버블 정렬
💡 자료구조를 순회하면서 이웃한 요소들끼리 데이터를 교환하며 정렬을 수행한다.
버블 정렬의 성능
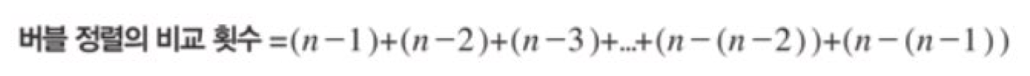
위의 식처럼 데이터가 30,000개나 되는 요소는 약 450,000,000회의 비교 연산을 거쳐야 한다.
def bubblesort(data):
for i in range(len(data) - 1):
for j in range(len(data) - i - 1):
if data[j] > data[j + 1]:
data[j], data[j + 1] = data[j + 1], data[j]삽입정렬
💡 자료구조를 순차적으로 순회하면서 순서에 어긋나는 요소를 찾고, 그 요소를 올바른 위치에 다시 삽입해나가는 정렬 알고리즘이다.
삽입 정렬의 성능

삽입 정렬은 자료구조가 정렬되어 있다면 한번도 비교를 거치지 않는다
- 비교를 거치지 않는 경우 (n-1)
- 역으로 정렬되어 있는 경우 최악 n(n-1) /2
두개의 평균이 (n^2 + n -2) / 2 회 정도
삽입 정렬시 30000개의 데이터 일때 평균 비교 횟수로 계산한다면 225,007,499회 이다.
def insertionSort(data):
for i in range(1, len(data)):
for j in range(i, 0, -1):
if data[j - 1] > data[j]:
data[j - 1], data[j] = data[j], data[j - 1]퀵 정렬
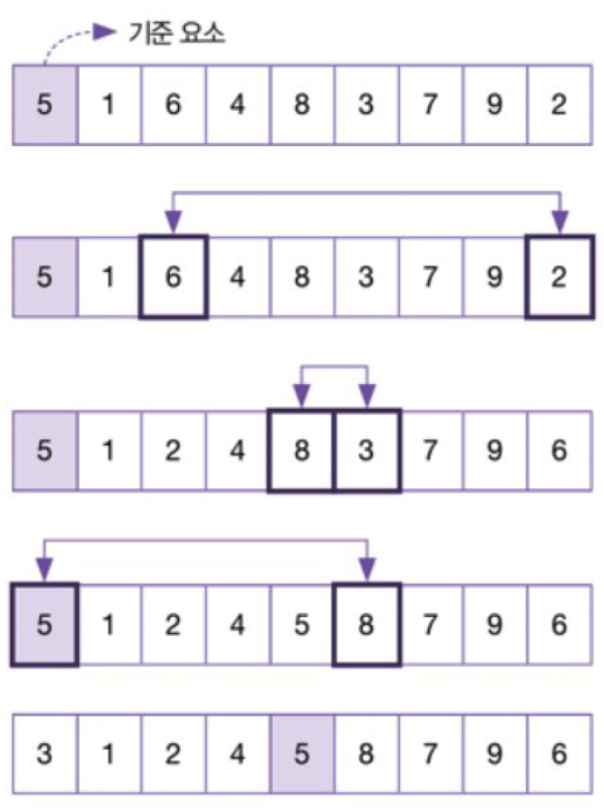
💡 동작 과정을 한마디로 요약하면 기준 요소 선정 및 분할의 반복
구체적인 과정
- 기준 요소 선정 및 정렬대상 분류
- 자료구조에서 기준이 될 요소를 임의로 선정하고 기준요소(Pivot) 의 값보다 작은 값을 가진 요소는 기준 요소의 왼쪽으로, 큰 값을 가지는 요소는 오른쪽으로 옮긴다
- 정렬대상 분할
- 기준 요소 왼쪽에는 기준 요소보다 작은 요소 그룹, 오른쪽에는 큰 요소의 그룹이 생긴다. 여기서 왼쪽 그룹과 오른쪽 그룹을 분할하여 각 그룹에 대해 1단계에 해당하는 과정을 수행
- 반복
- 그룹의 크기가 1 이하여서 더이상 분할할 수 없을 때 까지 1단계, 2단계 과정을 반복하면 정렬이 완료된다.
퀵 정렬 사용전 해결해야할 2가지 문제
- 배열을 사용할 경우 퀵 정렬의 분할 과정을 어떻게 효율적으로 처리할 것 인가?
-
링크드 리스트에서는 노드 삽입이 간단하지만 배열 요소 사이에서는 새로운 요소를 삽입하려면 다른 요소를 이동해야 하는데 큰 오버헤드 발생
-
- 반복되는 분할 과정을 어떻게 처리할 것인가?
- 재귀를 이용
def quick_sort(array, start, end):
if start >= end: # 원소가 1개인 경우 종료
return
pivot = start # 피벗은 첫 번째 원소
left = start + 1
right = end
while(left <= right):
# 피벗보다 큰 데이터를 찾을 때까지 반복
while(left <= end and array[left] <= array[pivot]):
left += 1
# 피벗보다 작은 데이터를 찾을 때까지 반복
while(right > start and array[right] >= array[pivot]):
right -= 1
if(left > right): # 엇갈렸다면 작은 데이터와 피벗을 교체
array[right], array[pivot] = array[pivot], array[right]
else: # 엇갈리지 않았다면 작은 데이터와 큰 데이터를 교체
array[left], array[right] = array[right], array[left]
# 분할 이후 왼쪽 부분과 오른쪽 부분에서 각각 정렬 수행
quick_sort(array, start, right - 1)
quick_sort(array, right + 1, end)
# 파이썬을 장점을 활용한 퀵정렬
def quickSort(array):
if len(array) <= 1:
return array
pivot = array[0]
tail = array[1:]
leftSide = [x for x in tail if x <= pivot]
rightSide = [x for x in tail if x > pivot]
return quickSort(leftSide) + [pivot] + quickSort(rightSide)퀵 정렬의 성능 측정
기준 요소 선정과 분할의 반복으로 동작한다.
- 데이터가 무작위로 배치된 경우에 최고 성능을 자랑함
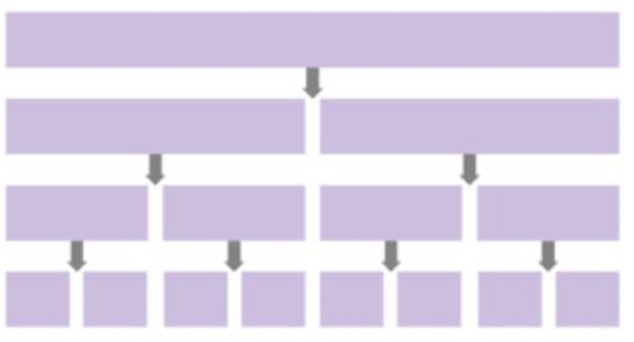
자료구조의 크기가 n일 때 퀵정렬의 재귀 호출의 깊이는 logN이다
재귀 호출의 깊이 * 각 재귀 호출 단계에서의 비교 횟수
N * logN = NlogN
30000개를 비교할 때 446180 번만에 비교를 수행해서 정렬이 된다.
-
최악의 경우
재귀 호출마다 자료 구조 분할이 1 : n-1 로 이루어 지는 것


💡 퀵 정렬은 평균적으로 1.39nlogn회 비교를 수행한다. 최선의 경우 보다 39퍼 정도 느린 성능인 수치

공부한것 정리하는 중입니다~