집계함수(Aggregate function)의 이해
집계함수란
여러 행 또는 테이블 전체 행으로 부터 하나의 결과 값을 반환하는 함수
집계함수의 이해
- GROUP BY 절을 이용하여 그룹당 하나의 결과로 그룹화 할 수 있다.
- HAVING 절을 사용하여 집계함수를 이용한 조건 비교를 할 수 있다.
- MIN,MAX함수는 모든 자료형에 사용할 수 있다.
- 일반적으로 가장 많이 사용하는 집계함수에는 AVG(평균), COUNT(개수), MAX(최대값), MIN(최소값),SUM(합계)가 있다.
COUNT
COUNT함수는 검색된 행의 수를 반환함
---검색된 행의 총 수 4개를 반환, 즉 4개의 부서가 존재
SELECT COUNT(deptno) FROM dept;
COUNT(DEPTNO)
------------
4MAX
MAX함수는 컬럼값 중에서 최대값을 반환함
--- sal 컬럼값중 제일 큰값을 반환-> 가장 큰 급여를 반환
SELECT MAX(sal) salary FROM emp;
SALARY
---------
50000MIN
MIN함수는 컬럼값 중에서 최소값을 반환
---sal 컬럼값 중에서 가장 작은 값을 반환
SELECT MIN(sal) salary FROM emp;
SALARY
---------
3000AVG
AVG함수는 평균값을 반환함
---부서번호 30의 사원의 평균급여를 소수점 1자리 이하에서 반올림
SELECT ROUND(AVG(sal),1) salary
FROM emp
WHERE deptno =30;
SALARY
------
1566.7SUM
SUM함수는 검색된 컬럼의 합을 반환
----부서번호 30의 사원 급여 합계를 조회
SELECT SUM(sal) salary
FROM emp
WHERE deptno =30;
SALARY
--------
9490집계함수의 예
아래는 부서별 사원수,최대급여,최소급여,급여합계,평균급여를 급여 합계순으로 조회하는 예
SEELCT detpno 부서번호, COUNT(*) 사원수,
MAX(sal) 최대급여, MIN(sal) 최소급여,
SUM(sal) 급여합계, ROUND(AVG(sal)) 평균급여
FROM emp
GROUP BY depno
ORDER BY SUM(sal) DESC;
부서번호 사원수 최대급여 최소급여 급여합계 평균급여
------- -------- --------- -------- --------- ---------
20 5 3000 800 10875 2175
30 6 2850 950 9400 1567
10 3 5000 1300 8750 2917GROUP BY 와 HAVING절
GROUP BY 절
- GROUP BY절은 데이터들을 원하는 그룹으로 나눌 수 있다.
- 나누고자 하는 그룹의 컬럼명을 SELECT 절과 GROUP BY절 뒤에 추가하면됨
- 집계함수와 함께 사용되는 상수는 GROUP BY 절에 추가하지 않아도 됨
- 아래의 예제는 집계함수와 상수가 함께 SELECT 절에 사용되는 예
---부서별 사원수 조회
SELECT '2005년' year, deptno 부서번호, COUNT(*) 사원수
FROM emp
GROUP BY deptno
ORDER BY COUNT(*) DESC;
YEAR 부서번호 사원수
----- ------- ------
2005년 30 6
2005년 20 5
2005년 10 3--부서별로 그룹화화여 부서번호, 인원수, 급여평균, 급여합을 조회하는 예제
SELECT deptno, COUNT(*), ROUND(AVG(sal)) "급여평균", ROUND(SUM(sal)) "급여합계"
FROM emp
GROUP BY deptno;---업무별로 그룹화하여 업무,인원수,평균급여액, 최고급여액,최저급여액 및 합계를 조회하는 예제
SELECT job, COUNT(empno) "인원수", AVG(sal) "평균급여액", MAX(sal) "최고급여액" , SUM(sal) "급여합계"
FROM emp
GROUP BY job;
JOB 인원수 평균급여액 최고급여액 최저급여액 급여합계
----------- -------- ---------- ---------- ---------- ----------
CLERK 4 1037.5 1300 800 4150
SALESMAN 4 1400 1600 1250 5600
PRESIDENT 1 5000 5000 5000 5000
MANAGER 3 2758.33333 2975 2450 8275
ANALYST 2 3000 3000 3000 6000 - GROUP BY 절은 집계함수없이 사용될수 있다 (DISTICT 와 용도가 비슷해진다)
---GROUP BY를 이용한 부서번호 조회 예( GROUP BY 그룹을 나누는 역할을 한다)
SELECT deptno
FROM emp
GROUP BY deptno;
DEPTNO
-------
30
20
10
DISTINCT와 GROUP BY절 비교하기
- DISTINCT는 주로 UNIQUE(중복을제거)한 컬럼이나 레코드를 조회하는 경우에 사용된다.
- GROUP BY는 데이터를 그룹핑해서 그 결과를 가져오는 경우 사용
- 두 작업을 조금만 더 생각해보면 동일한 형태임을 알 수 있다. 일부의 작업의 경우 DISTINCT와 동시에 GROUP BY로도 처리될 수 있는 쿼리들이 있다
- 두 기능 모두 Oracle9i까지는 sort를 이용하여 데이터를 만들었지만, Oracle10g 부터는 모두 Hash를 이용하여 처리한다.
- 그래서 DISTINCT를 사용해야 할지, GROUP BY를 사용해서 데이터를 조회하는 것이 좋을지 고민되는 경우들이 가끔 있다.
아래의 예제는 동일한 결과를 반환
--- DISTINCT를 사용한 중복 데이터 제거
SELECT DISTINCT deptno FROM emp;
--- GROUP BY를 이용한 중복데이터 제거
SELECT deptno FROM emp GROUP BY deptno;
DEPTNO
------
30
20
10BUT, DISTINCT와 GROUP BY는 각각 고유한 기능들이 有
집계함수를 사용하여 특정 그룹으로 구분할 때는 GROUP BY,
특정 그룹 구분없이 중복된 데이터를 제거할 경우는 DISTINCT사용
--- DISTINCT를사용하는것이 훨씬 효율적인 예쩨
SELECT COUNT(DISTINCT d.deptno) "중복 제거수",
COUNT(d.deptno) "전체 수"
FROM emp e , dept d
WHERE e.deptno = d.deptno;
--집계함수가 필요한 경우에는 GROUP BY 절을 사용
SELECT deptno, MIN(sal)
FROM emp
GROUP BY deptno;HAVING절
WHERE 절에서는 집계함수를 사용할수 없다.
그렇기 떄문에 HAVING절을 이용해서 집계함수를 가지고 조건 비교를 할 때 사용한다.
HAVING절은 GROUP BY 절과 함께 사용된다.
아래 예제는 사원수가 5명이 넘는 부서와 사원수를 조회하느 예제
SELECT b.dname, COUNT(a.empno) "사원수"
FROM emp a, dept b
WHERE a.deptno = b.deptno
GROUP BY b.dname
HAVING COUNT(a.empno) > 5;
DNAME 사원수
------- -------
SALES 6아래 예제는 전체 월급이 5000을 초과하는 JOB에 대해서 JOB과 월급여 합계를조회하는 예, 단 판매원(SALES)는 제외하고 월 급여 합계로 내림차순 정렬
SELECT job, SUM(sal) "급여합계"
FROM emp
WHERE job != 'SALES'
GROUP BY job
HAVING COUNT(sal) >5000
ORDER BY SUM(sal) DESC;Subquery?
Subquery란?
Subquery는 다른 하나의 SQL문장의 절에 NESTEDED된 SELECT문장이다
SELECT, UPDATE,DELETE, INSERT와 같은 DML문과 CREATE TABLE또는 VIEW의 WHERE절이나 HAVING절에서 사용 된다.
보통 Subquery는 Main Query이전에 한번 실행되며 Subquery는 괄호로 묶여야한다.
- 단일 행 연산자(=,>,>=,<,<=,<>,!=)와 다중 행 연산자(IN,NOT,IN,ANY,ALL,EXISTS)들이 서브쿼리에 사용 됨
- Subquery는 연산자의 오른쪽에 위치해야 함
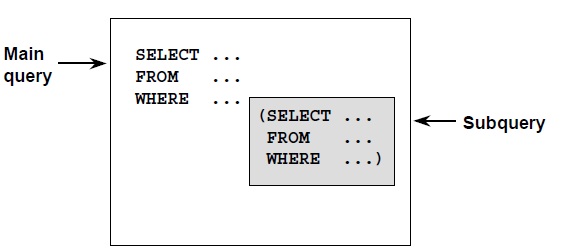
서브쿼리의 유형
- 단일행(Single-Row)서브쿼리: SELECT문장으로부터 오직 하나의 행만을 검색하는 질의
- 다중행(Multiple-Row)서브쿼리: SELECT문장으로부터 하나 이상의 행을 검색하는 질의
- 다중 열(Multiple-Column)서브쿼리: SELECT문장으로부터 하나 이상의 컬럼을 검색하는 질의
- FROM절상의 서브쿼리(INLINE VIEW): FROM절상에 오는 서브쿼리로 VIEW처럼 작동한다
- 상관관계 서브쿼리: 바깥쪽 쿼리의 컬럼중 하나가 안쪽 서브쿼리의 조건에 이용되는 처리방식
Single-Row Subquery
- SELECT문장에서 오직 하나의 행(값)만 반환하는 Query
- 단일 행 연산자(=,>,>=,<,<=,<>,!=)만 사용함
---empno가 7369의 job을 조회 한 후 job이 'CLERK'인 사원의 이름과 작업을 반환
SELECT ename , job
FROM emp
WHERE jon = (SELECT job
FROM emp
WHERE empno=7369);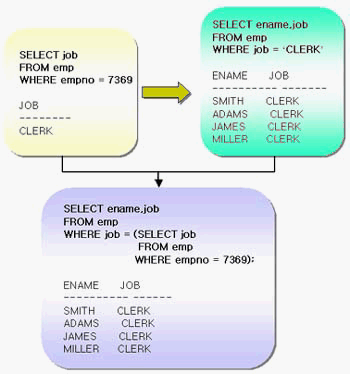
Multiple -Row Subquery
Multiple -Row Subquery란?
- 하나이상의 행을 반환하는 Subquery다
- 단일 행 연산자를 사용하지 못하며 다중행 연산자(IN,NOT,IN,ANY,ALL,EXISTS) 만 사용이 가능
IN 연산자
- IN연산자는 하나의 컬럼이 여러개의 '='조건을 가지는 경우에 사용
- OR는 IN을 포함한다. IN을 사용해 표현 할 수 있는 것은 당연히 OR로 표현할 수 있다.
- 하지만 OR로 표현한것은 IN으로 표현하지 못할 때가 있음(OR에서 LIKE같은 연산자를 사용한 경우)
- IN은 반드시 하나의 컬럼이 비교되어야 하므로 나중에 인덱스 구성에 대한 전략을 수립할 떄 유리함
- 그러므로 OR보다는 IN을 사용하는것이 좋다
--- 부서별로 가장 급여를 많이 받는 사원의 정보를 출력하는 예제
SELECT empno,ename, sal, deptno
FROM emp
WHERE sal IN (SELECT MAX(sal)
FROM emp
GROUP BY deptno);
EMPNO ENAME SAL DEPTNO
----- ------- ------- ---------
7698 BLAKE 2850 30
7788 SCOTT 3000 20
7902 FORD 3000 20ANY연산자
- ANY 연산자는 Subquery의 여러 결과값중 어느 하나의 값만 만족이 되면 행을 반환
---SALESMAN 직업의 급여보다 많이 받는 사원의 사원명과 급여 정보를 출력하는 예제
SELECT ename, sal
FROM emp
WHERE deptno != 20
AND sal > ANY(SELECT sal
FROM emp
WHERE job = 'SALESMAN');
ENAME SAL
----------- --------
ALLEN 1600
BLAKE 2850
CLARK 2450 ALL 연산자
- ALL연산자는 Subquery의 여러 결과값중 모든 결과값을 만족해야 행을 반환
--- 모든 SALESMAN직업의 급여보다 많이받는 사원의 사원명과 급여정보를 출력하는 예제
SELECT ename , sal
FROM emp
WHERE deptno != 20
AND sal > ALL(SELECT sal
FROM emp
WHERE job ='SALESMAN');
ENAME SAL
--------- -------
CLARK 2450
BLAKE 2850
KING 5000 EXISTS 연산자
- EXISTS연산자는 Subquery데이터가 존재하는가를 체크해 존재여부(TRUE,FALSE)를 결과로 반환
- EXISTS절에는 반드시 메인 쿼리와 연결되는 조인조건을 가지고 있어야함
- subquery에서 결과행을 찾으면 ,inner query 수행을 중단하고 TRUE를 반환
---아래의 예처럼 emp 테이블을 통해 사원들이 속한 부서번호의 정보만 조회하는 경우
--- 추출하고자 하는 대상은 dept 테이블이지만 emp 테이블과 조인하여 부서번호를 체크해야한다
--- 두 테이블의 관계가 1:M이므로 불필요하게 emp 테이블을 모두 엑세스하고 DISTINCT로 중복 제거를 한다
SELECT DISTINCT d.deptno, d.dname
FROM dept d , emp e
WHERE d.deptno =e.detpno;
--EXISTS를 사용하는 Subquery로 변경
-- 추출하고자 하는 대상만을 FROM절에 놓고 emp테이블은 체크만 하기 위해 EXISTS절에 위치시켰으며 이로 인해 수행속도가 대폭 감소하게 됨
SELECT d.deptno, d.dname
FROM dept d
WEHER EXISTS( SELECT 1
FROM emp e
WHERE e.deptno=d.deptno);
Multiple-Column Subquery란?
결과 값이 두 개 이상의 컬럼을 반환하는 Subquery이다.
Pairwise(쌍비교) Subquery
Subquery가 한번 실행되면서 두 개 이상의 컬럼을 검색해서 주 쿼리로 넘겨준다.
SELECT empno,sal, deptno
FROM emp
WHERE (sal, deptno) IN (SELECT sal, deptno
FROM emp
WHERE deptno = 30
AND comm is NOT NULL);
EMPNO SAL DEPTNO
------- --------- -----------
7521 1250 30
7654 1250 30
7844 1500 30
7499 1600 30Nonpairwise(비쌍비교) Subquery
WHERE 절에서 두 개 이상의 서로 다른 Subquery가 사용되어서 결과 값을 주 쿼리로 넘겨줌
SELECT empno, sal ,deptno
FROM emp
WHERE sal IN (SELECT sal
FROM emp
WHERE deptno =30
AND comm is NOT NULL);
AND deptno IN (SELECT deptno
FROM emp
WHERE deptno = 30
AND comm is NOT NULL);Null Values in a Subquery
서브쿼리에서 NULL 값이 반환되면 주 쿼리에서는 어떠한 행도 반환되지 않는다.
Inline View(From 절 Subquery)
FROM절에 오는 Subquery이다.
FROM절에서 원하는 데이터를 조회하여 가상의 집합을 만들어 조인을 수행하거나 가상의 집합을 다시 조회할때 사용함
Inlineview 안에 또다른 Inline View가 올수 있다.
---부서번호 20의 평균 급여보다 크고 부서번호 20에 속하지 않은 관리자를 조회하는 예제
SELECT b.empno, b.ename, b.job, b.sal, b.deptno
FROM (SEELCT empno
FROM emp
WHERE sal > (SELECT AVG(sal)
FROM emp
WHERE deptno = 20)) a, emp b
WHERE a.empno , b.empno
AND b.mgr is NOT NULL
AND b.deptno !=20;Scalar Subquery란?
SELECT절에서 사용하는 Subquery
Scalar Subquery의 특징
- 한개의 로우만 반환함
- 메인쿼리에서 추출되는 데이터 건 수 만큼 수행 되기 때문에 조인으로 수행될때보다 수행횟수가 적을 수 있다.
- 일치하는 값이 없는 경우 NULL을 반환함
- 코드성 테이블에서 코드값을 조회할 때 불필요한 조인을 하지 않기 위해 많이 사용함
Scalar Subquery예제
---직업이 'MANAGER" 인 사원의 사원명, 부서명을 조회하는 예제
SELECT ename,
(SELECT dname FROM dept d WHERE d.deptno=e.deptno) deptno
FROM emp e
WHERE job= 'MANAGER' ;
ENAME DEPTNO
------ --------
JONES RESEARCH
BLAKE SALES
CLARK ACCOUNTINGUNION[ALL], INTERSECT, MINUS 연산자
- UNION이나 UNION ALL의 차이는 정렬작업의 수행 여부이다.
- UNION은 중복을 제거해야 하기 때문에 정렬작업을 수행하므로 성능이 저하됨
- UNION,MINUS,INTERSECT는 전체범위를 모두 액세스 하는 정렬 작업을 수행하기 때문에 부분범위 처리가 불가능
UNION : 합집합
UNION은 두 테이블의 결합을 나타내며, 결합시키는 두 테이블의 중복되지 않은 값들을 반환함
--- 부서번호를 조회하는 UNION 예제
SELECT deptno FROM emp
UNION
SELECT deptno FROM dept;
DEPTNO
--------
10
20
30
40
UNION ALL :중복을 포함하는 합집합
UNION 과 같으나 두 테이블의 중복되는 값 까지 반환함
---부서번호를 조회하는 UNION ALL 예제
SELECT deptno FROM emp
UNION ALL
SELECT deptno FROM dept;
DEPTNO
-------
20
30
30
20
30
...
18 개의 행이 선택되었습니다.INTERSECT: 교집합
INTERSECT는 두 행의 집합중 공통된 행을 반환 한다.
-- 부서번호를 조회하는 INTERSECT 예제.
SELECT deptno FROM emp
INTERSECT
SELECT deptno FROM dept;
DEPTNO
---------
10
20
30MINUS: 차집합
MINUS는 첫 번째 SELECT문에 의해 반환되는 행 중에서 두 번째 SELECT문에 의해 반환되는 행에 존재하지 않는 행들을 반환 한다.
-- 사원이 없는 부서를 조회하는 MINUS 예제.
SELECT deptno FROM dept
MINUS
SELECT deptno FROM emp;
DEPTNO
---------
40