main.py
user_seq, max_item, valid_rating_matrix, test_rating_matrix = \
get_user_seqs(args.data_file)
offline_similarity_model = OfflineItemSimilarity(data_file=args.data_file,
similarity_path=args.similarity_model_path,
model_name=args.similarity_model_name,
dataset_name=args.data_name)
args.offline_similarity_model = offline_similarity_model- user_seq 는 item 소비 기록이 있는 List[List[int]]
- max_item 은 item_set의 길이
- valid_rating_matrix, test .. 는 (num_users, num_items) 크기의 matrix로 [user][item] 이 interact 했다면 원소 크기가 1
models.py
class OfflineItemSimilarity:
def __init__(self, data_file=None, similarity_path=None, model_name='ItemCF', \
dataset_name='Sports_and_Outdoors'):
self.dataset_name = dataset_name
self.similarity_path = similarity_path
# train_data_list used for item2vec, train_data_dict used for itemCF and itemCF-IUF
**self.train_data_list, self.train_item_list, self.train_data_dict = self._load_train_data(data_file)**
self.model_name = model_name
**self.similarity_model = self.load_similarity_model(self.similarity_path)**
self.max_score, self.min_score = self.get_maximum_minimum_sim_scores()
def _load_train_data(self, data_file=None):
"""
read the data from the data file which is a data set
"""
train_data = []
train_data_list = []
train_data_set_list = []
for line in open(data_file).readlines():
userid, items = line.strip().split(' ', 1)
# only use training data
items = items.split(' ')[:-3]
train_data_list.append(items)
train_data_set_list += items
for itemid in items:
train_data.append((userid,itemid,int(1)))
return train_data_list, set(train_data_set_list), self._convert_data_to_dict(train_data)
def _convert_data_to_dict(self, data):
"""
split the data set
testdata is a test data set
traindata is a train set
"""
train_data_dict = {}
for user,item,record in data:
train_data_dict.setdefault(user,{})
train_data_dict[user][item] = record
return train_data_dict- tarin_data_list 에는 List[List[int]] 꼴의 결과 반환
- train_data_dict 은 Dict[Dict[record]] 꼴이며 바깥 Dict은 user를 key로 가지며 value는 다시 Dict 이며 이 안쪽 Dict은 key가 item 이며 value 는 record == 1 이다.
- beauty data에 대해 model_name 은 ItemCF_IUF 이다 .
- load_similarity_model 의 첫호출에는 generate_item_similarity 가 호출된다
def _generate_item_similarity(self,train=None, save_path='./'):
"""
calculate co-rated users between items
"""
print("getting item similarity...")
train = train or self.train_data_dict
C = dict()
N = dict()
if self.model_name in ['ItemCF', 'ItemCF_IUF']:
print("Step 1: Compute Statistics")
data_iter = tqdm(enumerate(train.items()), total=len(train.items()))
for idx, (u, items) in data_iter:
if self.model_name == 'ItemCF':
for i in items.keys():
N.setdefault(i,0)
N[i] += 1
for j in items.keys():
if i == j:
continue
C.setdefault(i,{})
C[i].setdefault(j,0)
C[i][j] += 1
**elif self.model_name == 'ItemCF_IUF':
for i in items.keys():
N.setdefault(i,0)
N[i] += 1
for j in items.keys():
if i == j:
continue
C.setdefault(i,{})
C[i].setdefault(j,0)
C[i][j] += 1 / math.log(1 + len(items) * 1.0)**
self.itemSimBest = dict()
print("Step 2: Compute co-rate matrix")
c_iter = tqdm(enumerate(C.items()), total=len(C.items()))
for idx, (cur_item, related_items) in c_iter:
self.itemSimBest.setdefault(cur_item,{})
for related_item, score in related_items.items():
self.itemSimBest[cur_item].setdefault(related_item,0);
self.itemSimBest[cur_item][related_item] = score / math.sqrt(N[cur_item] * N[related_item])
self._save_dict(self.itemSimBest, save_path=save_path)- N, C, itemSimBest는 모두 Dict[Dict[int]] 로 2-d array 를 나타내며 self.itemSimBest는 아래 최종 matrix를 나타낸다.
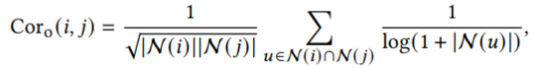
- 왼쪽 등장빈도 부분이 N, 오른쪽 길이 부분이 C, 최종 Cor 가 itemSimBest에 대응
OfflineItemSimilarity init 끝
main.py
# training data for node classification
train_dataset = RecWithContrastiveLearningDataset(args,
user_seq[:int(len(user_seq)*args.training_data_ratio)], \
data_type='train')
train_sampler = RandomSampler(train_dataset)
train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.batch_size)- 위에서 생성된 offlinesimilarity model 이 전달됨
init 시 아래와 같은 log
Similarity Model Type: offline
short sequence augment type: SIMRC
all aug set for short sequences
Augmentation methods for Long sequences: 5
Augmentation methods for short sequences: 5
Creating Contrastive Learning Dataset using 'random' data augmentationmain.py
model = SASRecModel(args=args)
trainer = CoSeRecTrainer(model, train_dataloader, eval_dataloader,
test_dataloader, args)- sasrec model 안에 Encoder - Layer - SelfAttention, Intermediate class 가 순차적으로 포함
trainers.py
class Trainer:
def __init__(self, model, train_dataloader,
eval_dataloader,
test_dataloader,
args):
self.args = args
self.cuda_condition = torch.cuda.is_available() and not self.args.no_cuda
self.device = torch.device("cuda" if self.cuda_condition else "cpu")
self.model = model
self.online_similarity_model = args.online_similarity_model
self.total_augmentaion_pairs = nCr(self.args.n_views, 2)
#projection head for contrastive learn task
self.projection = nn.Sequential(nn.Linear(self.args.max_seq_length*self.args.hidden_size, \
512, bias=False), nn.BatchNorm1d(512), nn.ReLU(inplace=True),
nn.Linear(512, self.args.hidden_size, bias=True))
if self.cuda_condition:
self.model.cuda()
self.projection.cuda()
# Setting the train and test data loader
self.train_dataloader = train_dataloader
self.eval_dataloader = eval_dataloader
self.test_dataloader = test_dataloader
# self.data_name = self.args.data_name
betas = (self.args.adam_beta1, self.args.adam_beta2)
self.optim = Adam(self.model.parameters(), lr=self.args.lr, betas=betas, weight_decay=self.args.weight_decay)
print("Total Parameters:", sum([p.nelement() for p in self.model.parameters()]))
self.cf_criterion = NCELoss(self.args.temperature, self.device)
# self.cf_criterion = NTXent()
print("self.cf_criterion:", self.cf_criterion.__class__.__name__)- self.total_augmentation_pairs = 1 (2C2)
- self.projection 의 첫 Linear input 은 50(max_seq_len) * 64(hidden_size)
- encoder를 통과한 결과를 projection 시켜 sequence를 hidden_size 벡터로 만든다
- betas = (0.9, 0.999)
- lr =0.001
trainer.train 시작
trainers.py
def train(self, epoch):
# start to use online item similarity
if epoch > self.args.augmentation_warm_up_epoches:
print("refresh dataset with updated item embedding")
self.train_dataloader = self.__refresh_training_dataset(self.model.item_embeddings)
self.iteration(epoch, self.train_dataloader)
how to prepare dataset
datasets.py
def __getitem__(self, index):
user_id = index
items = self.user_seq[index]
assert self.data_type in {"train", "valid", "test"}
# [0, 1, 2, 3, 4, 5, 6]
# train [0, 1, 2, 3]
# target [1, 2, 3, 4]
**if self.data_type == "train":
input_ids = items[:-3]
target_pos = items[1:-2]
answer = [0] # no use**
elif self.data_type == 'valid':
input_ids = items[:-2]
target_pos = items[1:-1]
answer = [items[-2]]
else:
items_with_noise = self._add_noise_interactions(items)
input_ids = items_with_noise[:-1]
target_pos = items_with_noise[1:]
answer = [items_with_noise[-1]]
if self.data_type == "train":
**cur_rec_tensors = self._data_sample_rec_task(user_id, items, input_ids, \
target_pos, answer)**
cf_tensors_list = []
# if n_views == 2, then it's downgraded to pair-wise contrastive learning
total_augmentaion_pairs = nCr(self.n_views, 2)
for i in range(total_augmentaion_pairs):
**cf_tensors_list.append(self._one_pair_data_augmentation(input_ids))**
return (cur_rec_tensors, cf_tensors_list)- rec task 용과 contrastive learning 용으로 나눠서 반환
- total_augmentation_pairs == 1
def _data_sample_rec_task(self, user_id, items, input_ids, target_pos, answer):
# make a deep copy to avoid original sequence be modified
copied_input_ids = copy.deepcopy(input_ids)
target_neg = []
seq_set = set(items)
for _ in copied_input_ids:
target_neg.append(neg_sample(seq_set, self.args.item_size))
pad_len = self.max_len - len(copied_input_ids)
copied_input_ids = [0] * pad_len + copied_input_ids
target_pos = [0] * pad_len + target_pos
target_neg = [0] * pad_len + target_neg
copied_input_ids = copied_input_ids[-self.max_len:]
target_pos = target_pos[-self.max_len:]
target_neg = target_neg[-self.max_len:]
assert len(copied_input_ids) == self.max_len
assert len(target_pos) == self.max_len
assert len(target_neg) == self.max_len
if self.test_neg_items is not None:
test_samples = self.test_neg_items[index]
cur_rec_tensors = (
torch.tensor(user_id, dtype=torch.long), # user_id for testing
torch.tensor(copied_input_ids, dtype=torch.long),
torch.tensor(target_pos, dtype=torch.long),
torch.tensor(target_neg, dtype=torch.long),
torch.tensor(answer, dtype=torch.long),
torch.tensor(test_samples, dtype=torch.long),
)
else:
cur_rec_tensors = (
torch.tensor(user_id, dtype=torch.long), # user_id for testing
torch.tensor(copied_input_ids, dtype=torch.long),
torch.tensor(target_pos, dtype=torch.long),
torch.tensor(target_neg, dtype=torch.long),
torch.tensor(answer, dtype=torch.long),
)
return cur_rec_tensors- items는 유저의 실제 모든 interaction 기록이지만 neg_sampling 시 중복을 피하기 위해 사용된다
- input_ids 는 interaction list에서 [:-3] 까지 있는 기록
- target_pos는 오른쪽으로 한칸씩 이동한, label 을 의미한다
- answer는 training 시 사용되지 않는다
- input_ids와 동일한 길이의 target_neg 가 random sampling을 통해 생성된다
- len(input_ids) == len(target_pos) == len(target_neg)
- 이 모든 값들을 max_len 길이가 되도록 padding 해 길이가 똑같아지도록 만든다
def _one_pair_data_augmentation(self, input_ids):
'''
provides two positive samples given one sequence
'''
augmented_seqs = []
for i in range(2):
augmented_input_ids = self.base_transform(input_ids)
pad_len = self.max_len - len(augmented_input_ids)
augmented_input_ids = [0] * pad_len + augmented_input_ids
augmented_input_ids = augmented_input_ids[-self.max_len:]
assert len(augmented_input_ids) == self.max_len
cur_tensors = (
torch.tensor(augmented_input_ids, dtype=torch.long)
)
augmented_seqs.append(cur_tensors)
return augmented_seqs- 하나의 input_ids가 주어지면 이에 대한 positive sample 이 함수를 통해 2개 만들어진다
- base_transform 은 논문에서 말한대로 random, crop, insert .. 등등
- augmented_seqs는 길이 2의 List로 사이즈가 50인 tensor 포함
train.py
for i, (rec_batch, cl_batches) in rec_cf_data_iter:
'''
rec_batch shape: key_name x batch_size x feature_dim
cl_batches shape:
list of n_views x batch_size x feature_dim tensors
'''
# 0. batch_data will be sent into the device(GPU or CPU)
rec_batch = tuple(t.to(self.device) for t in rec_batch)
_, input_ids, target_pos, target_neg, _ = rec_batch
# ---------- recommendation task ---------------#
sequence_output = self.model.transformer_encoder(input_ids)
**rec_loss = self.cross_entropy(sequence_output, target_pos, target_neg)**- rec_batch에는 user_id, copied_input_ids, target_pos, target_neg, answer 이 tuple로 들어가 있어 이를 gpu로 옮김
- sequence_output dim: [batch_size, max_len, hidden_size]
def cross_entropy(self, seq_out, pos_ids, neg_ids):
# [batch seq_len hidden_size]
pos_emb = self.model.item_embeddings(pos_ids)
neg_emb = self.model.item_embeddings(neg_ids)
# [batch*seq_len hidden_size]
pos = pos_emb.view(-1, pos_emb.size(2))
neg = neg_emb.view(-1, neg_emb.size(2))
seq_emb = seq_out.view(-1, self.args.hidden_size) # [batch*seq_len hidden_size]
pos_logits = torch.sum(pos * seq_emb, -1) # [batch*seq_len]
neg_logits = torch.sum(neg * seq_emb, -1)
istarget = (pos_ids > 0).view(pos_ids.size(0) * self.model.args.max_seq_length).float() # [batch*seq_len]
loss = torch.sum(
- torch.log(torch.sigmoid(pos_logits) + 1e-24) * istarget -
torch.log(1 - torch.sigmoid(neg_logits) + 1e-24) * istarget
) / torch.sum(istarget)
return loss- pos_emb, neg_emb : [batch_size, max_len, hidden_size]
- dimension 변경 후 element-wise 곱 후 logit을 생성
- istarget은 padding 이 아닌 부분을 정하는 mask
# ---------- contrastive learning task -------------#
cl_losses = []
for cl_batch in cl_batches:
**cl_loss = self._one_pair_contrastive_learning(cl_batch)**
cl_losses.append(cl_loss)
def _one_pair_contrastive_learning(self, inputs):
'''
contrastive learning given one pair sequences (batch)
inputs: [batch1_augmented_data, batch2_augmentated_data]
'''
cl_batch = torch.cat(inputs, dim=0)
cl_batch = cl_batch.to(self.device)
cl_sequence_output = self.model.transformer_encoder(cl_batch)
# cf_sequence_output = cf_sequence_output[:, -1, :]
cl_sequence_flatten = cl_sequence_output.view(cl_batch.shape[0], -1)
# cf_output = self.projection(cf_sequence_flatten)
batch_size = cl_batch.shape[0]//2
cl_output_slice = torch.split(cl_sequence_flatten, batch_size)
cl_loss = self.cf_criterion(cl_output_slice[0],
cl_output_slice[1])
return cl_loss
self.cf_criterion = NCELoss(self.args.temperature, self.device)
# #modified based on impl: https://github.com/ae-foster/pytorch-simclr/blob/dc9ac57a35aec5c7d7d5fe6dc070a975f493c1a5/critic.py#L5
def forward(self, batch_sample_one, batch_sample_two):
sim11 = torch.matmul(batch_sample_one, batch_sample_one.T) / self.temperature
sim22 = torch.matmul(batch_sample_two, batch_sample_two.T) / self.temperature
sim12 = torch.matmul(batch_sample_one, batch_sample_two.T) / self.temperature
d = sim12.shape[-1]
sim11[..., range(d), range(d)] = float('-inf')
sim22[..., range(d), range(d)] = float('-inf')
raw_scores1 = torch.cat([sim12, sim11], dim=-1)
raw_scores2 = torch.cat([sim22, sim12.transpose(-1, -2)], dim=-1)
logits = torch.cat([raw_scores1, raw_scores2], dim=-2)
labels = torch.arange(2 * d, dtype=torch.long, device=logits.device)
nce_loss = self.criterion(logits, labels)
return nce_loss- cl_batches는 [bsize, max_len] 인 tensor 가 두개 있는 list 를 바깥 list가 한번 더 싸고 있음
- cat 전에 input 은 input[0].shape == input[1].shape 이 [bsize, max_len] 이런 구조
- contrastive loss 적용하기 전에 먼저 row 가 (data1 + data2), col 이 (data2+ data1) 이런 식으로 조성 후 label을 range(2*bsize) 로 줘서 한 sequence에서 파생된 data1, data2 의 같은 index 값에 label 1이 가고 나머지에는 0이 가는 식으로 학습함

0100101