Communication-Efficient Learning of Deep Networks from Decentralized Data
Communication-Efficient Learning of Deep Networks from Decentralized Data
Intro
private 한 데이터를 central 하게 저장하지않고 exploit 하기 위해 Federated Learning 을 개발
각 client 들은 global model 에 update 정보를 제공
contributions
1) Federated Learning framework 제안
2) 제안된 방식에 대한 실험적 결과제공
3) FederatedAveraging 알고리즘 제안 : 각 local의 SGD를 서버에서 averaging 하는 알고리즘
실험내용
1) unbalanced 하거나 non-IId 한 data에 대해서도 훈련가능
2) communication 빈도를 줄임 (기존에 비해)
Federated Optimization
typical 한 distributed optimization 과 몇가지 차이를 갖는다.
1) non iid: local device가 갖고 있는 데이터들은 굉장히 personal 하기 때문에 전체 client 들의 distribution을 대변하지 못할 것이다.
2) unbalanced: client 에 따라 사용빈도가 다를 것이고 이는 trainig data 양의 차이를 의미한다.
3) limited communication: 모바일 device에서 connection 비용은 큰 값으로 고려해야 한다.
실험환경
unbalanced, non-IId 환경 구현에 집중!
synchronous update scheme 가정 : 현실에서는 시차등의 asynchronous 고려
fixed set of K clients with fixed local dataset: 현실에서는 local device data의 빈번한 삭제와 추가 발생
실험방식
전체 K client 중에서 C fraction 을 선정해 global model state를 전송 후 각각의 client 들의 update 정보를 다시 받는 방식으로 훈련
Distributed optimization 과 수식적인 차이
정리)
(w) : client k에 대해 하나의 data가 갖는 estimation loss의 크기
f(w) : 전체 client 집합에 대해 하나의 data가 갖는 estimation loss의 크기
일단 non-convex 한 NN objective 에 집중한다.
client k에 대해, 전체 data P 중 k에 distributed 된 data의 index 집합을 라 하고 라 하면
: client k 의 데이터 하나에 대한 loss 평균 // 으로 이해할 경우 수식은
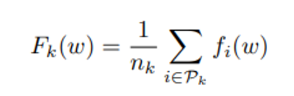
이에 따라 client k의 estimation error 총합은 로 이해할 수 있으며 전체 distribution에 대해 하나의 data가 갖는 error 평균은 아래 식과 같다.
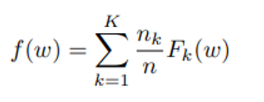
일반적인 distributed optimization 의 가정에서는 distribution 들에 대해 취한 $F_k $의 평균은 전체 입장에서 본 하나의 data가 갖는 error 평균과 같을 것이지만,
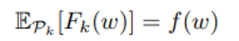
우리는 non-IID 를 가정했기 때문에 마지막 식은 성립하지 않을 것이다.
Datacenter와의 환경차이
client 에서 cloud 로의 upload bandwidth가 적을 뿐더러 update round가 작을 것으로 예상되기 때문에 communication 에 제한이 있음
하지만 각 device 가 가진 dataset이 작고 이에 비해 device GPU 성능이 괜찮으므로 아래와 같은 두가지 방안을 생각
1) increased parallelism
→ 각 communication round 사이에 client가 각자 계산을 많이 수행할 수 있도록 한다.
2) increased computation
→ 각 communication round 사이에 간단한 gradient 계산으로 끝나기 보다는 각 client 들이 복잡한 계산을 수행할 수 있도록 한다.
1보다는 2의 방식에 더 힘을 주고 있다.
FederatedAveraging Algorithm
Baseline : random 하게 선택된 client에 대해 batch gradient calculation 을 진행하는 방식
→ round 가 많이 필요함
federated setting에서는 client들을 parallel 하게 추가하는 것에 큰 비용이 없음과 동시에 datacenter 환경에서 SOTA는 large-batch synchronous SGD 이므로 (asynchrounous 보다 나음)
2016년 논문기준으로
Jianmin Chen, Rajat Monga, Samy Bengio, and Rafal Jozefowicz. Revisiting distributed synchronous sgd.In ICLR Workshop Track, 2016
datacenter 환경에 대한 후속 논문들을 찾아봐야 할 것 같다. (특히 asynchrounous 부분도)
C - fraction의 client들을 매 라운드에 선택 후 이들이 가진 모든 데이터에 대해 gradient loss를 계산한다.
(여기서 C는 1보다 작은 값으로 C=1인 경우 모든 client 즉, 전체 dataset에 대해 full batch gradient descent를 하는 것이다. )
이 알고리즘을 FedSGD라고 부른다.
앞서 intro와 같이
: local data 를 사용해 계산한 client k의 average gradient
learning rate를 곱한 후, gradient 들의 weighted sum을 곱해 전체 global model update 식은
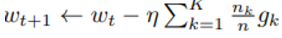
이 식은 practical 하게 각각의 client에서
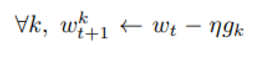
을 계산 후
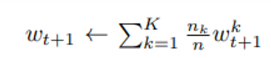
weighted sum을 구하는 식으로 풀 수 있다.
앞서 intro 의 2번 increased computation 방식은 communication round 이전에 client 가 여러번의 gradient computation 을 진행하는 방식을 의미한다.
<notation 설명>
C : 각 round에 참여해 gradient를 계산하게 되는 client fraction
E : 각 client가 local dataset을 이용해 gradient iteration을 추가적으로 계산하는 횟수
B : 각 client의 local minibatch size
전체 알고리즘은 아래와 같다.

non-convex 한 task에 대해서 다른 random seed로 initialize 한 네트워크 두개를 합치는 것은 성능 저하를 나타낸다.
→ 각각의 train dataset에 대한 overfitting 현상 발생 시작
하지만 같은 random seed로 초기화 후 각자 datset으로 훈련 후 두 네트워크를 합치면 loss가 최소값을 나타낸다.
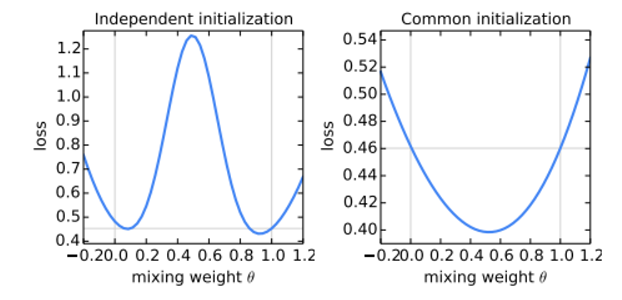
왼쪽은 random seed를 다르게 하여 첫 네트워크를 초기화 한 것이고 (theta = 0, 1 일 때 최소인 것을 보아 합쳤을 때 혼자 네트워크일 때 만큼의 성능을 낼 수 없음) 오른쪽은 random seed 를 같게 하여 합친 경우를 의미한다.
FedAVG 알고리즘에서 각 round 시작은 client로 동일한 wt가 들어온다는 점에서 위의 결과 중 오른쪽 그래프와 같은 결과를 나타낼 것을 의미한다.
