2019년에 블로그에 적었던 글을 옮겨 왔습니다.
평소 애용하는 쏘카에서 데이터팀 밋업을 진행한다는 소식에 비교적 간단했던 신청서를 제출했었다.
신청자가 200명 정도에서 30명을 선별하기 위해
‘만약 쏘카에서 6달 가량 인턴이나 근무를 하게된다면 사이드 프로젝트로 해보고 싶은 주제에 대해 써주세요’ 정도였던 것 같다.
나는 기술적인 부분 보다는 비즈니스적으로 전기차 수요와 충전소 관련해서 적어봤는데 예상 외로 선정메일을 받을 수 있었다.
피자 먹으러 ㄱㄱ 🍕🍤☕️🍗🍺
퇴근 하고 부랴부랴 갔더니 시작 직전이라 음식은 급하게 담아만 와서 먹으면서 참여할 수 있었다.
도미노 신매뉴랑 이것저것 많아서 👍
 처음에는 전에 다른 밋업에서도 발표해주셨던 김상우 그룹장님께서 전반적인 부분에 대해 소개해 주셨다.
처음에는 전에 다른 밋업에서도 발표해주셨던 김상우 그룹장님께서 전반적인 부분에 대해 소개해 주셨다.
 흔히 데이터 관련 직무를 하고싶거나 업무에 관심을 가질때 윗부분과 같은 접근으로 시작하는 것 같다.
흔히 데이터 관련 직무를 하고싶거나 업무에 관심을 가질때 윗부분과 같은 접근으로 시작하는 것 같다.
사실 저런 시작도 흥미 차원에서 좋지만
회사에서 일을 할때는 아랫부분처럼 어떻게 적용을 할 것인지를 고민할수 있어야하는 것 같다.
 체크리스트를 통해서 한번씩 정리 해볼수 있게 보여주기도하셨다.
체크리스트를 통해서 한번씩 정리 해볼수 있게 보여주기도하셨다.
쏘카 데이터팀에서 데이터를 바탕으로 쏘카 사업에서 효율화를 15프로 정도였나 끌어올리면서 어려웠던 부분이나 과정들을 정리하면서 이후 밋업 내내 자세하게 다뤄주셨다.
1세션.데이터를 움직이는 보이지 않는 손
다음으로 첫 세션인 가격팀의 고갱님께서 데이터를 움직이는 보이지 않는 손을 준비해주셨다
 요즘 유니콘이라 불리는 스타트업들의 공통적인 특징으로 빠르게 변화하는 시장을 짚어주셨다.
요즘 유니콘이라 불리는 스타트업들의 공통적인 특징으로 빠르게 변화하는 시장을 짚어주셨다.
 데이터를 바탕으로 분석을 하다보면 수치와 결과에 얽매이기가 쉬운데 앞의 페이지처럼 워낙 변수와 변동이 많기때문에 전체적인 이해를 바탕으로 액션을 취하는 것이 효과적이다.
데이터를 바탕으로 분석을 하다보면 수치와 결과에 얽매이기가 쉬운데 앞의 페이지처럼 워낙 변수와 변동이 많기때문에 전체적인 이해를 바탕으로 액션을 취하는 것이 효과적이다.
결국 손익문제의 개선이 중요한 부분이라고 하셨다.
 렌트카 사업의 성격상 사고율이 높고 그로인한 비용도 많기 때문에 사고율을 이용하여 나이 등에 따라 차등하거나 보장율에 따른 차이를 통해 변화를 줄 수 있었다고 한다.
렌트카 사업의 성격상 사고율이 높고 그로인한 비용도 많기 때문에 사고율을 이용하여 나이 등에 따라 차등하거나 보장율에 따른 차이를 통해 변화를 줄 수 있었다고 한다.
원래는 사고 예측을 시도하려 했으나 그게 되면 사고가 안난다는 이야기이니..
결국 모델에 대한 디버깅을 통해서 이해할 수 있어야 한다.
 결국 제때에 분석을 마치고 적용하지 않으면 아무리 정확해도 타이밍을 놓치고 헛수고가 될 수 있다.
결국 제때에 분석을 마치고 적용하지 않으면 아무리 정확해도 타이밍을 놓치고 헛수고가 될 수 있다.
가능한 적절한 선에서 결과에 집중해야한다.
쏘카 데이터 팀에서 분석 이후에 기획 및 실행관리까지 진행할 수 있다고 하셨다.
다음으로 일반적인 bias. 오류 사항들을 정리해 주셨다.
- household bias. 예를 들어 경차 비싼차의 차이점을 간과하는 경우
- nonresponse 보험료 선택이 아닌 수요로 인한 차이
- response 정성적 분석에서 오답의 오류. 거짓수요같은거
- selection 보험료선택비율을 볼때 제한을 두지않으면 선택조건이 많아지는 부분.
- word 말로인한 오류. 전달오류
 수치적으로 어려운 이유를 실제 복잡도가 높은 예를 들어 보여주셨다.
수치적으로 어려운 이유를 실제 복잡도가 높은 예를 들어 보여주셨다.
 다양하게 진행했던 주제들 소개해 주셨는데 지역 군집화를 통해서 지역별 특성을 뽑아내는 부분도 흥미로워 보였다.
다양하게 진행했던 주제들 소개해 주셨는데 지역 군집화를 통해서 지역별 특성을 뽑아내는 부분도 흥미로워 보였다.
프로젝트 진행하면서 특히 ab테스트를 적극적으로 할 수 있는 부분도 추천하셨다.
제주도의 경우 워낙 경쟁이 치열하다보니
이미 가격 자동화가 어느정도 적용되있다고 한다.
렌트카회사 가격들을 크롤링하여
남아있는 물량 등을 통해 수요를 예측하고 반영하기도 한다고 한다.
2세션. 차량파손 관련 프로젝트
다음으로 세션2로 데이터사이언스팀의 세레나님께서 차량파손 관련 프로젝트를 소개해주셨다.
앞선 주제와는 다소 상반되는 내용으로 기술적인 부분들과 과정을 자세히 다루어주셨다.
 먼저 데이터사이언스팀에서 진행하는 내용들을 소개해주시고
먼저 데이터사이언스팀에서 진행하는 내용들을 소개해주시고
딥러닝을 활용한 차량손상 탐지 모델에 대해 이어나갔다.
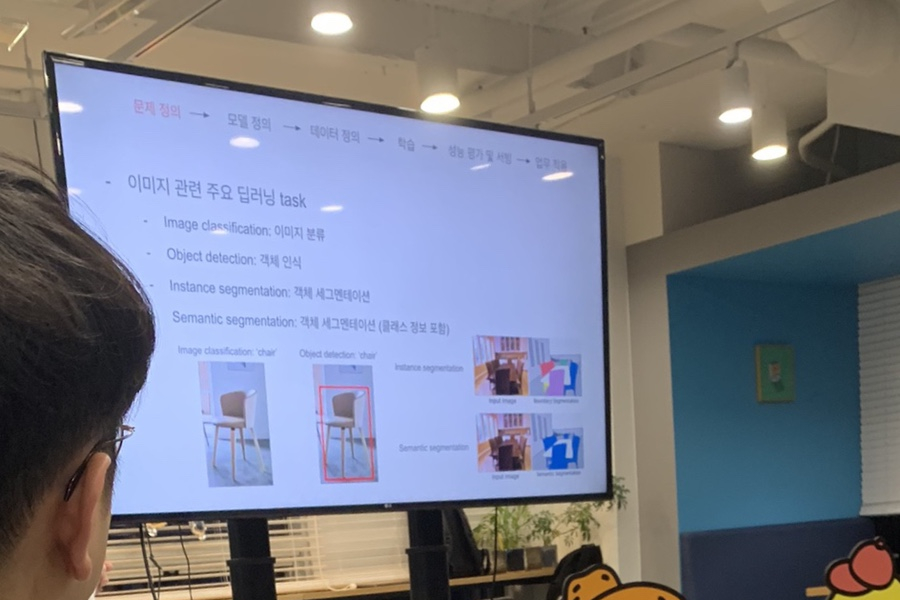 먼저 문제를 정의에 있어서 차량사진관리에 부담이 큰 상황이었고
먼저 문제를 정의에 있어서 차량사진관리에 부담이 큰 상황이었고
하루 7,8만장에서 11만장까지 사진이 쌓이고 있다고 한다.
이미지 분석에 가장 적합하게 이용될 부분을 선택하는 과정이 필요하여 시맨틱 세그민테이션이 적절한 것으로 선정한다.
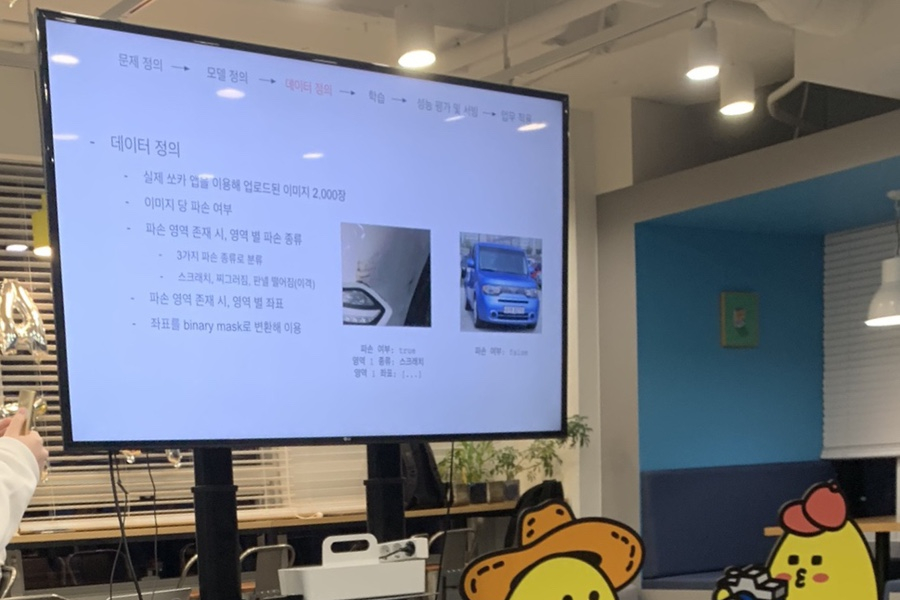 사업운영팀으로부터 어떤 종류의 파손인지 판별을 전달받았다.
사업운영팀으로부터 어떤 종류의 파손인지 판별을 전달받았다.
 학습을 통해 특정 숫자로 구분하여 기준을 정하였다.
학습을 통해 특정 숫자로 구분하여 기준을 정하였다.
문제는 실제 데이터는 제각기 다른 구도에서 찍은 사진이었다.
또한 사진이 많아 시간도 오래걸리고
세그멘테이션 네트워크는 깊은 모델 구조로 인해 매일 8만장의 데이터에는 부적합하였다.
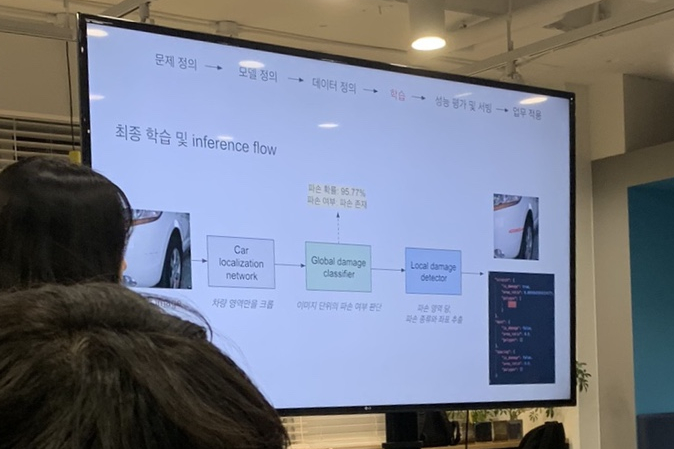 우선 데이터는 로컬라제이션을 이용하여 크롭하였다.
우선 데이터는 로컬라제이션을 이용하여 크롭하였다.
연산은 처음에 손상여부를 먼저 판별한 후 모델을 돌리게 되었다.
iou 0.967의 정확도로 유효한 성능을 보여주고 있었다.
질문
마지막으로 많은 질문들을 해주셨다.
게임회사에 근무하시는 분은 가격정책에 대한
ab테스트가 가능한 점에 대해 물어보았는데
게임의 경우 가격이 정해져있기때문에 어렵지만
주말요금과 시간별 요금이 나눠져있고 할인정책을 통한 유동성이 있기때문에
가능하다고 짚어주셨다.
마무리
2세션의 경우 쏘카 기술블로그에도 더욱 자세히 업로드해주신다고 하는데
언뜻 검색해보기로 쏘카 기술블로그가 어떤건지는 잘 못찾겠다..
강의를 재밌게 보고와서 정리도 깔끔하게 하고 싶었는데
좀더 다듬을 필요가 있을 것 같다.
- 지금은 쏘카 기술블로그에 더 자세히 올라와 있습니다.
Semantic Segmentation을 활용한 차량 파손 탐지 딥러닝 모델 개발기

SOCAR DATA Meet-Up 2022 세션을 보면서 쏘카의 최적화 모델링에 감탄하면서 검색하던 중에 좋은 포스팅 만나서 배우고 갑니다! 후기 공유해주셔서 감사합니다!! 개인적으로 경제학과 출신으로 수요공급 예측에 대한 현실적인 접근에 대해서 알 수 있어서 좋았습니다!