Optimizing Federated Learning on Non-IID Data with Reinforcement Learning
Intro
challenges
1) limited connectivity
2) unstable availability
3) non IID distributions
→ model training에는 subset 이 선택되어 실행됨
communication rounds를 줄이기 위해 고안된 FedAvg 알고리즘의 문제
1) device 가 가진 각 data는 global 과 다른 distribution을 갖고 있을 것이다
2) non-IID data로 훈련된 model들은 서로 많이 다를 것이며
3) 이러한 모델들을 평균내는 것은 convergence와 model accuracy를 감소시킬 것이다.
FAVOR 알고리즘 제안
1) intelligent device selection을 통해 FL의 성능을 높인다
→ 각 communication round에서 bias를 counterbalance 할 수 있는 device들을 뽑는 방법을 학습한다.
2) 각 local 모델의 weight 상태와 global model의 weight 상태를 비교해 global model의 improvement 에 도움이 될 만한 local 모델을 선정하도록 학습한다.
3) DQN 학습법을 사용하였고 reward model은 communication round를 최소화시키고, global model accuracy를 높이는 방향으로 설계했다.
4) model weight를 state로 설정했는데 이를 low dimension으로 compress하는 법을 소개한다.
Background
이전 알고리즘 소개(FedAVG)
C 개의 class 가 존재하는 classification 문제에서 우리는 아래와 같은 cross entropy를 많이 사용한다.
(x: sample, w: model weight)
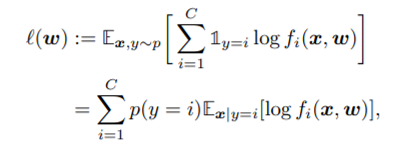
이러한 식의 배경은 아래와 같이
p가 ground truth(true label) 이고 q가 우리가 훈련해 나가고자 하는 NN의 output 이라 하면 위의 식을 최소화 하는 것은 두번째 항을 최소화 하는 것이며 이는 cross Entropy loss 라고 불리는 함수이다.
K 개의 device를 골라 훈련한다고 가정했을 때 k번 째 device에 대해서는 아래와 같은 weight training이 일어나게 된다.
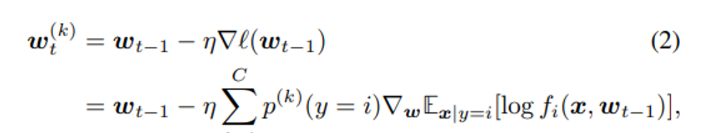
이러한 식의 각 local device에서 몇 번의 train iteration 진행된 이후인지 제한이 없다 (너무 많은 iteration은 over-fitting을 유발할 수 있기 때문에 바람직하지 않다)
global 과의 differenc를 아래와 같이 정의한다면
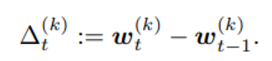
아래와 같은 weighted weight update를 진행하게 된다.
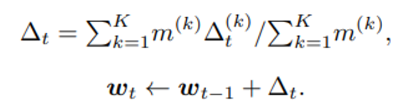
이 때 m은 각 device의 데이터 수를 의미하며 수식적인 해석은 하나의 difference 는 m_k 개의 data sample 의 결과로부터 얻은 gradient 이므로 각 device 마다 가진 data의 수로 가중 해줘야 한다는 의미이다.
FedAVG 의 한계
사실 non-IID condition에서는 잘 동작하지 않는다
→ heterogeneous 한 local data에 대한 model update가 누적되는 것은 learning performance를 감소시키며 더 많은 communication rounds를 요구한다. (FL에서의 최악)
non-IID 에서의 convergence 요구시간을 실험하기 위한 실험환경
IID : 각각의 device에 한 데이터셋의 자료를 randomly distribute
non-IID : 각 device는 하나의 dominant label 자료가 80%, 다른 자료들이 20% 존재하게 설정
convergence에 걸리는 step 이 세배 정도 차이남
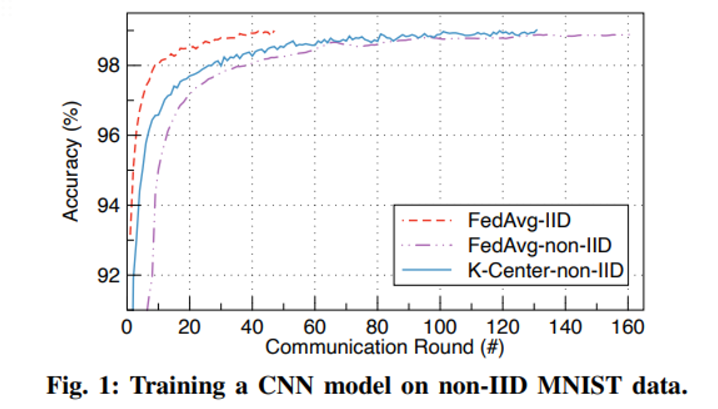
이를 줄이기 위해 (최대한 비슷한 device를 고르면 non-iid 문제를 피할 수 있지 않을까?)
local device의 data distribution은 local model weight와 관련이 있을 것이라는 점!을 이용
논문에서는 서로 다른 두 local model 이 가진 weight의 difference를
와 같이 표현
이는
Y. Zhao, M. Li, L. Lai, N. Suda, D. Civin, and V. Chandra, “Federated
Learning with Non-IID Data,” arXiv preprint arXiv:1806.00582, 2018
아래 논문으로 부터 얻은 방식을 통하면 아래와 같이 bound 되어 있다.
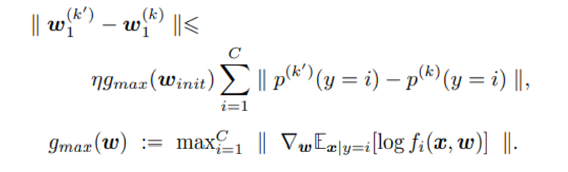
이러한 방법이 유의미하다는 것을 보이기 위해 K clustering 알고리즘으로 위에서 정의한 metric 을 기준으로 몇개의 cluster로 나눈 후 하나의 cluster만 global model의 update에 기여할 수 있도록 설정했다.
위의 Fig.1 그림에서 파란색 그래프로 표현되어있다.
RL 을 client 선정에 사용
objective : DRL agent를 훈련시켜 가장 빠르게 FL이 converge 하는 것
조건 : local model의 weight만 참조
<state 관점>
state 의 정의
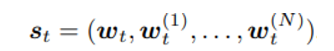
윗첨자가 없는 것은 global model의 weight를 나타내며 있는 것들은 i번째 device의 model을 의미한다.
<action 관점>
N개의 device에서 K개를 선정하는 action은 NCK 가지 이므로 너무 큰 action space를 형성한다.
→ 보통의 Deep RL이 하는 것처럼 NN이 Q(s,a)를 예측하게 train 시키고 여기서 test 나 evaluation time 때 top K개 action을 선택하는 방식으로 진행한다.
<reward 관점>
보상 설정은 아래와 같은 수식으로 이뤄진다.
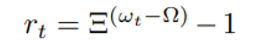
밑은 상수로 exp 한 증가를 나타내기 위함, w_t는 t round 이후 gloal model의 정확도, omega는 목표 정확도를 의미하며 결과적으로 r_t 는 [-1,0]에 위치하게 된다.
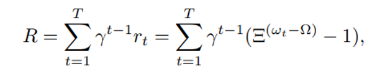
결과적으로는 discount factor를 포함해 더한 다음과 같은 reward를 최대화 하는 것을 목표로 한다.
communication round에 대한 패널티 항을 추가하면 어떨까? (-1 이 이부분을 담당!)
→ round를 계속 진행하며 reward를 받으면 패널티가 증가하기 때문에
reward function을 exp 하게 만든 이유는 round t가 증가할수록 test accuracy 차이가 감소할 것이기 때문에 marginal accuracy를 amplify 시켜주는 것이다.
<workflow 정리>
1) N eligible device check-in
2) 완전 초기 randon weight w_init을 서버로 부터 받으면 각 local SGD 를 돌린 이후 서버에 return
3) local model weight 들은 서버에 저장된 상태이며 매번 업데이트
4) DQN 이 이를 바탕으로 k개의 높은 Q를 계산, k 개의 device 에 대해서만 SGD 계산
5) 앞서 계산한 값을 서버에 업데이트, 3~5의 과정을 반복
<state 차원 낮추기>
하지만 NN의 모든 weight를 사용하는 것은 state dimension을 과하게 증가시키기 때문에 이를 낮추기 위해 우리는 PCA(Principle Component Analysis) 를 사용한다.
PCA 방식은 처음 weight 인 w1에 대해 적용하여 vector를 얻은 후 다음 round에서 w들의 업데이트 과정은 linear transformation 을 통해 다시 PCA를 적용하지 않고 진행할 수 있어 overhead가 적다.
