶어줄 필드를 Select 뒤에 적어줘야 함*****
SELECT department, AVG(salary) AS avg_salary FROM employees GROUP BY department HAVING AVG(salary) > 5000;
-- 샐러리 평균이 5000 초과하는 값을 부서와 묶어서 보여줌
SELECT *FROM user WHERE birthday Like '%-06-%';
-- 출생연도 데이터 기입 방식 : 연도-월-일;
-- 6월생인 회원이 목록을 보여줌
SELECT id, name FROM user WHERE birthday LIKE '199%';
-- 1990년도에 태어난 회원들 중 id와 name의 칼럼만 보여줌
SELECT *FROM user WHERE gender = 'M' and birthday like '197%';
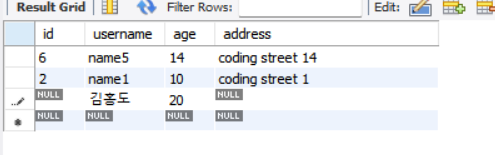
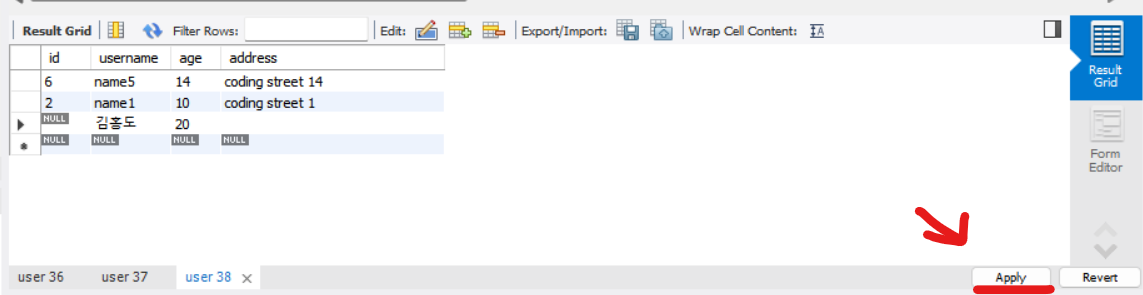
-- gender가 M이면서 1970년도에 태어난 회원만 보여줌WORK BENCH RESULT GRID에서 직접 조작하기
INSERT 대신 값을 테이블에 직접 입력해 추가해줄 수도 있습니다.
- 마우스를 더블 클릭해서 칸에 아래 그림처럼 추가할 값을 입력해줍니다.
- Apply를 해주면 입력한 값이 추가가 되어 쿼리할 수 있게 됩니다.
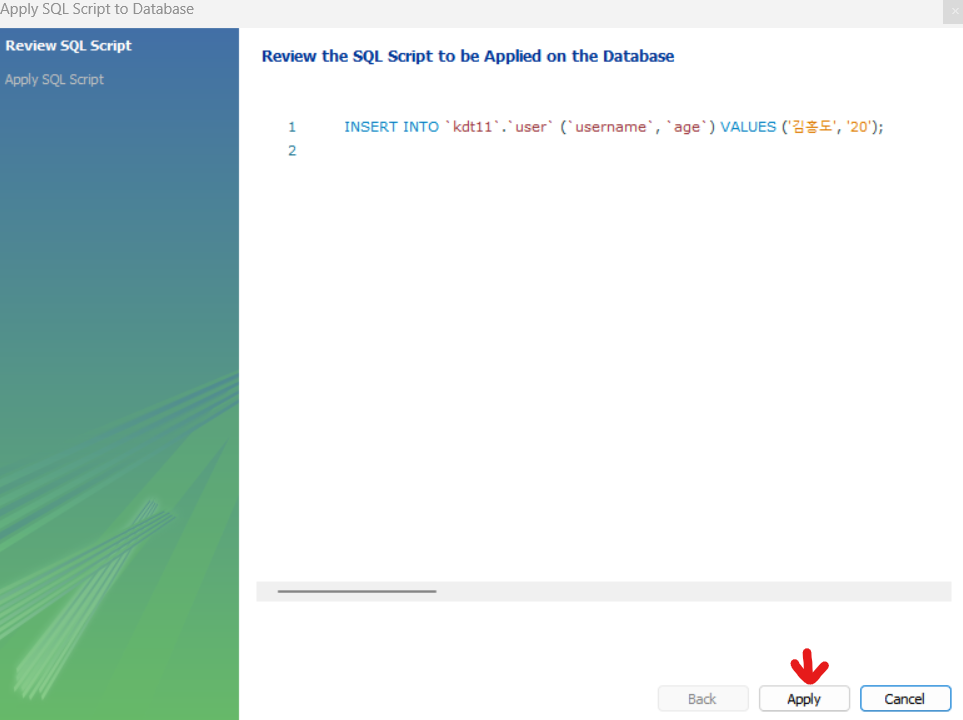
3. 데이터 제어어(DCL, Data Control Language)
: 데이터베이스에 접근하여 특정 작업을 할 수 있는 권한을 부여하거나 박탈시키기 위한 언어입니다.
- GRANT
: 권한을 부여합니다.
GRANT permission_type ON db_name.table_name TO username@host IDENTIFIED BY 'pw' [WITH GRANT OPTION];
- REVOKE
: 권한을 박탈합니다.
REVOKE permission_type ON db_name.table_name FROM 'username'@'host';
