AI > 머신러닝 > 딥러닝
AI가 상위개념, 머신러닝과 딥러닝이 하위개념이라고 볼 수 있다.
머신러닝에는 크게 지도학습, 비지도학습, 그리고 강화학습이 있는데
이번에는 강화학습이 뭔지 알아보려고 한다.
강화학습이란?
강화학습은 machine learning의 한 방식으로,
Agent라는 학습의 주체가 환경과 상호작용하면서 목표를 달성하기 위해 학습하는 것을 의미한다. 쉽게 말하면, 기계는 주어진 조건에서 문제를 해결하기 위한 여러 경우의 수를 실행한다. 이후 행동에 대한 보상(Reward)을 받으면서 목표 달성을 위한 최적의 행동이 무엇인지 찾아나가는 것이다. @fastcampus
에이전트와 환경
에이전트(agent)는 행동을 결정하고, 환경(environment)은 상태 전환과 보상액 결정을 담당한다.
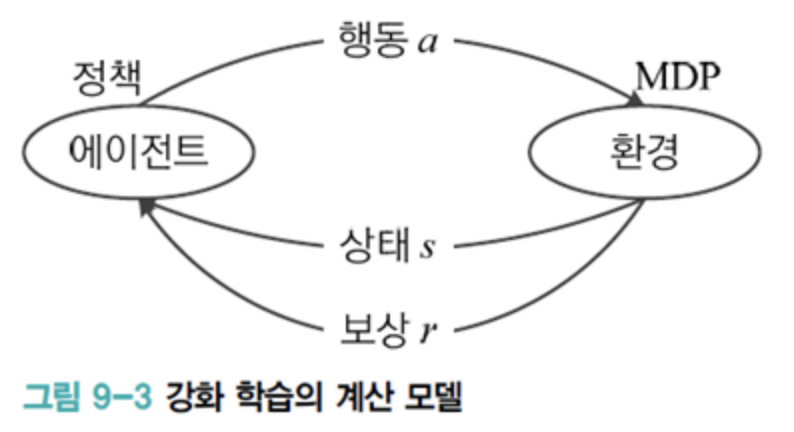
마르코프 결정 프로세스(Markov Decision Process)는 문제 정의시 주어지는 정보이다. 환경은 MDP 에 따라 다음 상태와 보상을 결정한다.
강화 학습은 주어진 MDP에서 최적의 행동을 결정하는 정책을 찾아야 합니다.
강화학습의 목표는 '누적' 보상액을 최대화하는 것입니다. 즉 순간 이득을 최대화하는 행동이 아니라 긴 시간 동안 누적 보상액이 최대가 되는 행동을 선택해야 합니다. 에이전트가 행동을 선택하는 데 사용하는 규칙을 정책(policy)이라고 하며, 강화 학습 알고리즘은 최적의 정책을 찾아야 합니다.
상태, 행동, 보상은 연속값일 수도 있지만, 대부분 응용에서는 이산값을 가집니다.
약속 표기
상태집합: S=s1,s2,⋯,sn
행동집합: A=a1,a2,⋯,an
보상집합: R=r1,r2,⋯,rn
@by Wordbe
강화학습의 특징
1. 특정 행동에 대한 좋고 나쁨을 평가하는 보상이 주어진다.
특정 행동에 대한 평가 개념의 보상 - 강화학습정답은 정해져 있지 않은 상황에서, 보상을 통해 행동에 대해 평가하는 경우입니다.
2. 현재의 의사결정이 미래에 영향을 미친다.
현재의 의사결정이 미래에 영향을 미친다 - 강화학습지금 하는 행동이 이후의 결과값에 영향을 미치는 경우입니다.
3. 문제의 구조를 사전에 알 수 없다.
문제의 구조를 사전에 알 수 없다 - 강화학습강화학습 과정에서 에이전트는 서울에서 대전까지의 이동거리가 어느 정도인지, 이동할 때 생기는 결과값이나 변수는 어떻게 되는지 사전에 정보를 제공 받을 수 없습니다. 따라서 주어진 환경과의 수많은 상호작용을 거쳐 보상 및 결과 정보를 취합하여 학습하게 됩니다. 이러한 과정을 반복하여 최종적으로 문제를 해결하는 것이죠.
강화학습 기본 개념
보상(Reward) : 특정 행동에 대해 하나의 숫자로 표현되는 평가 지표
상태(State) : 현재 상황을 기술하는 정보 (ex. 에이전트의 위치)
정책함수(Policy Function) : 특정 상태(State)에서 에이전트가 행동하는 방식 결정
가치함수(Value Function) : 각각의 상태와 행동이 얼마나 좋은지 추산 및 평가
모델(Model) : 에이전트가 학습 과정에서 추측하는 환경
@fastcampus
