
과정 1-2 진행 후
- 과정 1-2를 진행 후 public score를 확인해본 결과 5.4점대가 나왔다.
- 낮은 점수를 목표로 다른 모델링을 계속 진행 해보았지만 validation set을 두고 진행한 모델링의 결과는 testing set에서는 좋지 못하게 나왔다.
- 이번 페이지는 1-2과정 진행 후 추가적으로 진행된 feature engineering 과 모델링, 변수 선택법을 기록하였다.
1 Setting 추가 진행
-
16자리의 송하인과 수하인의 정보가 사용 가능하면 추가적으로 사용하고자 하였다.
Training set에서 16자리의 정보를 가지고 송하인과 수하인의 평균값을 구하여 feature로 사용시 MSE가 6점대가 나왔다.
그 전 MSE는 30점 대였다
1.2.1 Training Set
# After ML
train['Send16Digit'] = train['SEND_SPG_INNB']
train['Rec16Digit'] = train['REC_SPG_INNB']
# convert int to str
train['SEND_SPG_INNB'] = train['SEND_SPG_INNB'].apply(str)
train['REC_SPG_INNB'] = train['REC_SPG_INNB'].apply(str)
# slice the index numbers
train['SEND_SPG_INNB'] = train['SEND_SPG_INNB'].str.slice(start=0, stop=4)
train['REC_SPG_INNB'] = train['REC_SPG_INNB'].str.slice(start=0, stop=4)1.2.2 Testing Set
# After ML
test['Send16Digit'] = test['SEND_SPG_INNB']
test['Rec16Digit'] = test['REC_SPG_INNB']
# convert int to str
test['SEND_SPG_INNB'] = test['SEND_SPG_INNB'].apply(str)
test['REC_SPG_INNB'] = test['REC_SPG_INNB'].apply(str)
# slice the index numbers
test['SEND_SPG_INNB'] = test['SEND_SPG_INNB'].str.slice(start=0, stop=4)
test['REC_SPG_INNB'] = test['REC_SPG_INNB'].str.slice(start=0, stop=4)3 Feature Engineering
3.5 Send & Rec 16 Digit Avg.
# 각 16자리로 이루어진 수하인과 송하인에 대한 feature engineering 을 진행하였다.
# Send 16
Send16_count = train.groupby('Send16Digit').count()['INVC_CONT'].sort_values(ascending=False)
Send16_count_total = train.groupby('Send16Digit').sum()['INVC_CONT'].sort_values(ascending=False)
# Rec 16
Rec16_count = train.groupby('Rec16Digit').count()['INVC_CONT'].sort_values(ascending=False)
Rec16_count_total = train.groupby('Rec16Digit').sum()['INVC_CONT'].sort_values(ascending=False)# avg send
avg_send16 = Send16_count_total/Send16_count
avg_send16.rename('avg_send16', inplace=True)
avg_send16 = avg_send16.reset_index().rename(columns={'index': 'avg_send16'})
# avg rec
avg_rec16 = Rec16_count_total/Rec16_count
avg_rec16.rename('avg_rec16', inplace=True)
avg_rec16 = avg_rec16.reset_index().rename(columns={'index': 'avg_rec16'})# avg send
train = pd.merge(left=train, right=avg_send16,
how='left', on=['Send16Digit'])
test = pd.merge(left=test, right=avg_send16,
how='left', on=['Send16Digit'])
# avg rec
train = pd.merge(left=train, right=avg_rec16,
how='left', on=['Rec16Digit'])
test = pd.merge(left=test, right=avg_rec16,
how='left', on=['Rec16Digit'])- Training 과 Testing sets은 각각 다음과 같이 정렬되었다.
train.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 32000 entries, 0 to 31999
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 index 32000 non-null int64
1 SEND_SPG_INNB 32000 non-null object
2 REC_SPG_INNB 32000 non-null object
3 DL_GD_LCLS_NM 32000 non-null object
4 DL_GD_MCLS_NM 32000 non-null object
5 INVC_CONT 32000 non-null int64
6 Send16Digit 32000 non-null int64
7 Rec16Digit 32000 non-null int64
8 avg_send 32000 non-null float64
9 avg_rec 32000 non-null float64
10 avg_catb 32000 non-null float64
11 avg_catm 32000 non-null float64
12 avg_send16 32000 non-null float64
13 avg_rec16 32000 non-null float64
dtypes: float64(6), int64(4), object(4)
memory usage: 3.7+ MBtest.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 4640 entries, 0 to 4639
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 index 4640 non-null int64
1 SEND_SPG_INNB 4640 non-null object
2 REC_SPG_INNB 4640 non-null object
3 DL_GD_LCLS_NM 4640 non-null object
4 DL_GD_MCLS_NM 4640 non-null object
5 Send16Digit 4640 non-null int64
6 Rec16Digit 4640 non-null int64
7 avg_send 4637 non-null float64
8 avg_rec 4640 non-null float64
9 avg_catb 4640 non-null float64
10 avg_catm 4640 non-null float64
11 avg_send16 4327 non-null float64
12 avg_rec16 1025 non-null float64
dtypes: float64(6), int64(3), object(4)
memory usage: 507.5+ KB- training set의 값을 testing에 merge 시켰을시 avg_send에 3개의 Null 값이 발생한다.
Testing set 엔 Trainig set에 존재하지 않는 송하인의 격자 값이 존재한다.
Correlation Matrix
# Compute the correlation matrix
corr = train.drop(['index', 'Send16Digit', 'Rec16Digit'], axis=1).corr()
# Generate a mask for the upper triangle
mask = np.triu(np.ones_like(corr, dtype=bool))
# Set up the matplotlib figure
f, ax = plt.subplots(figsize=(11, 9))
# Generate a custom diverging colormap
cmap = sns.diverging_palette(230, 20, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0, annot=True,
square=True, linewidths=.5, cbar_kws={"shrink": .5})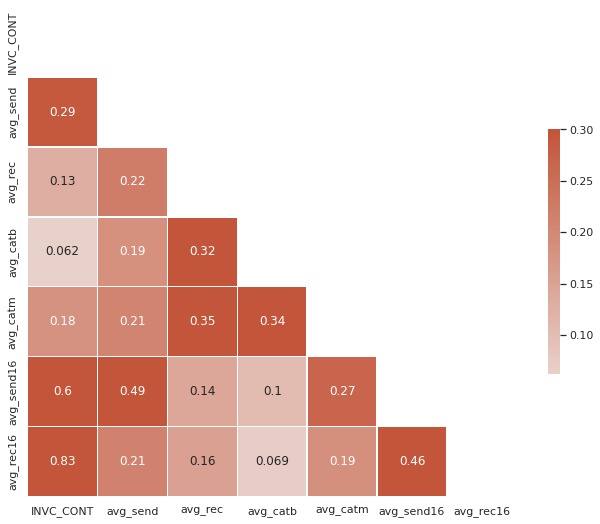
-
Testing Set에는 3개의 결측값을 가진 Training set에는 없는 송하인이 존재한다.
-
송하인의 경우 다른 변수들과의 관계도가(16자리의 송하인 정보를 제외하면) 0.2 정도로 거의 근접한 상관관계를 가지고 있다.
3개의 결측치에 대해 avg_rec, avg_catb, avg_catm의 평균 값으로 채워준다.
3.6 Impute Missing Values
# Before dropping categorical variables, let's copy training and testing sets.
# Because one-hot encoding is may required later.
train_copy = train.copy()
test_copy = test.copy()# Training
train = train.drop(['index', 'SEND_SPG_INNB', 'REC_SPG_INNB',
'DL_GD_LCLS_NM', 'DL_GD_MCLS_NM',
'Send16Digit', 'Rec16Digit'], axis=1)
# Testing
test = test.drop(['index', 'SEND_SPG_INNB', 'REC_SPG_INNB',
'DL_GD_LCLS_NM', 'DL_GD_MCLS_NM',
'Send16Digit', 'Rec16Digit'], axis=1)test.loc[1659].avg_send = test.drop(['avg_send16', 'avg_rec16'], axis=1).mean(axis=1).loc[1659]
test.loc[3760].avg_send = test.drop(['avg_send16', 'avg_rec16'], axis=1).mean(axis=1).loc[3760]
test.loc[4064].avg_send = test.drop(['avg_send16', 'avg_rec16'], axis=1).mean(axis=1).loc[4064]
test.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 4640 entries, 0 to 4639
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 avg_send 4640 non-null float64
1 avg_rec 4640 non-null float64
2 avg_catb 4640 non-null float64
3 avg_catm 4640 non-null float64
4 avg_send16 4327 non-null float64
5 avg_rec16 1025 non-null float64
dtypes: float64(6)
memory usage: 413.8 KB3.7 Testing Set Imputation
-
현재 Testing Set에서 'avg_send16', 'avg_rec16'의 경우에는 missing value가 많이 존재한다.
-
Training Set에 렌덤하게 Null 값을 생성(avg_send16 은 7%, ang_rec16은 90%)한 후 imputation 을 진행하여 결과값중 좋은 것을 Testing Set에 적용한다.
-
세가지의 imputation 방식을 진행한다.
0 Imputation
Simple Imputation(mean 혹은 median)
Iterative Imputation
-
train_test_split을 이용하여 데이터를 렌덤하게 나누고 결측값을 생성한다.
-
각 피처에서 imputation을 진행하고 결과 값에 따른 가장 좋은 imputation 을 선택한다.
하나의 피처에 대한 imputation을 진행할 시 다른 피처는 제외한다.
3.7.1 avg_send16 Imputation
# Training X and y no avg_rec16
X = train.drop(['INVC_CONT', 'avg_rec16'], axis=1)
y = train.INVC_CONT
# Split to nonNull and null X and y
from sklearn.model_selection import train_test_split
X_nonNull, X_null, y_nonNull, y_null = train_test_split(X, y, test_size=0.07, random_state=42)
# gneerate null value
X_null['avg_send16'] = np.nan
X_null.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 2240 entries, 23100 to 24374
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 avg_send 2240 non-null float64
1 avg_rec 2240 non-null float64
2 avg_catb 2240 non-null float64
3 avg_catm 2240 non-null float64
4 avg_send16 0 non-null float64
dtypes: float64(5)
memory usage: 105.0 KB0 Imputation
# impute nan to 0
X_null['avg_send16'] = 0
# generate X_zero
X_zero = pd.concat([X_nonNull, X_null])
X_zero = X_zero.sort_index(ascending=True)Mean and Median Imputation
# mean imputation
X_null['avg_send16'] = X_nonNull['avg_send16'].mean()
# generate X_mean
X_mean = pd.concat([X_nonNull, X_null])
X_mean = X_mean.sort_index(ascending=True)# median imputation
X_null['avg_send16'] = X_nonNull['avg_send16'].median()
# generate X_median
X_median = pd.concat([X_nonNull, X_null])
X_median = X_median.sort_index(ascending=True)Iterative imputation
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer# gneerate null value
X_null['avg_send16'] = np.nan
# generate X_mean
X_withNull = pd.concat([X_nonNull, X_null])
# Generate model and iter. imputation
iter = IterativeImputer()
imputed = iter.fit_transform(X_withNull)
X_iter = pd.DataFrame(imputed, columns=X.columns)
X_iter.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 32000 entries, 0 to 31999
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 avg_send 32000 non-null float64
1 avg_rec 32000 non-null float64
2 avg_catb 32000 non-null float64
3 avg_catm 32000 non-null float64
4 avg_send16 32000 non-null float64
dtypes: float64(5)
memory usage: 1.2 MB------Verify the Result Via K-Folds------
!pip install catboost# K-folds
from sklearn.model_selection import KFold
# Models
from sklearn.linear_model import LinearRegression
from lightgbm import LGBMRegressor
from xgboost import XGBRegressor
from catboost import CatBoostRegressor
# MSE & Other Evaluation Score
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import r2_score# Define a print Function
def print_function(scores):
score1, score2 = scores # unpacking
# print("------ MAE ------")
# print("Train loss : %.4f" % score1)
# print("Validation loss : %.4f" % score2)
print()
print("------ MSE ------")
print("Train loss : %.4f" % score1)
print("Validation loss : %.4f" % score2)
print()
# print("------ R2 ------")
# print("Train R2 score : %.4f" % score5)
# print("Validation R2 score : %.4f" % score6)
print()
# Calculating Scores by each model
def train_and_validation(train_data, validation_data, model, metrics, print_mode):
#
X_train, y_train = train_data
X_val, y_val = validation_data
model.fit(X_train, y_train)
train_pred = model.predict(X_train)
val_pred = model.predict(X_val)
score1 = metrics[0](y_train, train_pred)
score2 = metrics[0](y_val, val_pred)
# score3 = metrics[1](y_train, train_pred)
# score4 = metrics[1](y_val, val_pred)
# score5 = metrics[2](y_train, train_pred)
# score6 = metrics[2](y_val, val_pred)
scores = [score1, score2]
# if print_mode:
# print_function(scores)
return np.array(scores)# Choose K
K = 5
# K-folds
kfcv = KFold(n_splits=K, shuffle=True, random_state=42)
# evalution
evalution = [mean_squared_error]
# models
lr = LinearRegression(normalize=True)
lgbm = LGBMRegressor()
catb = CatBoostRegressor(silent=True)
xgbm = XGBRegressor(silent=True)
models = [lr, lgbm, catb, xgbm]
print_mode = Trueimport warnings
warnings.filterwarnings("ignore")
for index, model in enumerate(models):
if print_mode:
print(f"\n====== Model {model} ======\n")
# generate a blank fold
folds = []
# model's scores
model_scores = []
X = X_iter
# Generate K-fold
for train_index, val_index in kfcv.split(X, y):
folds.append((train_index, val_index))
# fold 별 학습 및 검증
for i in range(K):
# if print_mode:
# print(f"{i+1}th folds in {K} folds.")
train_index, val_index = folds[i]
X_train = X.iloc[train_index, :]
X_val = X.iloc[val_index, :]
y_train = y[train_index]
y_val = y[val_index]
# 모델별 score 산축
scores = train_and_validation((X_train, y_train), (X_val, y_val), model, evalution, print_mode)
model_scores.append(scores)
# mean of scores
model_scores = np.array(model_scores)
if print_mode:
print("Average Score in %dfolds." % K)
print_function(model_scores.mean(axis=0))
print("Done.")# 각 imputation 에 따른 결과
modScores = ['lr_t_mse', 'lr_v_mse', 'lgbm_t_mse', 'lgbm_v_mse',
'ctbm_t_mse', 'ctbm_v_mse', 'xgbm_t_mse', 'xgbm_v_mse']
scores = {'zeroImp' : [23.4618, 24.5876, 19.8108, 25.1204,
16.9222, 25.9413, 19.7111, 24.7775],
'meanImp' : [22.4679, 22.6211, 19.7900, 24.9102,
16.9220, 25.9780, 20.0422, 24.9485],
'medianLmp' : [22.5024, 22.6750, 19.8575, 24.9565,
16.9136, 26.0700, 19.9950, 24.9890],
'iterImp' : [33.0826, 33.0958, 30.6495, 33.7987,
26.9254, 31.1648, 31.8672, 33.3074]
}
KScores = pd.DataFrame(scores, index=modScores)
KScores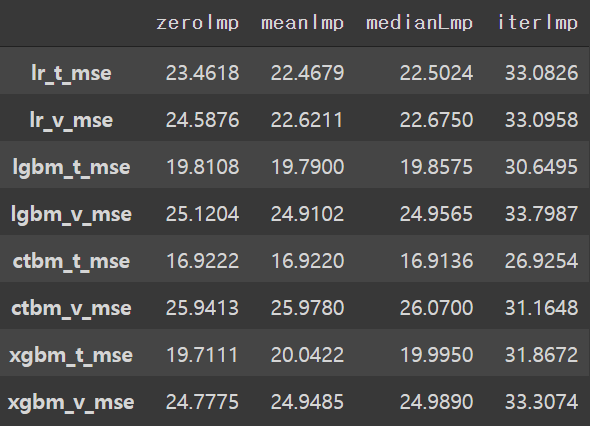
- 'avg_send16'의 경우 mean imputation 이 가장 좋은 점수를 보였다.
3.7.2 avg_rec16
# Training X and y no avg_send16
X = train.drop(['INVC_CONT', 'avg_send16'], axis=1)
y = train.INVC_CONT
# Split to nonNull and null X and y
X_nonNull, X_null, y_nonNull, y_null = train_test_split(X, y, test_size=0.9, random_state=42)
# gneerate null value
X_null['avg_rec16'] = np.nan
X_null.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 28800 entries, 23100 to 9074
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 avg_send 28800 non-null float64
1 avg_rec 28800 non-null float64
2 avg_catb 28800 non-null float64
3 avg_catm 28800 non-null float64
4 avg_rec16 0 non-null float64
dtypes: float64(5)
memory usage: 1.3 MB0 Imputation
# impute nan to 0
X_null['avg_rec16'] = 0
# generate X_zero
X_zero = pd.concat([X_nonNull, X_null])
X_zero = X_zero.sort_index(ascending=True)Mean and Median Imputation
# mean imputation
X_null['avg_rec16'] = X_nonNull['avg_rec16'].mean()
# generate X_mean
X_mean = pd.concat([X_nonNull, X_null])
X_mean = X_mean.sort_index(ascending=True)# median imputation
X_null['avg_rec16'] = X_nonNull['avg_rec16'].median()
# generate X_median
X_median = pd.concat([X_nonNull, X_null])
X_median = X_median.sort_index(ascending=True)Iterative imputation
# gneerate null value
X_null['avg_rec16'] = np.nan
# generate X_mean
X_withNull = pd.concat([X_nonNull, X_null])# Generate model and iter. imputation
iter = IterativeImputer()
imputed = iter.fit_transform(X_withNull)
X_iter = pd.DataFrame(imputed, columns=X.columns)------Verify the Result Via K-Folds------
for index, model in enumerate(models):
if print_mode:
print(f"\n====== Model {model} ======\n")
# generate a blank fold
folds = []
# model's scores
model_scores = []
X = X_iter
# Generate K-fold
for train_index, val_index in kfcv.split(X, y):
folds.append((train_index, val_index))
# fold 별 학습 및 검증
for i in range(K):
# if print_mode:
# print(f"{i+1}th folds in {K} folds.")
train_index, val_index = folds[i]
X_train = X.iloc[train_index, :]
X_val = X.iloc[val_index, :]
y_train = y[train_index]
y_val = y[val_index]
# 모델별 score 산축
scores = train_and_validation((X_train, y_train), (X_val, y_val), model, evalution, print_mode)
model_scores.append(scores)
# mean of scores
model_scores = np.array(model_scores)
if print_mode:
print("Average Score in %dfolds." % K)
print_function(model_scores.mean(axis=0))
print("Done.")# 각 imputation에 따른 결과
modScores = ['lr_t_mse', 'lr_v_mse', 'lgbm_t_mse', 'lgbm_v_mse',
'ctbm_t_mse', 'ctbm_v_mse', 'xgbm_t_mse', 'xgbm_v_mse']
scores = {'zeroImp' : [29.2190, 29.8111, 24.9669, 28.8530,
22.2650, 28.8333, 24.6760, 28.3247],
'meanImp' : [28.6004, 29.4077, 25.0638, 28.8436,
22.3123, 28.7967, 24.7153, 28.3432],
'medianLmp' : [28.7661, 29.7996, 25.1762, 28.8644,
22.3940, 28.7909, 24.7945, 28.3670],
'iterImp' : [33.0814, 33.0923, 31.4553, 33.8238,
29.6598, 35.7881, 32.0422, 33.6408]
}
KScores = pd.DataFrame(scores, index=modScores)
KScores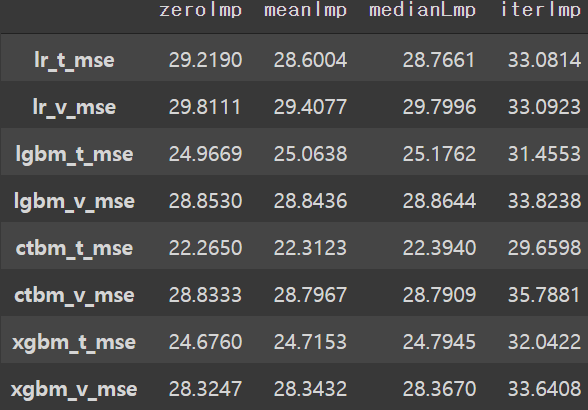
- 'avg_rec16'의 경우 mean imputation 이 가장 좋은 점수를 보였다.
- Testing set의 두 변수 'avg_send16'과 'avg_rec16'에 mean imputation을 진행한다.
4 After Feature Engineering
4.2 Spliting the data sets to X and y
- 아래의 코드를 실행하면 training set의 avg_send16과 avg_rec16의 imputed된 feature가 포함된 X_train 과 X_val sets이 생성된다.
# Training X and y
X_send = train.drop(['INVC_CONT', 'avg_rec16'], axis=1)
X_rec = train.drop(['INVC_CONT', 'avg_send16'], axis=1)
# Split to nonNull and null X and y
X_sendNonNull, X_sendNull, y_nonNull, y_null = train_test_split(X_send, y, test_size=0.07, random_state=42)
X_recNonNull, X_recNull, y_nonNull, y_null = train_test_split(X_rec, y, test_size=0.9, random_state=42)
# mean imputation
X_sendNull['avg_send16'] = X_sendNonNull['avg_send16'].mean()
X_recNull['avg_rec16'] = X_recNonNull['avg_rec16'].mean()
# concat
## send
X_send = pd.concat([X_sendNonNull, X_sendNull])
X_send = X_send.sort_index(ascending=True)
## rec
X_rec = pd.concat([X_recNonNull, X_recNull])
X_rec = X_rec.sort_index(ascending=True)
X_rec = X_rec.avg_rec16
# merge
X = pd.merge(X_send, X_rec, left_index=True, right_index=True)
# X_test
test.fillna(test.mean(), inplace=True)
X_test = test-------Optional Steps-------
4.3 Drop avg_catb
- avg_catb의 경우 제거 하였을 시 성능이 올라가는 것이 보였다
# Training X and y
X = X.drop(['avg_catb'], axis=1)
y = train.INVC_CONT
# Testing X
X_test = X_test.drop(['avg_catb'], axis=1)4.4 Generate Additional Variables
- 추가적인 variables을 만드는 코드로 상황에 맞게 사용하면 된다.
- 사용하였을 시 validation set에서는 성능이 좋았으나 testing set에서는 성능이 좋지 못하게 나왔다.
# Copy X
X_copy = X.copy()
X_test_copy = X_test.copy()# Generate additional Features
## Sqrt of Summation and Mean
X['mean'] = X_copy.mean(axis=1)
X['sum'] = X_copy.sum(axis=1)**(0.5)
X_test['mean'] = X_test_copy.mean(axis=1)
X_test['sum'] = X_test_copy.sum(axis=1)**(0.5)
del X_copy
del X_test_copy4.5 One-hot encoding
4.5.1 CATB One-Hot
trainCopy = pd.get_dummies(data=train_copy, columns=['DL_GD_LCLS_NM'], prefix='class')
testCopy = pd.get_dummies(data=test_copy, columns=['DL_GD_LCLS_NM'], prefix='class')X = trainCopy.drop(['index', 'INVC_CONT', 'SEND_SPG_INNB', 'REC_SPG_INNB', 'DL_GD_MCLS_NM'], axis=1)
y = trainCopy.INVC_CONT
X_test = testCopy.drop(['index', 'SEND_SPG_INNB', 'REC_SPG_INNB', 'DL_GD_MCLS_NM'], axis=1)4.5.2 CATM One-Hot
trainCopy = pd.get_dummies(data=train_copy, columns=['DL_GD_MCLS_NM'], prefix='class')
testCopy = pd.get_dummies(data=test_copy, columns=['DL_GD_MCLS_NM'], prefix='class')X = trainCopy.drop(['index', 'INVC_CONT', 'SEND_SPG_INNB', 'REC_SPG_INNB', 'DL_GD_LCLS_NM'], axis=1)
y = trainCopy.INVC_CONT
X_test = testCopy.drop(['index', 'SEND_SPG_INNB', 'REC_SPG_INNB', 'DL_GD_LCLS_NM'], axis=1)4.5.2 CATB & CATM One-Hot
trainCopy = pd.get_dummies(data=train_copy, columns=['DL_GD_LCLS_NM', 'DL_GD_MCLS_NM'], prefix='class')
testCopy = pd.get_dummies(data=test_copy, columns=['DL_GD_LCLS_NM', 'DL_GD_MCLS_NM'], prefix='class')X = trainCopy.drop(['index', 'INVC_CONT', 'SEND_SPG_INNB', 'REC_SPG_INNB'], axis=1)
y = trainCopy.INVC_CONT
X_test = testCopy.drop(['index', 'SEND_SPG_INNB', 'REC_SPG_INNB'], axis=1)-------After Optional Step-------
4.6 K-Folds Cross Validation
import warnings
warnings.filterwarnings("ignore")
for index, model in enumerate(models):
if print_mode:
print(f"\n====== Model {model} ======\n")
# generate a blank fold
folds = []
# model's scores
model_scores = []
# Generate K-fold
for train_index, val_index in kfcv.split(X, y):
folds.append((train_index, val_index))
# fold 별 학습 및 검증
for i in range(K):
# if print_mode:
# print(f"{i+1}th folds in {K} folds.")
train_index, val_index = folds[i]
X_train = X.iloc[train_index, :]
X_val = X.iloc[val_index, :]
y_train = y[train_index]
y_val = y[val_index]
# 모델별 score 산축
scores = train_and_validation((X_train, y_train), (X_val, y_val), model, evalution, print_mode)
model_scores.append(scores)
# mean of scores
model_scores = np.array(model_scores)
if print_mode:
print("Average Score in %dfolds." % K)
print_function(model_scores.mean(axis=0))
print("Done.")modScores = ['lr_t_mse', 'lr_v_mse', 'lgbm_t_mse', 'lgbm_v_mse',
'ctbm_t_mse', 'ctbm_v_mse', 'xgbm_t_mse', 'xgbm_v_mse']
scores = {'4avg' : [29.0463, 29.1624, 25.8423, 28.4882,
23.6648, 28.3890, 26.0585, 27.655],
'noCatb' : [29.1065, 29.2209, 25.8894, 28.4734,
23.7575, 28.4065, 26.0850,27.6701],
'4avg2Add' : [28.8746, 29.0545, 25.6641, 28.4708,
23.5021, 28.4714, 25.6181, 27.603],
'4avg2AddNoCatb' : [28.8670, 29.0507, 25.6690, 28.5568,
23.5241, 28.4608, 25.6844, 27.6810],
'3avg2Add' : [28.9402, 29.1025, 25.6929, 28.4959,
23.6522, 28.3895, 25.7407, 27.8136],
'catbOneHot' : [29.0131, 29.1467, 25.8523, 28.4960,
23.6731, 28.3825, 26.0693, 27.6961],
'catmOneHot' : [28.9364, 29.1363, 25.7635, 28.4877,
23.4449, 28.3509, 25.8832, 27.7929],
'oneHots' : [28.9378, 29.1365, 25.7656, 28.5040,
23.4456, 28.3389, 25.9038, 27.8004]
}
KScores = pd.DataFrame(scores, index=modScores)
KScores
-
트리 모델의 경우 XG Boost가 MSE를 기준으로 가장 괜찮은 성능을 보여주었다.
-
그러나 testing set에 있어서는 lgbm의 성능이 가장 좋았다.
-
또한 Optuna 를 활용하여 확인한 결과 Training에 avg_send16과 avg_rec16을 포함하여 MSE 값을 확인한 경우 2 점대가 나왔다.
따라서 avg_rec16값이 있는 testing set의 경우에는 training set에 avg_send16과 avg_rec16를 포함하여 예측을 한다.
avg_rec16값이 없는 testing set에 대해서는 네개의 평균과 두개의 additional variable이 있는 training set으로 예측을 한다.
