str.slice를 활용한 DataFrame 값 자르기
- 데이터 column값을 받았을 시 다음과 같이 숫자열 값이 str 형식으로 되어 있는경우가 있다.
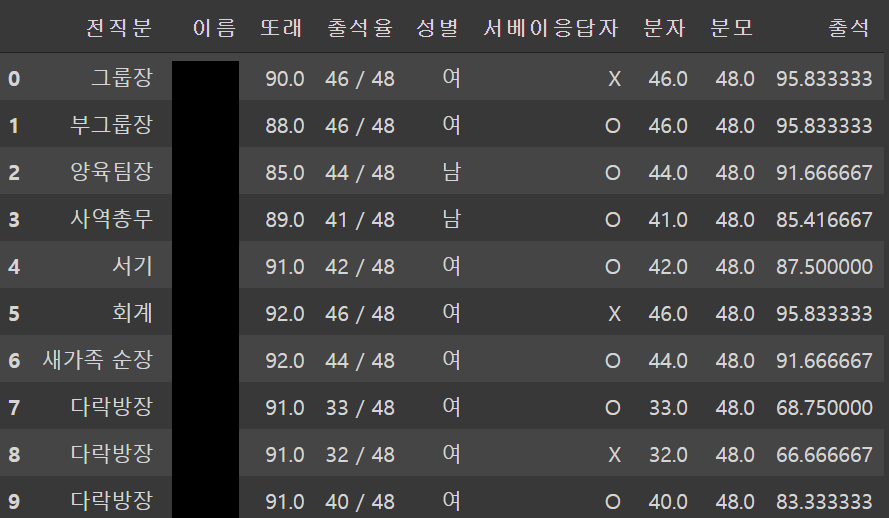
data.head(10)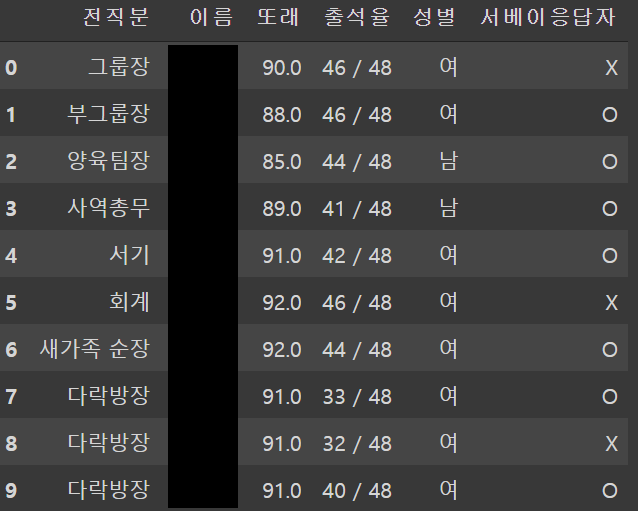
-
이와 같은 경우 column '출석율'의 분자 값과 분모 값을 가져와 숫자형으로 변환 후 값을 나누어 주어야 한다.
-
이 때 str.slice를 활용하여 분모와 분자 값을 가져온다.
data['분자'] = data['출석율'].str.slice(start=0, stop=2)
## 앞에 두 글자를 가져온다.
data['분모'] = data['출석율'].str.slice(start=-2)
## 뒤에서 부터 두 글자를 가져온다.
data.head()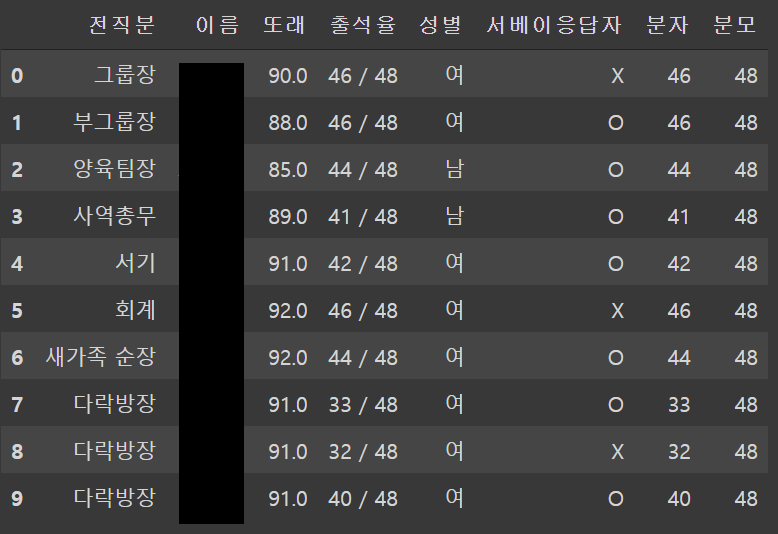
- 이 때 분모와 분자 값은 'object'형식으로 불러와 진다.
data.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 184 entries, 0 to 183
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 전직분 184 non-null object
1 이름 184 non-null object
2 또래 184 non-null float64
3 출석율 175 non-null object
4 성별 184 non-null object
5 서베이응답자 184 non-null object
6 분자 175 non-null object
7 분모 175 non-null object
dtypes: float64(1), object(7)
memory usage: 12.9+ KB- 이제 to_numeric 을 활용하여 숫자형으로 바꾸어 준다.
data['분모'] = pd.to_numeric(data['분모'])
data['분자'] = pd.to_numeric(data['분자'])
data.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 184 entries, 0 to 183
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 전직분 184 non-null object
1 이름 184 non-null object
2 또래 184 non-null float64
3 출석율 175 non-null object
4 성별 184 non-null object
5 서베이응답자 184 non-null object
6 분자 175 non-null float64
7 분모 175 non-null float64
dtypes: float64(3), object(5)
memory usage: 12.9+ KB- 마지막으로 출석율을 구한다.
data['출석'] = data['분자']/data['분모']*100
data.head()