31st Jan 2023
SQL 스터디를 시작했다.
목표는 한달안에 프로그래머스 SQL 고득점 Kit을 푸는 것이다.
풀면서 배운 내용을 여기에 정리해보려고 한다.
24th Feb 2023
목표대로 프로그래머스 SQL 고득점 Kit을 다 풀었다.
확실히 스터디를 진행하니까 좋은 자극을 받고 덕분에 끝까지 열심히 풀 수 있었던 것 같다. 스터디 같이 하자고 먼저 제안해준 분께 매우 감사하다.
Convention
Reference: https://www.sqlstyle.guide/
- snake_case
- Use upper case for reserved keywords (e.g. SELECT, WHERE)
- singular Table names ideal
- singular Column names
- Aliasing (AS) should be the first letter of each word in object's name
- Indentations for JOIN or sub-queries
문법
Overall
SELECT *
FROM TABLE
WHERE CONDITION1
GROUP BY COLUMN1
HAVING CONDITION2
ORDER BY COLUMN2
LIMIT n;Subquery
Uncorrelated (비상관)
IN - check if a value matches any value in a subquery (or a list)
Correlated (상관)
EXISTS - check if a subquery returns at least one row (TRUE or FALSE)
SELECT column_name(s)
FROM table_name
WHERE EXISTS
(SELECT column_name FROM table_name WHERE condition);vs. JOIN
- Subquery: readability
- JOIN: performance
JOIN
vs. selecting from multiple tables
- JOIN is better because you separate join conditions and filtering conditions
Single JOIN
SELECT a.COLUMN1, b.COLUMN1
FROM TABLE1 AS a JOIN TABLE2 AS b
ON a.key=b.key;Multiple JOINS
SELECT *
FROM TABLE1 a
JOIN TABLE2 b
ON a.key=b.key
JOIN TABLE3 c
ON b.key=c.keyWe can use USING subclause instead if the join columns have identical names
In MySQL, JOIN, CROSS JOIN and INNER JOIN are syntactic equivalents.
(INNER) JOIN
returns records that have matching values in both tables
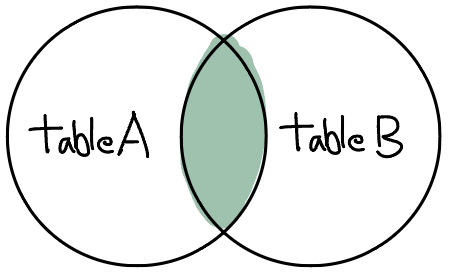
Sometimes, we use INNER JOIN to write self join queries.
SELECT e1.name, e2.name
FROM Employee e1
JOIN Employee e2
ON e1.id!=e2.id AND e1.dob=e2.dob;LEFT (OUTER) JOIN
returns all records from the left table, and the matched records from the right table
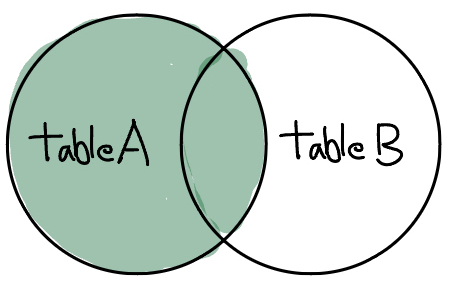
SELECT a.COLUMN1, b.COLUMN1
FROM TABLE1 a
LEFT JOIN TABLE2 b
ON a.key=b.key;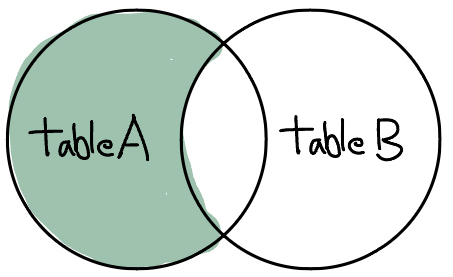
SELECT a.COLUMN1, b.COLUMN1
FROM TABLE1 a
LEFT JOIN TABLE2 b
ON a.key=b.key
WHERE b.key IS NULL;RIGHT (OUTER) JOIN
returns all records from the right table, and the matched records from the left table
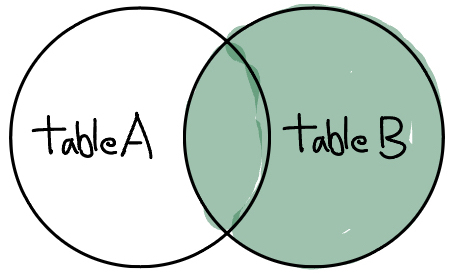
SELECT a.COLUMN1, b.COLUMN1
FROM TABLE1 a
RIGHT JOIN TABLE2 b
ON a.key=b.key;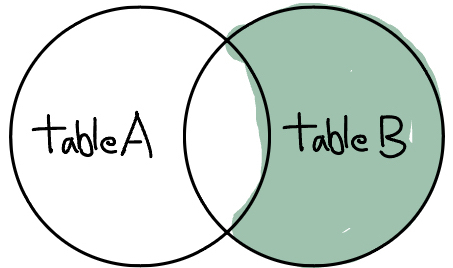
SELECT a.COLUMN1, b.COLUMN1
FROM TABLE1 a
RIGHT JOIN TABLE2 b
ON a.key=b.key
WHERE a.key IS NULL;FULL (OUTER) JOIN
returns all records from both tables
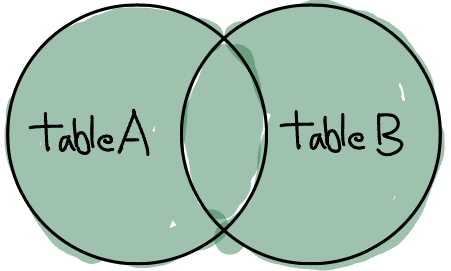
SELECT a.COLUMN1, b.COLUMN1
FROM TABLE1 a
FULL JOIN TABLE2 b
ON a.key=b.key;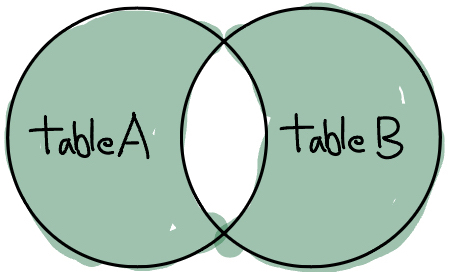
SELECT a.COLUMN1, b.COLUMN1
FROM TABLE1 a
FULL JOIN TABLE2 b
ON a.key=b.key
WHERE a.key IS NULL OR b.key IS NULL;CROSS JOIN
produces the Cartesian product of the named tables, producing every permutation of their rows
NATURAL JOIN
creates an implicit join clause based on the common columns (identical names and data types)
ORDER BY (정렬)
정렬의 기본값은 ASC(오름차순)이다.
SELECT * FROM TABLE ORDER BY COLUMN1;
SELECT * FROM TABLE ORDER BY COLUMN1 ASC;즉, 위 statement들은 동일하다.
내림차순, 역순 정렬은 DESC이다.
조회한 열과 정렬하는 열이 같을 경우 잡기술이 있다.
SELECT COLUMN1, COLUMN2 FROM TABLE ORDER BY COLUMN1, COLUMN2 DESC;
SELECT COLUMN1, COLUMN2 FROM TABLE ORDER BY 1, 2 DESC;위 statement들은 동일하다. COLUMN1의 경우 기본값인 오름차순 정렬이다.
In MySQL, NULL values are sorted first in ascending order (and last in descending order) - NULL values are considered "lower" than any non-NULL values.
Aggregate Functions
COUNT(), MAX(), MIN(), SUM(), AVG()
- COUNT(*) returns ALL rows, COUNT(COLUMN) ignores NULL values
- SUM(COLUMN), AVG(COLUMN) also ignore NULL values
MIN(), MAX()
- date: MAX() returns the most recent, MIN() returns the oldest
GROUP BY (그룹화)
SELECT COLUMN1, COUNT(COLUMN2) AS count
FROM TABLE
GROUP BY 1
HAVING count>=2
ORDER BY 1;GROUP BY도 ORDER BY와 동일한 잡기술이 적용된다.
HAVING vs. WHERE
- WHERE can't be used with aggregate functions
- filter rows based on conditions that are applied to individual columns
- HAVING can be used with aggregate funtions
- filter groups of rows based on aggregate function values
Rollups can be generated on multicolumn groups using the WITH ROLLUP clause after the GROUP BY clause.
- totals and subtotals
String Manipulation
Under WHERE clause
- Equals to: COLUMN = 'A'
- Not equals to: COLUMN != 'A'
- Starting with: COLUMN LIKE 'A%'
- Ending with: COLUMN LIKE '%A'
- Including: COLUMN LIKE '%A%'
INSTR(toBeSearched, toSearch)
- returns starting position of "toSearch" in "toBeSearched"
- returns 0 if not found
SUBSTRING(string, start, length)
- In SQL, we start index as 1
LEFT(string, length)
RIGHT(string, length)
LPAD(string, length, padding)
- left-pad the string with padding, to given length
CONCAT(string1, string2, ...) AS newString
- to add separators in between, add them to the argument as an expression
Date Manipulation
날짜 데이터에서 일부만 추출하기
- YEAR(날짜)
- MONTH(날짜)
- DAY(날짜)
- HOUR(날짜)
- MINUTE(날짜)
- SECOND(날짜)
날짜 형식 맞추기
DATE_FORMAT(COLUMN, '%Y-%m-%d')- %Y 4자리, %y 2자리
- %M 영문, %m 숫자
- %D 영문, %d 숫자
DATEDIFF(날짜1, 날짜2)
- (날짜1-날짜2)를 일수로 반환
NULL처리
Under WHERE clause
- IS NULL
- IS NOT NULL
NULL 대체
- COALESCE(COLUMN, value)
- IFNULL(COLUMN, value)
etc.
중복 제거 DISTINCT
SELECT DISTINCT COLUMN FROM TABLE;BETWEEN value1 and value2
- values can be numbers, text, or dates
- inclusive on both ends
LIMIT
SELECT * FROM TABLE LIMIT n;- n개 조회
SELECT * FROM TABLE LIMIT a, b;- query b rows starting from a (NOT rows a to b)
ROUND(number, dp)
- rounds a number TO specified decimal places (0 would be integer)
- negative possible
TRUNCATE(number, dp)
- truncates a number TO specified decimal places
- negative possible
CAST(value AS datatype)
- DATE ("YYYY-MM-DD")
- DATETIME ("YYYY-MM-DD HH:MM:SS")
- TIME ("HH:MM:SS")
- DECIMAL
- CHAR (a fixed length string)
- SIGNED (a signed 64-bit integer)
- UNSIGNED (an unsigned 64-bit integer)
- BINARY (a binary string)
COLUMN1 값을 기반으로 새로운 COLUMN 생성/조회하기
SELECT if(condition, true_value, false_value) COLUMN FROM TABLE;CASE
CASE
WHEN CONDITION1 THEN RESULT1
WHEN CONDITION2 THEN RESULT3
WHEN CONDITION3 THEN RESULT3
ELSE 'NONE'
END AS COLUMN_NAMEUNION & UNION ALL
UNION - combine the result of 2+ SELECT statements (must have the same number of columns)
(
SELECT * FROM TABLE1
)
UNION
(
SELECT * FROM TABLE2
)
ORDER BY 1;- () not necessary but more readable (any SELECT statement inside shouldn't have ;)
- any conditionals go inside each statement
UNION ALL selects duplicate values as well (as opposed to UNION)
INTERSECT: the result is all the row values common to both tables
EXCEPT: the result is all the row values in the 1st table but not in the 2nd table
Virtual Table
with newT as (
SELECT *
FROM TABLEA
WHERE condition;
)
SELECT * FROM newT;Virtual Table + RECURSIVE
with RECURSIVE 테이블 as (
SELECT 초기값 AS COLUMN
UNION ALL
SELECT COLUMN1 계산식 FROM 테이블 WHERE 조건문
)
SELECT * FROM 테이블;예를 들자면,
with RECURSIVE t as (
SELECT 1 AS h
UNION ALL
SELECT h+1 FROM t WHERE h<5
)
SELECT * FROM t;를 실행하면 아래와 같은 테이블을 조회한다.
| h |
|---|
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
로컬 변수
SET @HOUR:=-1;
SELECT (@HOUR:=@HOUR+1) AS HOUR,
(SELECT COUNT(*) FROM ANIMAL_OUTS WHERE HOUR(DATETIME)=@HOUR) AS COUNT
FROM ANIMAL_OUTS
WHERE @HOUR<23;- -1부터 22까지 +1씩 더한다 - 즉 HOUR 컬럼 값은 0~23이다.
정규식 (REGEXP, Regular Expression)
https://www.geeksforgeeks.org/mysql-regular-expressions-regexp/
https://steemit.com/mysql/@seobangnim/mysql-regexp
추후 정리 필
