TCP/IP 소켓 프로그래밍
1. 소켓(Socket)
소켓(Socket)은 사전적으로 "구멍", "연결", "콘센트" 등의 의미를 갖는다. 네트워크 프로그래밍에서의 관점에서의 소켓은 프로그램이 네트워크에서 데이터를 송수신할 수 있도록 네트워크 환경에 연결할 수 있게 만들어진 연결부를 의미한다. 전기 소켓이 전기를 공급받기 위해 정해진 규격(110V, 220V 등)에 맞게 만들어져야 하듯, 네트워크에 연결하기 위한 소켓 역시 정해진 규약, 즉 통신을 위한 프로토콜에 맞게 만들어져야 한다. 보통 OSI 7계층의 4번째 계층인 TCP상에서 동작하는 소켓을 주로 사용하는데 이를 TCP 소켓 또는 TCP/IP 소켓이라고 부른다. 마찬가지로 UDP에서 동작하는 소켓은 UDP 소켓이라고 부른다.
2. TCP/IP 소켓 프로그래밍
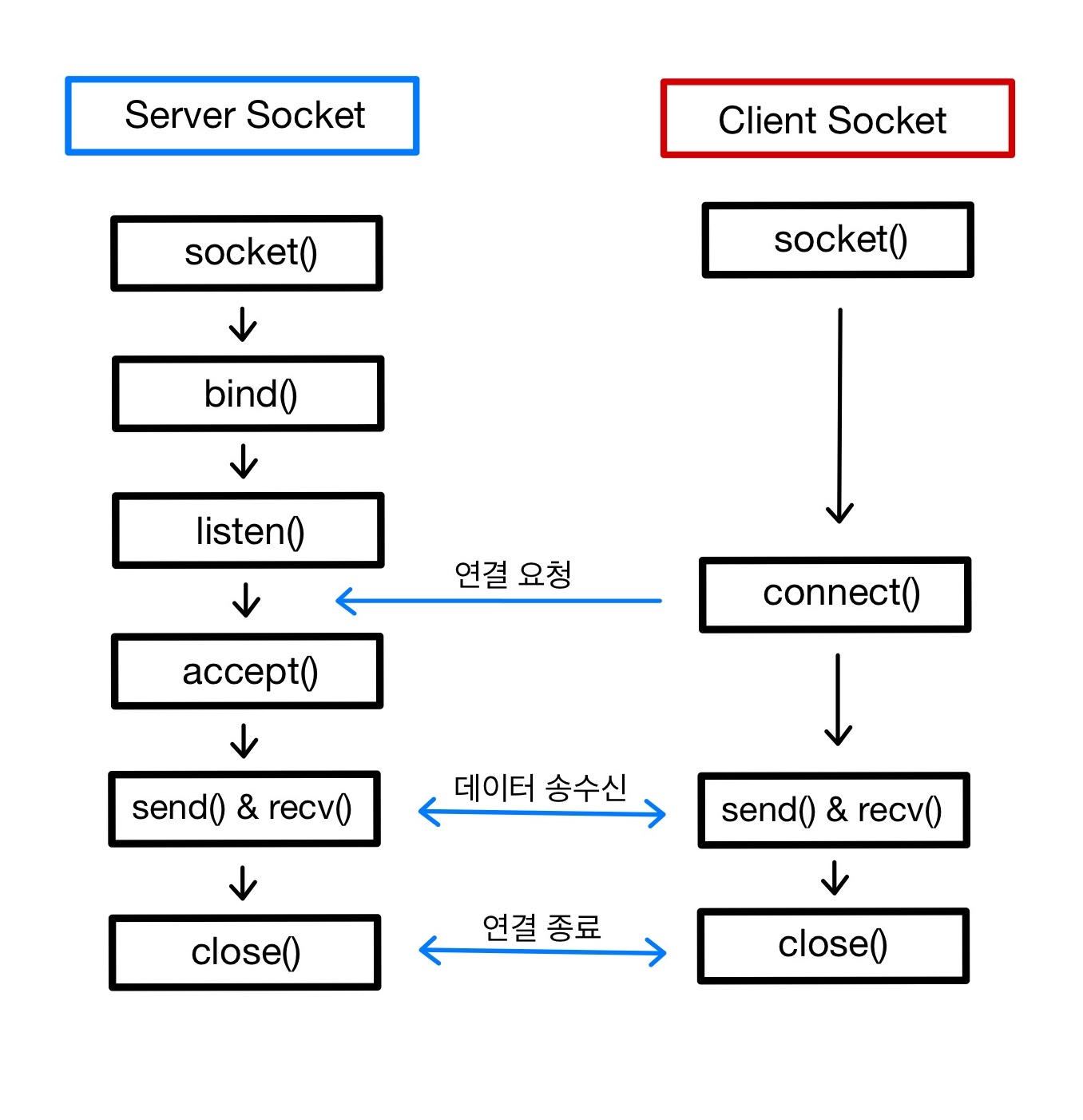
소켓 프로그래밍 방법을 이해하기 위해서는 먼저 클라이언트 소켓과 서버 소켓의 역할에 대해 알고있어야 한다. 데이터를 주고받기 위해서는 소켓의 연결 과정이 선행되어야 하고, 그 과정에서의 연결 요청과 수신이 각각 클라이언트 소켓과 서버 소켓의 역할이기 때문이다.
두 개의 시스템(또는 프로세스)이 소켓을 통해 네트워크 연결을 만들기 위해서는, 클라이언트 소켓이 IP 주소와 포트 번호를 통해 서버 소켓에게 연결을 시도하고, 서버 소켓은 어떤 연결 요청(포트 번호로 식별)을 받아들일지 미리 시스템에 등록하여 요청이 수신되었을 때 해당 요청을 처리한다.
클라이언트 소켓과 서버 소켓은 역할과 구현 절차 구분을 위해 다르게 부르는 것일 뿐 내부 구조가 다르지 않은 동일한 형태의 소켓이다.
소켓 연결이 완료된 후, 클라이언트 소켓과 서버 소켓이 직접 데이터를 주고 받는다고 생각하기 쉽지만 사실 서버 소켓은 클라이언트 소켓의 연결 요청을 받아들이는 역할만 수행할 뿐이다. 직접적인 데이터 송수신은 서버 소켓의 연결 요청 수락 결과로 만들어지는 새로운 소켓을 통해 처리된다.
다음은 소켓 API 실행 흐름을 한눈에 보여준다.
3. 클라이언트 소켓 프로그래밍
3-1. 클라이언트 소켓 생성 ( socket() )
소켓 통신을 하기 위해서는 먼저 소켓을 생성해야 한다. 생성 시 소켓의 종류를 지정할 수 있는데, TCP 소켓을 위해서는 스트림(Stream) 타입, UDP 소켓을 위해서는 데이터그램(Datagram) 타입을 지정할 수 있다.
최초 소켓이 만들어지는 시점에는 연결 대상에 대한 어떠한 정보도 들어있지 않다. 따라서 연결 대상(IP:Port)을 지정하고 연결 요청을 전달하기 위해서는 connect() API를 호출해야 한다.
3-2. 연결 요청 ( connect() )
connect() API는 IP주소와 포트 번호로 식별되는 대상으롤 연결 요청을 보낸다. connect() API는 블록(Block) 방식으로 동작하기 때문에 연결 요청에 대한 결과가 결정되기 전에는 connect()의 실행이 끝나지 않는다. connect() API 호출이 성공하면 send() / recv() API를 통해 데이터를 주고 받을 수 있다.
3-3. 데이터 송수신 ( send() / recv() )
연결된 소켓을 통해 데이터를 보낼 때는 send(), 데이터를 받을 때는 recv() API를 사용한다. send()와 recv() API 역시 블록(Block) 방식으로 동작하기 때문에 두 API 모두 실행 결과가 결정되기 전까지는 API가 리턴되지 않는다.
send()의 경우 데이터를 보내는 주체가 자기 자신이기 때문에 얼마만큼의 데이터를 보낼 것인지를 알 수 있다. 하지만 데이터를 수신하는 경우 통신 대상이 언제, 어떤 데이터를 보낼 것인지를 특정할 수 없기 때문에 recv() API가 한번 실행되면 언제 끝날지 모르는 상태가 된다. 따라서 데이터 수신을 위한 recv() API는 별도의 스레드에서 실행한다. 소켓의 생성과 연결이 완료된 후, 새로운 스레드를 하나 만든 다음 그곳에서 recv()를 실행하고 데이터를 수신되길 기다리는 것이다.
3-4. 소켓 닫기 ( close() )
send() / recv() API를 통해 데이터 송수신이 완료되고 더 이상 송수신이 필요없게되면 close() API를 통해 소켓을 닫는다. 소켓 연결이 종료된 후 다시 데이터를 주고 받고싶다면 또 한번의 소켓 생성과 연결 과정을 통해 소켓 데이터를 송수신할 수 있는 상태가 되어야 한다.
4. 서버 소켓 프로그래밍
4-1. 서버 소켓 생성 ( socket() )
클라이언트 소켓과 마찬가지로 서버 소켓을 사용하려면 최초에 소켓을 생성해야한다.
4-2. 서버 소켓 바인딩 ( bind() )
bind() API에 사용되는 인자는 소켓과 포트 번호(또는 IP 주소 + 포트 번호)이다. bind()는 소켓과 포트 번호를 결합하는 것이다.
시스템에는 수 많은 프로세스가 있는데, 그 중 네트워크 관련 프로세스가 TCP 또는 UDP 프로토콜을 사용한다면 각 소켓은 시스템이 관리하는 포트(0 ~ 65535) 중 하나의 포트 번호를 사용하게 된다. 여기서 서로 다른 소켓이 같은 포트 번호를 중복으로 사용하는 일이 생길 수 있기 때문에 운영체제는 내부적으로 포트 번호와 소켓 연결 정보를 관리한다. 그리고 bind() API는 해당 소켓이 지정된 포트 번호를 사용할 것이라는 것을 운영체제에 요청하는 역할을 한다. 만약 지정된 포트 번호를 다른 소켓이 사용하고 있다면 bind() API는 에러를 리턴한다.
서버 소켓은 고정된 포트 번호를 사용하고 그 포트 번호로 클라이언트의 연결 요청을 받아들인다. 그래서 운영체제가 특정 포트 번호를 서버 소켓이 사용하도록 만들기 위해 소켓과 포트 번호를 결합(bind)해야 하는데 이 때 사용하는 API가 바로 bind()인 것이다.
4-3. 클라이언트 연결 요청 대기 ( listen() )
서버 소켓에 포트 번호를 결합(bind)하고 나면, 서버 소켓을 통해 클라이언트의 연결 요청 수신을 기다리게 되는데 이 역할을 listen() API가 수행한다.
listen() API는 서버 소켓에 바인딩된 포트 번호로 클라이언트의 연결 요청이 있는지 확인하며 대기 상태에 머무른다. 클라이언트에서 호출된 connect() API에 의해 연결 요청이 수신되면 대기 상태를 종료하고 리턴한다.
listen() API가 대기 상태에서 빠져나오는 경우는 두 가지이다. 클라이언트 요청이 수신되는 경우와 에러가 발생(소켓 close() 포함)하는 경우다. 그런데 listen() API가 성공하더라도 리턴 값에는 요청이 수신되었는지, 실패해서 에러가 발생했는지에 대한 정보만 있고, 요청에 대한 정보는 들어있지 않다.
대신 클라이언트 연결 요청에 대한 정보는 시스템 내부적으로 관리되는 큐(Queue)에 쌓이게 되는데, 이 시점에서 클라이언트와의 연결은 아직 완전히 연결되지 않은 대기 상태이다. 대기 중인 연결 요청을 큐(Queue)로부터 꺼내와서 연결을 완료하기 위해서는 accept() API를 호출해야 한다.
4-4. 클라이언트 연결 수립 ( accept() )
listen() API가 클라이언트의 연결 요청을 확인하고 성공했음을 리턴했어도, 최종 연결 요청을 받아들이는 역할을 수행하는 API는 accept()이다.
accept() API는 연결 요청을 받아들여 소켓 간 연결을 수립하는데, 이 때 데이터 통신을 위해 연결되는 소켓은 bind(), listen() API에서 사용한 소켓이 아니라 accept() API 내부에서 새로 만들어진 소켓이다. 이 새로 만들어진 소켓과, 포트 번호를 바인딩하고 클라이언트의 요청을 대기하기 위해 생성된 요청 대기 큐(Queue)에 쌓여있는 첫 번째 연결 요청이 매핑된다. 여기까지가 하나의 연결 요청을 처리하기 위한 서버 소켓의 역할이다. 서버 소켓의 남은 일은 또 다른 연결 요청을 처리하기 위해 다시 대기(listen)하거나, 서버 소켓을 닫는(close) 것 뿐이다.
4-5. 데이터 송수신 ( send() / recv() )
데이터를 송수신하는 과정은 클라이언트 소켓의 데이터 송수신 과정(3-3)과 동일하다.
4-6. 소켓 연결 종료 ( close() )
클라이언트 소켓 처리 과정과 마찬가지로 소켓을 닫기 위해서는 close() API를 호출하면 된다.
다만 서버 소켓에서는 close()의 대상이 최초 socket() API를 통해 생성한 소켓뿐만 아니라, accept() API를 통해 생성한 소켓도 있음을 유의해야 한다.
5. 다중 클라이언트 처리
기본 서버-클라이언트 모델에서 서버는 한 번에 하나의 클라이언트만 처리한다. 따라서 다중 클라이언트를 처리하려면 멀티 프로세싱, 멀티 스레딩, 멀티 플렉싱 등을 활용해야 한다.
5-1. 멀티 프로세싱
프로세스는 실행 중인 프로그램이라는 뜻으로 각각 독립된 메모리 영역(Code, Data, Stack, Heap)을 할당받는다. 기본적으로 프로세스 당 최소 1개의 스레드를 가지고 있으며, 각 프로세스는 별도의 주소 공간에서 실행되고, 한 프로세스는 다른 프로세스의 변수나 자료구조에 접근할 수 없다. 한 프로세스가 다른 프로세스의 자원에 접근하려면 프로세스 간의 통신(IPC, inter-process-communication)을 사용해야 한다.
멀티 프로세싱은 프로세스를 여러 개 사용하여 여러 개의 클라언트를 처리하는 것이다. 기본적으로 하나의 프로세스는 하나의 클라이언트를 처리한다. fork()를 이용하면 멀티 프로세스를 만들 수 있고, 부모 프로세스 1개에 N개의 자식 프로세스를 만들 수 있으며, 부모 프로세스와 자식 프로세스는 독립 프로세스로 각각 실행된다.
독립된 구조이기 때문에 안정성이 높고, 클라이언트와 서버 간의 송수신 데이터 용량이 큰 경우나, 송수신이 쉬지 않고 연속적으로 발생하는 경우에 적합하다는 장점이 있다.
반면 프로세스가 많이 생성될수록 메모리 사용량이 증가하고 프로세스 스케줄링 횟수도 많아져 프로그램 성능이 떨어진다. 또한 프로세스들 사이에 데이터를 공유할 수 없다는 단점이 있다. (IPC를 통해 프로세스 간 데이터를 공유 할 순 있지만 프로그램 구현이 복잡해짐)
5-2. 멀티 스레딩
여러 클라이언트를 처리하기 위한 더 간단한 방법은 멀티 스레딩을 활용하는 것이다. 서버에 연결된 모든 클라이언트에 대해 새 스레드를 생성하는 것이다. 스레드는 프로세스보다 작은 단위로, 프로세스 안에서 논리적으로 동작하는 하나의 작업 단위이다. 다수의 스레드를 가지고 있는 프로세스를 멀티 스레드 프로세스라고 한다. 외부에서는 스레드들 전체가 하나의 프로세스처럼 취급된다.
스레드는 Stack 영역을 제외한 모든 메모리를 공유하기 때문에 시스템 자원 소모가 적고, 스레드 간 통신은 IPC보다 훨씬 간단하다. 또한 멀티 프로세싱보다는 context switching에 대한 오버헤드가 적다는 장점이 있다.
반면 스레드는 코딩, 디버깅이 어렵고 때로는 예측할 수 없는 결과가 발생한다. 여러 개의 스레드를 이용하는 경우, 미묘한 시간차나 잘못된 변수를 공유함으로써 오류가 발생할 수도 있다. 또한 많은 수의 클라이언트에 대해 확장이 제한적이고 교착상태가 발생할 가능성도 있다. 그리고 서버에 접속한 각 클라이언트 별로 send() 스레드를 할당할 경우, 데이터가 오지 않으면 계속 블로킹 상태가 되기 때문에 자원이 낭비된다는 단점도 있다.
5-3. 멀티 플렉싱
멀티 플렉싱이란 하나의 전송로를 여러 사용자가 동시에 사용해서 효율성을 극대화하는 것이다. 그 중에서도 I/O 멀티 플렉싱이란 클라이언트와 입/출력하는 프로세스를 하나로 묶어버리는 것이다. 하나의 스레드를 이용하여 여러 클라이언트와 동시에 메시지를 주고받을 수 있는 것이다.
서버에서 여러 명의 클라이언트와 동시에 메시지를 주고받기 위한 멀티 스레드는 각 스레드 당 CPU의 스택을 필요로 하기 때문에 서버의 성능이 저하될 수 있다. 이러한 단점을 보완하기 위해 하나의 스레드만 생성하여 여러 클라이언트와 통신할 수 있는 I/O 멀티 플렉싱이 등장하였다.
멀티 플렉싱은 설계 시 코드가 복잡하다. 논블로킹을 위해 핸들러를 만들어야 하며, 콜백 개념도 이해해야한다. 하나의 스레드에 작업량이 많아지는 것을 고려해 Thread Pool을 만들어 Task들을 분산처리도 해야한다. 하지만 이러한 작업을 쉽게 처리할 수 있는 함수가 있다. (select() 등)
장점도 있다. 스레드 하나가 여러 개의 클라이언트를 관리할 수 있어서 굉장히 효율적이다. 멀티 플렉싱은 클라이언트와 서버 간 송수신 데이터의 용량이 적은 경우나, 송수신이 연속적이지 않은 경우, 멀티 프로세스에 비해 많은 수의 클라이언트 처리해야하는 경우에 적합하다.
정리하자면,
멀티 프로세싱 → 여러 개의 프로세스
멀티 스레딩 → 하나의 프로세스 & 여러 개의 스레드
멀티 플렉싱 → 하나의 프로세스 & 하나의 스레드
Reference
