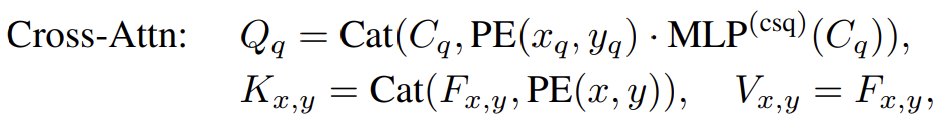DAB-DETR 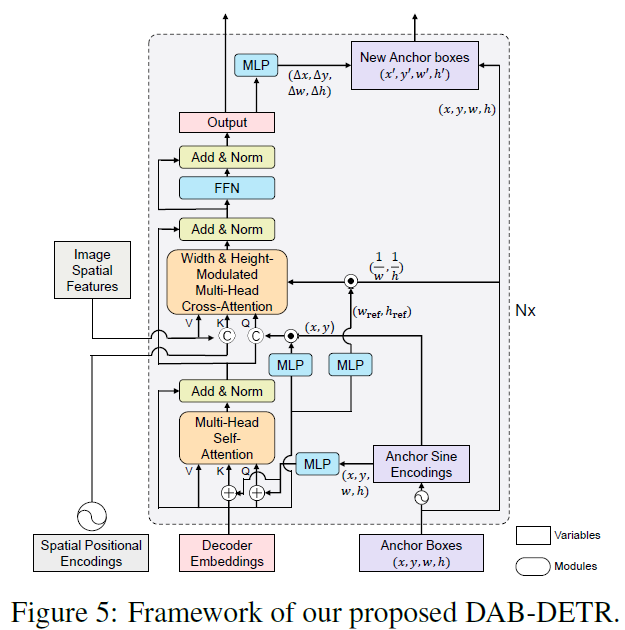
Dynamic Anchor Boxes are better queries for DETR
Published on ICLR 2022 , Tsinghua University.
Presenter: Dongkeon Park
Introduction
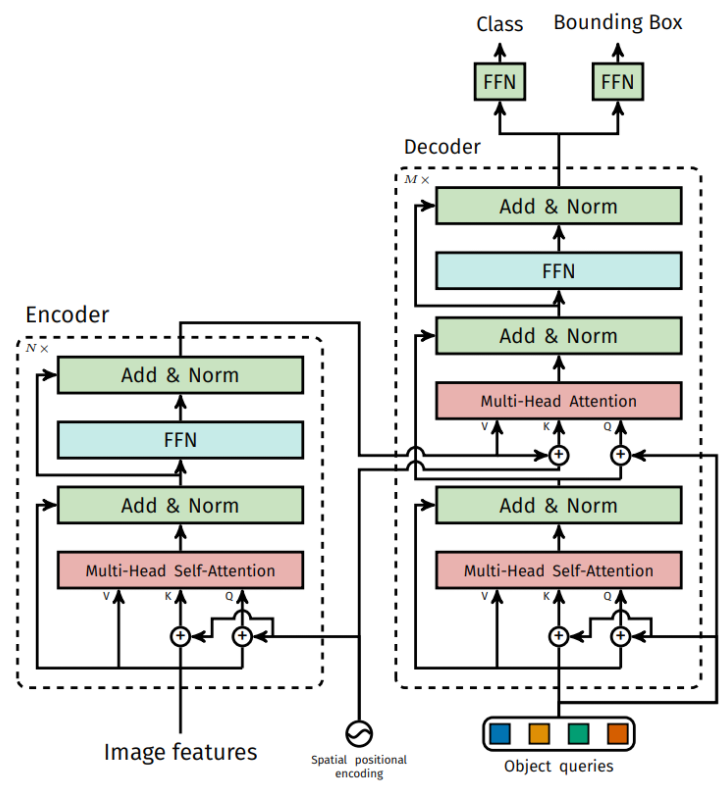
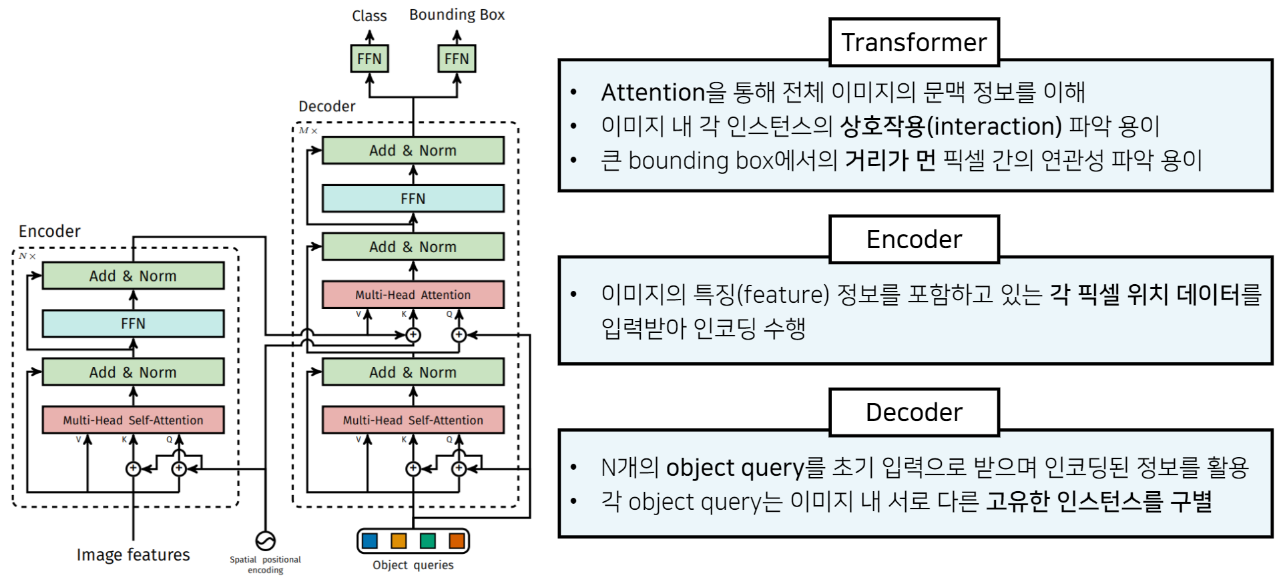
- What’s DETR (DEtection TRansformer)
- Transformer on Object Detection
- Contribution
- Object Detection -> “direct set prediction” 새로운 방법 제시
- 이로써 NMS와 같은 heuristic 단계를 효과적으로 제거
- Encoder-Decoder 기반 Transformers
- Sequence prediction 방법
- Transformer Self-attention 역할
- 각 Sequence 간의 소통 -> feature 간의 연관성
- 중복된 prediction 제거 (NMS 제거)
- 기존 Faster-RCNN과 비슷한 성능을 보임
- 간단한 재 구현성
- 기존 Resnet\, transformer 로만 구현 가능
- Object Detection -> “direct set prediction” 새로운 방법 제시
DETR: End-to-End Object Detection with Transformers\, ECCV 2020
- Detail
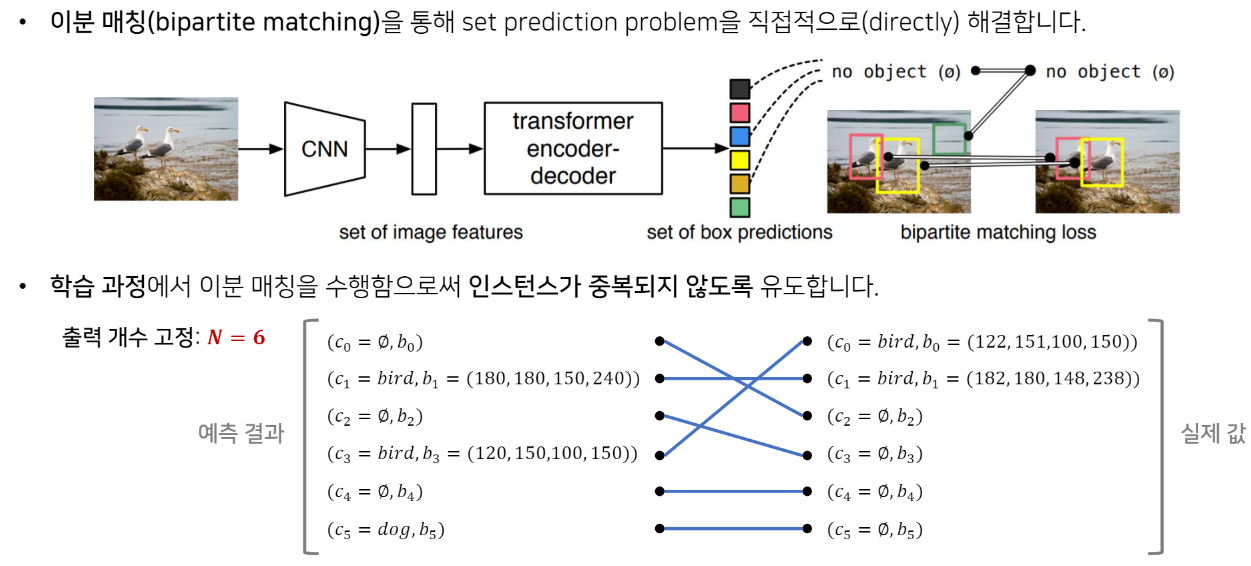
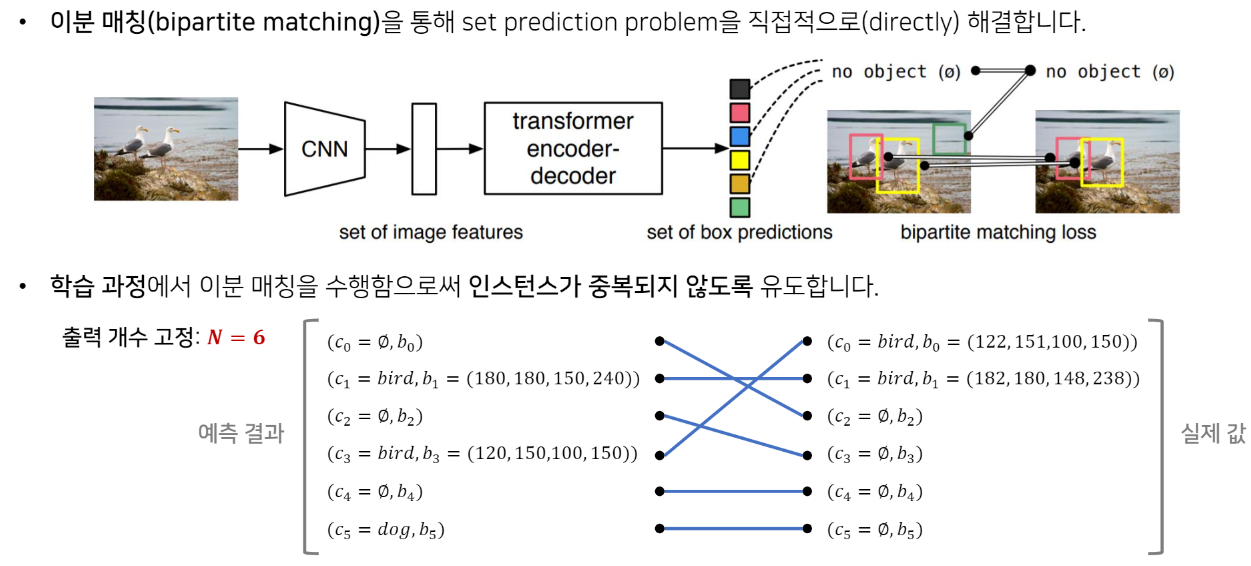
- Bipartite matching 을 통해 set prediction problem 직접적으로 해결
- Training에서 Bipartite matching 을 통해 instance가 중복되지 않도록 유도함
- Attention map visualization
- Last Encoder layer attention map visualization
- Transformer Encoder가 이미지 내의 Instance를 분리
- Decoder가 object extraction과 localization을 용이하게 함
- Last Encoder layer attention map visualization

-
Attention map visualization
- Last Decoder layer attention map visualization
* Decoder가 일반적으로 각 object의 edge에 초점을 두고 있음
- Last Decoder layer attention map visualization
-
Problem of DETR
- DETR suffers from significantly slow training convergence
- Ineffective design and use of queries
- Usually requiring 500 epochs to achieve a good performance
- Role of the learned queries in DETR is still not fully understood or utilized.
- DETR suffers from significantly slow training convergence
Deformable DETR: Deformable Transformers for End-to-End Object Detection\, ICLR\, 2021
Efficient DETR: Improving End-to-End Object Detector with Dense Prior\, ArXiv\, 2021 (Will be published in ICCV 2022)
- Problem of DETR
- Follow-up works for both faster training convergence and better performance
- Deformable DETR
- 2-D reference point를 query처럼 사용하고\, cross-attention 시 각 reference point와 연산을 실시한다.
- Efficient DETR
- object query들 중 top K를 선택하는 dense prediction을 사용한다
- Conditional DETR
- image feature와 더 잘 맞도록 content feature를 바탕으로 "conditional query"를 학습한다.
- Deformable DETR
- Only leverage 2D positions as anchor points without considering the object scales
- Follow-up works for both faster training convergence and better performance
Deformable DETR: Deformable Transformers for End-to-End Object Detection\, ICLR\, 2021
Efficient DETR: Improving End-to-End Object Detector with Dense Prior\, ArXiv\, 2021 (Will be published in ICCV 2022)
- Propose new query formulation
- use anchor boxes\, i.e.\, 4D box coordinates (x\, y\, w\, h)\, as queries and update them layer by layer
- Spatial point와 함께 scale 정보가 들어 있어 scale 고려가 가능
Key Insight of DETR
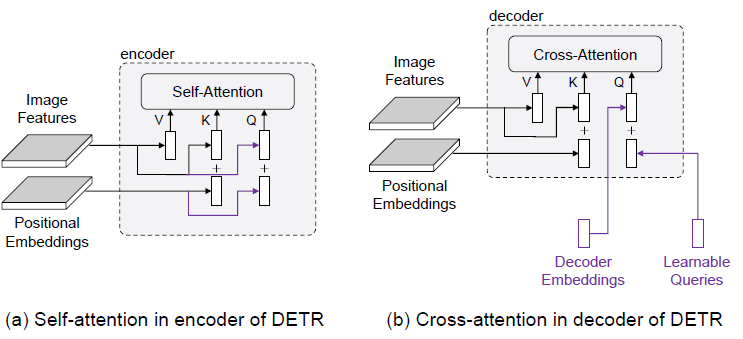
- Query
- Content part (decoder self-attention output)
- Positional part (learnable queries in DETR)
- Key for cross attention
- Content part (encoded image feature)
- Positional part (positional embedding)
- Interpreted
- as pooling features from a feature map based on the query-to-feature similarity measure
- cross-attention 연산 후 만들어지는 decoder embedding이 다시 query로 쓰임
- as pooling features from a feature map based on the query-to-feature similarity measure
3 WHY A POSITIONAL PRIOR COULD SPEEDUP TRAINING?
- Prior Work (Sun et al. Rethinking transformer-based set prediction for object detection)
- Cross-attention module is mainly responsible for the slow convergence
- Simply removed the decoders for faster training.
- Cross-attention module is mainly responsible for the slow convergence
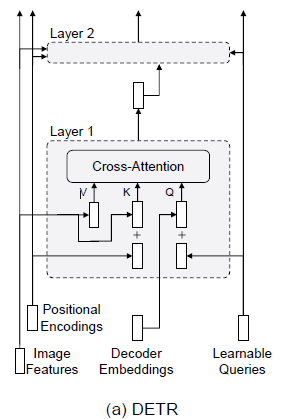
- Encoder self-attention vs Decoder cross-attention
- Key Diff: Inputs from the queries
- Decoder Emb
- Projected to image feature
- Root Cause: learnable queries

-
Two possible reasons
- 1) it is hard to learn the queries due to the optimization challenge
- 2) the positional information in the learned queries is not encoded in the same way as the sinusoidal positional encoding used for image features
-
First reason (optimization challenge)
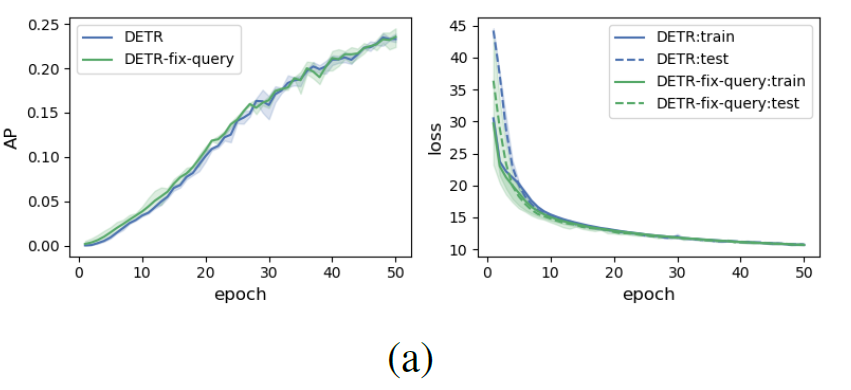
- reuse the well-learned queries from DETR (keep them fixed) and only train the other modules
- Query learning (or optimization) is likely not the key concern
- Second reason (positional information issue)
- visualize a few positional attention maps
- between the learned queries and the positional embeddings of image feature
- visualize a few positional attention maps

- Undesirable properties
- multiple modes and nearly uniform attention weights
- two or more concentration centers
- making it hard to locate objects when multiple objects exist in an image
- focus on areas that are either too large or small
- cannot inject useful positional information
- two or more concentration centers
- multiple modes and nearly uniform attention weights
- explicit positional priors
- to constrain queries on a local region


Cross-attention
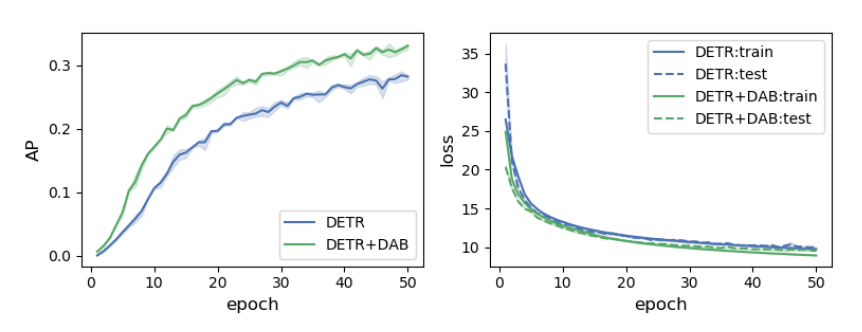
- DETR+DAB
- Note that the only difference between DETR and DETR+DAB is the formulation of queries
- can achieve both a faster training convergence and a higher detection accuracy
Cross-attention
- vs Conditional DETR
- explicit positional embedding as positional queries for training\,
- yielding attention maps similar to Gaussian kernels
- they ignore the scale information of an object


Introduction
Key Insight of DETR
-
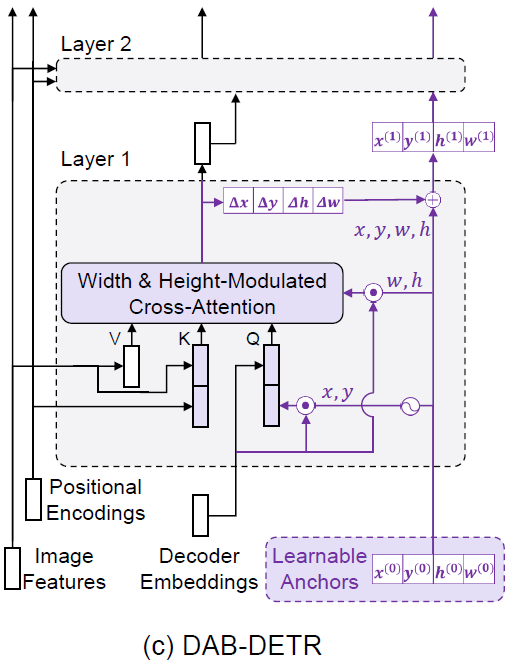
center position (x\, y)
- allowing us to use an anchor box to pool features around the center
-
anchor box size (w\, h)
- modulate the cross-attention map\, adapting it to anchor box size
-
positional constraint
- Focus on a local region corresponding to a target object
- also facilitate to speed up the training convergence
-
DAB-DETR
- Novel query formulation using dynamic anchor boxes (DAB) for DETR
- Offer a deeper understanding of the role of queries in DETR
- Directly uses box coordinates as queries and dynamically updates them layer by layer
- 1. Query - Feature 간 similarity 향상
- 2. DETR 에서 training convergence 속도가 느렸던 점을 개선
- 3. Positional attention map 을 직접 box 의 width\, height 정보를 통해 조절 가능
4 DAB-DETR
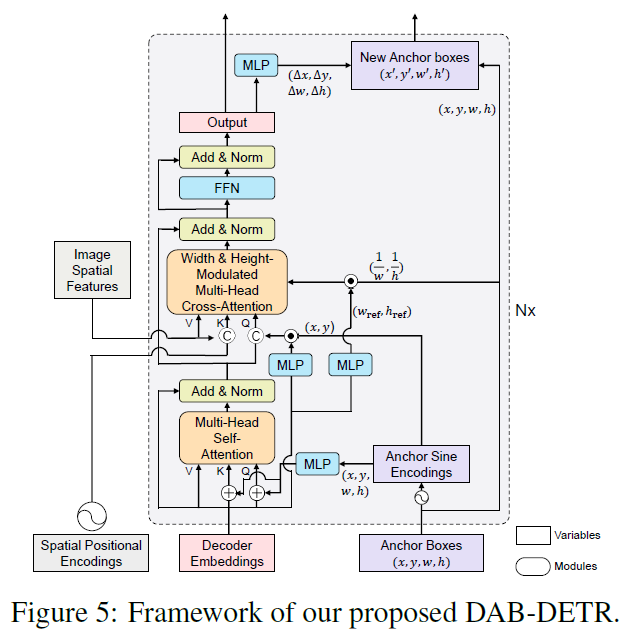
Transformer decoder part
- Dual queries fed into the decoder
- Dual query
- Positional queries (anchor boxes)
- content queries (decoder embeddings)
- objects which correspond to the anchors and have similar patterns with the content queries
- Dual query
- The dual queries are updated layer by layer
- to get close to the target ground-truth objects gradually
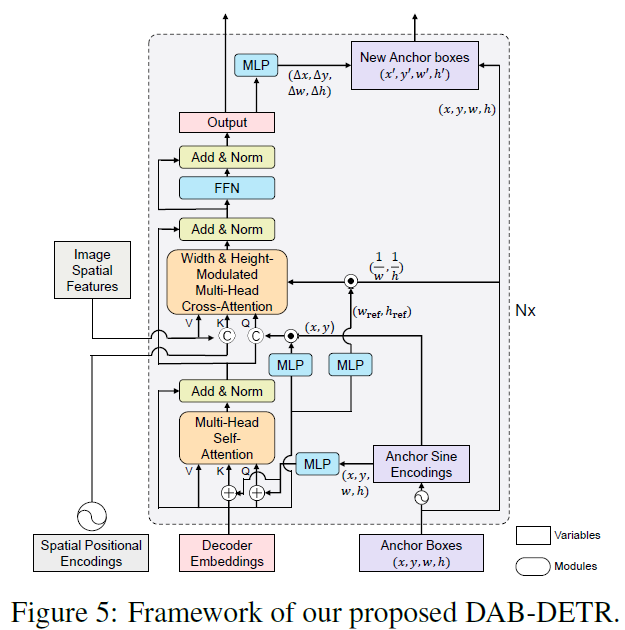
Learning Anchor Boxes Directly
- Positional Encoding (PE)
- Anchor\, Content query\, Positional query
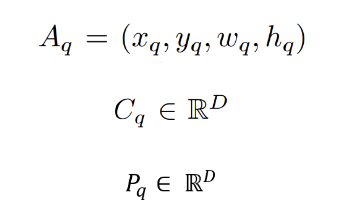
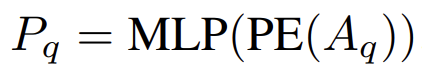
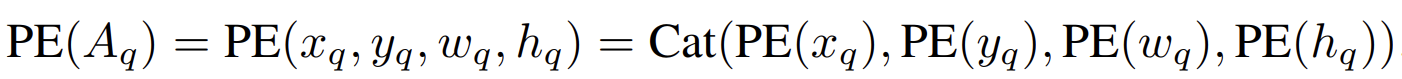
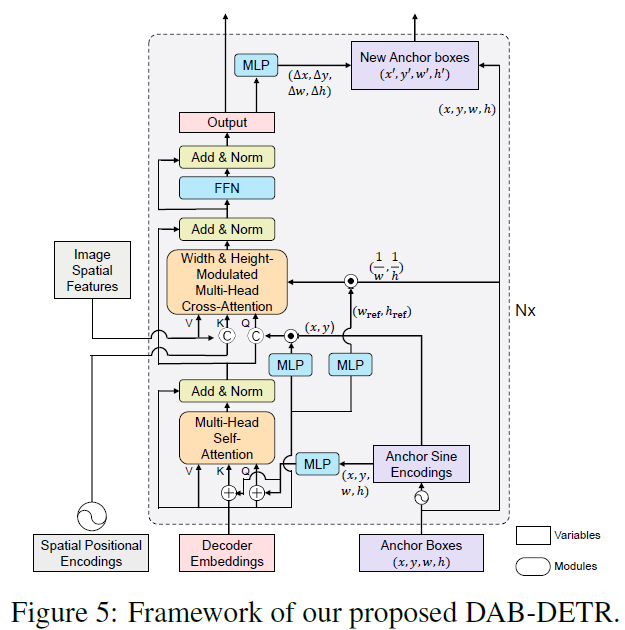
Learning Anchor Boxes Directly
- Self-attention for query update
- all three of queries\, keys\, and values have the same content items
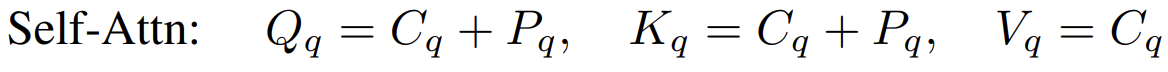
- all three of queries\, keys\, and values have the same content items
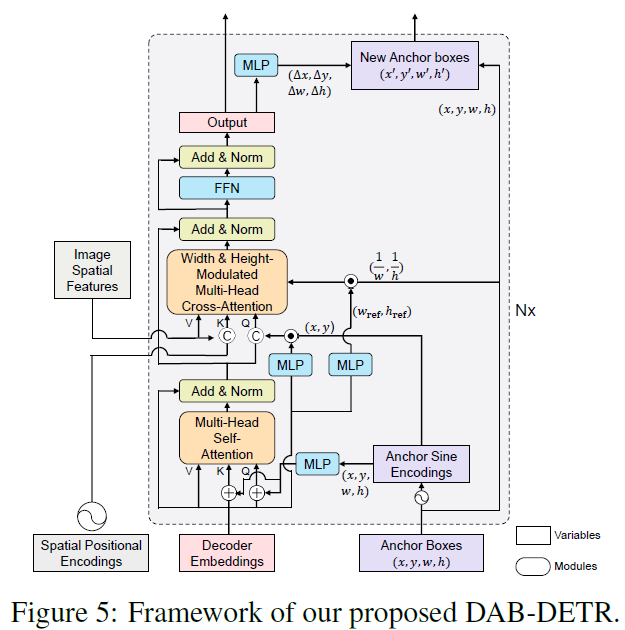
Learning Anchor Boxes Directly
Cross-Attention for feature probing