앞선 QMIX를 읽고 agent 모듈에 LSTM 혹은 GRU가 쓰인 것을 보고 agent에 attention 방식을 적용해보는 것을 졸업 논문 주제로 생각해 보았지만 이미 관련 논문이 있어 읽고 정리해 보았다.
(이 논문에서는 critic이 actor들을 참고할 때 attention 방식을 사용)
Intro
-
IQL 에 대한 한계는 지금까지 읽어왔던 모든 Mutli agent RL 논문들과 마찬가지로 여기서도 지적된다.
Multi agent 상태에서의 independent learning은 한 agent의 학습 동안 다른 agent들의 policy 변화로 인해 RL에서 만족해야 하는 stationary + Markovian 조건을 만족시키지 않는다는 것이다. -
최근에 읽은 COMA 방식이 이 논문의 서론에 등장하였다. 복습해보자면 하나의 centralised critic과 각각의 agent가 갖고 있는 actor가 존재하고 각 actor는 학습(평가) 당시 자신에게 대응되는 agent의 observation만 알면 되기 때문에(다른 agent들의 joint action은 고정) 이전의 non-stationary 한 조건을 피해갈 수 있었다.
하지만, 이 방법은 agent 수에 대해 scale 하지 않고 cooperative, competitive, mixed 환경에 적합하지 않다(?) => 이 부분 왜 그런지 생각해보기 -
이 논문의 contribute는 centralised critic의 learning 방식에 attention mechanism을 이용해 보자는 것이다. 이전 논문에서 centralised critic은 모든 agent의 actor에 대해 parity하게 observation 결과를 자신의 Q update에 반영했지만 attention 방식을 사용하면 given state에 대해 어떤 actor의 정보를 더 많이 참조할지 학습할 수 있다는 점에서 기인했다.
-
이 논문에서 제시한 방식은 competitive, mixed 환경에서 모두 작용할 수 있다.
기존의 논문은 cooperative 환경에서의 학습만 고려
(왜 그런지 생각해보기)
Related Work
- 이 논문의 방식 기존의 Multi-agent RL보다 flexible 한 이유
- any reward setup, 각 agent에 대한 다른 action space 설정 환경에서도 훈련 가능
- relevant agent's action만 marginalise 하는 baseline function (Expectation 에 영향 안주고 variance만 줄이는 advantage 함수의 두번째 term을 의미)
- 연관성이 높은 agent결과를 더 높게 쳐주는 centralised critic
=> 이러한 성질들 때문에 agent 수에 대해 scalable 하고 cooperative 한 환경을 넘어선 환경에서 training이 가능하다?
Approach
-
기존 논문들과 notation은 비슷하며 policy gradient에 대한 background는 생략하도록 하겠다.
-
새로운 내용인 soft actor-critic 소개
non-optimal deterministic policy에 수렴하는 것을 막기 위해 entropy 항을 추가한 새로운 gradient ascend 값을 소개
아래의 두 식 중 위는 원래의 방식, 아래는 soft actor-critic을 도입한 방식이다.
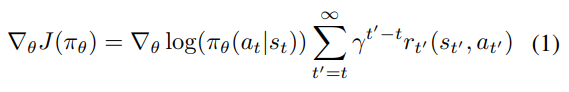
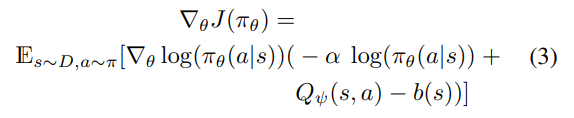
가 이 항에 해당한다.
baseline function인 b(s)에 대해서 전에 우리는 를 사용해 variance를 줄이는 방법을 배웠지만 이 논문에서는 뒤에 소개될 다른 값을 사용하고자 한다
위의 식에 맞춰 TD learning의 target도 새로 설정된다.
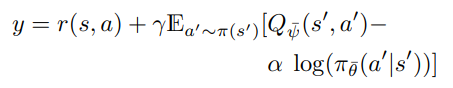
MAAC - Multi Actor Attention Critic
-
Attention 방식의 overall view
각 agent는 다른 agent들의 observation 결과를 query하고 자신의 value function을 예측하는데 그 값을 포함하여 계산한다.
이러한 방식이 차용된 이유는 기존에 attention이 포함하던 temporal 혹은 spatial locality 를 제거하기 위함이다 (이 부분 잘 이해안됨) -
agent i에 대한 Q value를 계산하기 위해 critic은 모든 agent의 action과 observation을 input으로 받는다. 식으로는 아래와 같은 output을 얻는다.

f는 2층 MLP, g는 1층 MLP embedding 함수이다.
x는 다른 agent들의 contribution을 의미하는 변수이고 아래와 같이 계산된다.
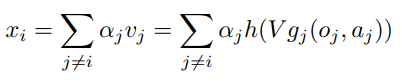
(여기서 j notation은 i를 제외한 다른 agent들의 집합으로 이해하면 된다.)
v는 j의 embedding 함수들의 처리 결과값을 의미한다.
embedding 함수 g는 shared matrix V를 통과한 이후 element-wise Leaky RELU h 를 통과한다.
는 attention weight로 query-key system을 통해 agent i의 embedding과 agent j의 embedding 사이 상관관계를 나타낸다
각각의 embedding 를 의미하며 와 를 통해 각 embedding을 key와 query로 변경한다.
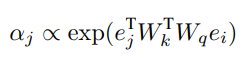
위에는 비례관계로 표현되었지만 실제로는 softmax로 이뤄져 있다. -
위에서 설명된 , , V는 모든 agent간 공유되고 있으며 이는 서로 다른 agent간 다른 reward를 받지만 common feature를 공유하는 경우 이를 학습할 수 있다는 장점이 있다.
-
'All critics are updated together to minimize a joint regression loss function'이라는 구절이 있는데 centralised critc 한 개를 학습한다고 알고 있었기 때문에 이 부분이 의미하는 바를 파악하지 못하겠다.
하지만 loss 와 target은 아래와 같이 설정된다.
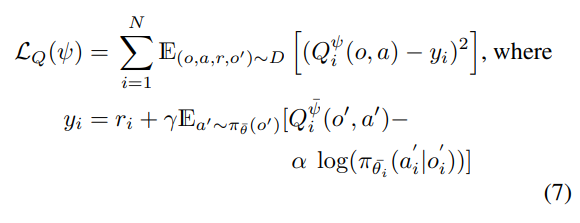
여기서 위에 bar 가 들어간 parameter들은 target network의 parameter를 의미한다. (이전 논문에서 그랬던 것처럼 아마 batch 단위로 freeze 시킨 후 한번에 update 하는 network 형태를 예측해 볼 수 있다.)
변수 는 엔트로피 항 앞에 붙어있는데 이는 entropy 와 reward 사이 균형을 잡아주는 역할을 한다고 이해할 수 있다. -
gradient ascent는 아래와 같은 식을 통해 이뤄짐을 알 수 있다.
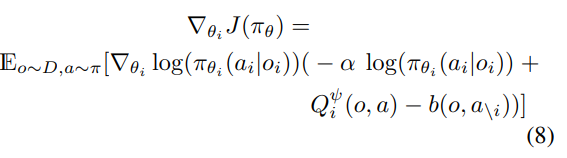
이 식을 통해 이전 논문들이 Memory queue에서 튜플을 sampling 해 업데이트(DQN?) 한 것과는 다르게 모든 agent의 current policy를 기반으로 parameter 업데이트를 하고 있음을 알 수 있다. -
앞서 baseline function은 대신 다른 함수를 사용한다고 하였는데 아래와 같다.
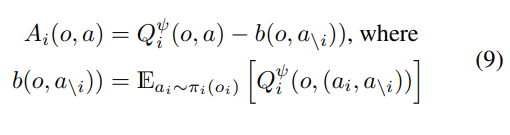
논문에는 'marginalizes out the actions of the given agent'라고설명되어 있는데 이는 현재 agent i가 가질 수 있는 모든 action에 대해 (다른 agent들의 action은 고정한 상태로; ) expectation을 취함으로서 우리가 선택한 action (agent i 입장에서)이 expected return에 영향을 주는 것인지 다른 action들이 영향을 주는 것인지 확인할 수 있다.
(advantage function의 baseline에서 이미 다른 agent들이 주는 영향을 뺄셈으로 고려했기 때문에) -
COMA에서 제시한 advantage function과는 다르게 이 방식은 서로 다른 agent에 대해 같은 action space를 요구하지 않으며 이는 encoding ()에 여러 Matrix를 곱해 새로운 vector space를 만드는 attention 방식으로 implement 되고 있다.
-
이 논문에서 사용한 baseline function을 linear time에 계산할 수 있게 만들기 위해서는 Q 함수가 원래 아래와 같은데
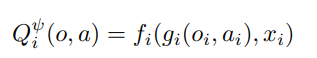
encoder 대신에 로 바꿔 가 input으로 들어가지 않도록 설정한다.
또한 원래 output은 action a_i에 대한 값 하나만 나오게 설정했었지만 가능한 모든 action에 대해 벡터형태로 나오도록 를 수정한다.
이 방법은 discrete policy에 대해 적용하며 continuous policy 인 경우에 대해서는 샘플링을 통해서 배우도록 한다.
