
CUBRID SQL
1. 테이블 정의문
CREATE TABLE
-
테이블을 생성한다.
-
테이블 칼럼의 초기값을 SHARED 또는 DEFAULT 값을 통해 정의할 수 있다. (ALTER TABLE 문에서 변경 가능)
- SHARED : 칼럼 값은 모든 행에서 동일하다. 따라서 SHARED 속성은 UNIQUE 제약 조건과 동시에 정의할 수 없다. 초기에 설정한 값과 다른 새로운 값을 INSERT 하면, 해당 칼럼 값은 모든 행에서 새로운 값으로 갱신된다.
- DEFAULT : 새로운 행을 삽입할 때 칼럼 값을 지정하지 않으면 DEFAULT 속성으로 설정한 값이 저장된다.
-
DEFAULT 속성값으로 허용되는 의사 칼럼(pseudocolumn)과 함수는 다음과 같다 :
| DEFAULT 값 | 데이터 타입 |
|---|---|
| SYS_TIMESTAMP | TIMESTAMP |
| UNIX_TIMESTAMP() | INTEGER |
| CURRENT_TIMESTAMP | TIMESTAMP |
| SYS_DATE_TIME | DATETIME |
| CURRENT_DATETIME | DATETIME |
| SYS_DATE | DATE |
| CURRENT_DATE | DATE |
| SYS_TIME | TIME |
| CURRENT_TIME | TIME |
| USER, USER() | STRING |
| TO_CHAR(data_time[, format]) | STRING |
| TO_CHAR(number,[, format]) | STRING |
-
칼럼값에 자동으로 일련번호를 부여하려면 AUTO_INCREMENT 속성을 사용한다.
-
칼럼의 제약 조건 종류는 NOT NULL, UNIQUE, PRIMARY KEY, FOREIGN KEY가 있다.
| 제약 조건 | 의미 |
|---|---|
| NOT NULL | 반드시 NULL이 아닌 값을 가져야 함 |
| UNIQUE | 정의된 칼럼이 고유한 값을 갖도록 함 |
| PRIMARY KEY | 기본키로 정의된 칼럼 값은 각 행에서 고유하게 식별됨 |
| FOREIGH KEY | 참조 관계에 있는 다른 테이블의 기본키를 참조 |
테이블에서 key란 각 행을 고유하게 식별할 수 있는 하나 이상의 칼럼들의 집합을 말한다. candidate key(후보키)는 테이블 내의 각 행을 고유하게 식별하는 칼럼들의 집합을 의미하며, 사용자는 이러한 candidate key 중 하나를 primary key(기본키)로 정의할 수 있다.
foreign key(외래키)와 참조되는 primary key(기본키)는 동일한 데이터 타입을 가져야 한다. foreign key가 primary key를 참조함에 따라 연관되는 두 테이블 사이에는 일관성이 유지되는데, 이를 참조 무결성이라 한다.
CREATE TABLE LIKE
-
이미 존재하는 테이블과 동일한 스키마의 테이블을 생성한다.
-
데이터는 빈 상태로 생성된다.
CREATE TABLE AS SELECT
- SELECT 결과 데이터를 가진 테이블을 새로 생성한다.
ALTER TABLE
-
테이블의 칼럼, 제약 조건, 인덱스를 추가하거나 변경 또는 삭제한다.
-
ADD COLUMN
- 새로운 칼럼을 추가한다.
- FIRST 또는 AFTER 키워드를 사용하여 추가할 칼럼의 위치를 지정할 수 있다.
-
ADD CONSTRAINT
- 새로운 제약 조건을 추가한다.
-
ADD INDEX
- 특정 칼럼에 대해 인덱스 속성을 추가로 정의한다.
-
ALTER COLUMN ... SET DEFAULT
- 기본값이 없는 칼럼에 기본값을 지정하거나 기존의 기본값을 변경할 수 있다.
-
AUTO_INCREMENT
- 기존에 정의한 자동 증가값의 초기값을 변경한다.
- 단, 테이블 내에 AUTO_INCREMENT 칼럼이 한 개만 정의되어 있어야 한다.
-
CHANGE
- 칼럼의 이름, 타입, 크기 및 속성을 변경한다.
- 기존 칼럼의 이름과 새 칼럼의 이름이 같으면 타입, 크기 및 속성만 변경한다.
-
MODIFY
- 칼럼의 타입, 크기 및 속성을 변경할 수 있으며, 칼럼의 이름은 변경할 수 없다.
-
RENAME COLUMN
- 칼럼의 이름을 변경한다.
-
DROP COLUMN
- 테이블에 존재하는 칼럼을 삭제한다.
-
DROP CONSTRAINT
- 테이블에 이미 정의된 UNIQUE, PRIMARY KEY, FOREIGN KEY 제약 조건을 삭제한다.
-
DROP INDEX
- 인덱스를 삭제한다.
- DROP CONSTRAINT 로도 삭제할 수 있다.
-
DROP PRIMARY KEY
- 테이블에 정의된 기본키 제약 조건을 삭제한다.
-
DROP FOREIGN KEY
- 테이블에 정의된 외래키 제약 조건을 삭제한다.
DROP TABLE
- 테이블을 제거한다.
RENAME TABLE
- 테이블의 이름을 변경한다.
2. 인덱스 정의문
CREATE INDEX
- 인덱스를 생성한다.
ALTER INDEX
-
인덱스의 이름을 변경하거나 인덱스를 재생성한다.
-
REBUILD
- 이미 생성된 것과 같은 구조의 인덱스를 재생성한다.
DROP INDEX
-
인덱스를 제거한다.
-
고유 인덱스는 DROP CONSTRAINT로도 삭제할 수 있다.
3. 뷰 정의문
뷰는 물리적으로 존재하지 않는 가상의 테이블이며, 기존의 테이블이나 뷰에 대한 질의문을 이용하여 뷰를 생성할 수 있다.
CREATE VIEW
-
뷰를 생성한다.
-
CREATE 뒤에 OR REPLACE 키워드가 명시되면, 기존의 뷰와 이름이 중복되더라도 에러를 출력하지 않고 기존의 뷰를 새로운 뷰로 대체한다.
-
갱신 가능한 뷰를 생성하려면 다음 조건을 만족해야 한다.
- FROM 절은 갱신 가능한 테이블이나 뷰만 포함한다.
- JOIN 구문을 포함하지 않는다.
- DISTINCT, UNIQUE 구문을 포함하지 않는다.
- GROUP BY ... HAVING 구문을 포함하지 않는다.
- SUM(), AVG()와 같은 집계 함수를 포함하지 않는다.
- UNION 구문을 포함하지 않는다.
- UNION ALL을 사용해 갱신 가능한 부분 질의로만 질의를 구성한 경우에는 갱신이 가능하다.
- 단, 테이블은 UNION ALL을 구성하는 부분 질의 중 어느 한 질의에만 존재해야 하며, UNION ALL 구문으로 생성된 뷰에 레코드를 삽입하는 경우 레코드가 입력될 테이블은 시스템이 결정한다.
ALTER VIEW
-
뷰를 갱신한다.
-
ADD QUERY
- 뷰의 질의 명세부에 질의를 추가한다.
-
AS SELECT
- 가상 테이블에 정의된 SELECT 질의를 변경한다.
-
CHANGE QUERY
- 뷰 질의 명세부에 정의된 질의를 변경한다.
-
DROP QUERY
- 뷰 질의 명세부에 정의된 질의를 삭제한다.
-
COMMENT
- 뷰와 칼럼들, 어트리뷰트들의 커멘트를 변경한다.
DROP VIEW
- 뷰를 제거한다.
RENAME VIEW
- 뷰의 이름을 변경한다.
4. 시리얼 정의문
CREATE SERIAL
-
고유한 순번을 반환하는 시리얼을 생성한다.
-
시리얼 번호는 테이블과 독립적으로 생성된다.
ALTER SERIAL
- 시리얼의 증가량, 시작값, 최댓값을 변경하거나 제거한다.
DROP SERIAL
- 시리얼을 제거한다.
5. 사용자 권한
큐브리드는 기본적으로 DBA와 PUBLIC이라는 두 종류의 사용자를 제공한다.
CREATE USER
- 사용자를 생성한다.
ALTER USER
- 사용자의 암호를 변경한다.
DROP USER
- 사용자를 삭제한다.
CREATE USER ... GROUPS
- 사용자 그룹을 생성한다.
CREATE USER ... MEMBERS
- 사용자를 생성하고 해당 사용자를 명시한 그룹에 포함시킨다.
GRANT operation TO user
- 특정 사용자에게 특정 연산(INSERT, UPDATE, DELETE 등) 권한을 부여한다.
6. 데이터 조작문
SELECT
-
지정된 테이블에서 원하는 칼럼을 조회한다.
-
FROM
- 데이터를 조회하고자 하는 테이블을 지정한다.
-
WHERE
- 조회하려는 데이터의 조건을 명시한다.
-
ORDER BY
- 오름차순(ASC) 또는 내림차순(DESC)으로 정렬한다.
- 옵션을 명시하지 않으면 오름차순으로 정렬한다.
-
LIMIT
- 출력할 레코드의 개수를 제한한다.
-
JOIN
- 두 개 이상의 테이블 또는 뷰에 대해 행을 결합한다.
- 내부 조인(inner join), 왼쪽 외부 조인(left outer join), 오른쪽 외부 조인(right outer join)을 지원한다.
- 완전 외부 조인(full outer join)은 지원하지 않는다.
-
VALUES
- 표현식에 명시된 행 값들을 출력한다.
- UNION ALL 질의를 간단히 표현하는 방법이다.
- INSERT 문과 함께 사용하면 하나의 INSERT 문으로 여러 개의 행을 입력할 수 있다.
-
FOR UPDATE
- UPDATE 문, DELETE 문에서 사용할 행에 대해 미리 잠금(lock)을 설정한다.
-
START WITH ... CONNECT BY
- 계층 질의를 수행한다.
INSERT
-
데이터베이스에 존재하는 테이블에 새로운 레코드를 삽입한다.
-
INSERT ... SELECT
- SELECT 결과를 대상 테이블에 삽입한다.
-
ON DUPLICATE KEY UPDATE
- 삽입(INSERT)을 수행하되 고유 키 위반(unique key violation)이면 고유 키 조건의 행에 대해 갱신(UPDATE)을 수행한다.
- 즉, UNIQUE 인덱스 또는 PRIMARY KEY 제약 조건이 설정된 칼럼에 중복된 값이 삽입되는 상황에서 에러를 출력하지 않고 새로운 값으로 갱신한다.
- 사용자가 ON DUPLICATE KEY UPDATE 문을 수행할 수 있게 GRANT 문으로 사용자 권한을 부여하려면 INSERT 권한뿐만 아니라 UPDATE 권한도 부여해야 한다.
MERGE
-
하나 이상의 원본으로부터 하나의 테이블 또는 뷰에 삽입 또는 갱신을 수행한다.
-
또한 삭제 조건도 추가할 수 있다.
-
사용자가 MERGE 문을 수행할 수 있게 GRANT 문으로 사용자 권한을 부여하려면 INSERT 권한, UPDATE 권한, 그리고 DELETE 권한을 부여해야 한다.
UPDATE
-
대상 테이블 또는 뷰에 저장된 레코드의 칼럼 값을 새로운 값으로 업데이트한다.
-
LIMIT
- 갱신할 레코드 개수를 한정한다.
-
ORDER BY
- 명시한 순서에 따라 갱신을 수행한다.
- 트리거의 실행 순서나 잠금 순서를 유지하고자 할 때 유용하다.
-
JOIN
- 여러 개의 테이블을 조인한 후 갱신을 수행한다.
REPLACE
-
INSERT 와 비슷하지만, 고유 키 위반이면(PRIMARY KEY 또는 UNIQUE 제약 조건이 정의된 칼럼에 중복된 값을 삽입) 에러 출력 없이 기존 레코드를 삭제한 후 새로운 레코드를 삽입한다.
-
REPLACE 문을 수행하려면 INSERT 권한과 DELETE 권한이 모두 필요하다.
DELETE
-
테이블 내에 레코드를 삭제한다.
-
WHERE과 결합하여 삭제 조건을 명시할 수 있다.
-
LIMIT
- 삭제할 행의 개수를 제한한다.
-
JOIN
- 여러 개의 테이블을 조인한 후 삭제를 수행한다.
TRUNCATE
-
명시된 테이블의 모든 레코드를 삭제한다.
-
내부적으로 테이블에 정의된 모든 인덱스와 제약 조건을 먼저 삭제한 후 레코드를 삭제하므로 WHERE 조건이 없은 DELETE 문을 수행하는 것보다 빠르다.
-
하지만 DELETE 문과는 구분되므로 ON DELETE 트리거가 활성화되지 않는다.
-
AUTO_INCREMENT 칼럼을 초기화해 데이터가 다시 입력되면 시작값부터 생성한다.
7. 자료형
큐브리드는 기본적인 문자 자료형, 숫자 자료형, 날짜/시간 자료형을 지원하며, 추가로 BLOB, CLOB 자료형을 지원한다.
7-1. 숫자 자료형
| 타입 | 바이트 | 최솟값 | 최댓값 |
|---|---|---|---|
| SHORT, SMALLINT | 2 | -32,768 | 32,767 |
| INTEGER, INT | 4 | -2,147,483,648 | 2,147,483,647 |
| BIGINT | 8 | -9,223,372,036,854,775,808 | 9,223,372,036,854,775,807 |
| NUMERIC, DECIMAL | 16 | 정밀도 p : 1 / 스케일 s : 0 | 정밀도 p : 38 / 스케일 s : 38 |
| FLOAT, REAL | 4 | -3.402823466E+38 (ANSI/IEEE 754-1985 표준) | 3.402823466E+38 (ANSI/IEEE 754-1985 표준) |
| DOUBLE, DOUBLE PRECISION | 8 | -1.7976931348623157E+308 (ANSI/IEEE 754-1985 표준) | 1.7976931348623157E+308 (ANSI/IEEE 754-1985 표준) |
큐브리드는 수치형 데이터 타입에 대해 UNSIGNED 타입을 지원하지 않는다.
7-2. 스트링 자료형
큐브리드는 두 가지 비트열을 지원한다.
-
고정길이 비트열 : BIT(n)
- n은 최대 비트의 개수를 나타낸다.
- n이 생략되면 길이는 1로 지정된다.
-
가변길이 비트열 : BIT VARYING(n)
- n은 최대 비트의 개수를 나타낸다.
- n이 생략되면 최대 길이인 1,073,741,823으로 지정된다.
큐브리드는 두 종류의 문자열 타입을 지원한다.
-
고정길이 문자열 : CHAR(n)
- n은 문자의 개수를 나타낸다.
- n이 생략되면 기본값인 1로 지정된다.
-
가변길이 문자열 : VARCHAR(n)
- n은 문자의 개수를 나타낸다.
- n이 생략되면 길이는 최대인 1,073,741,823으로 지정된다.
-
가변길이 문자열 : STRING
- VARCHAR를 최대 길이로 지정한 것과 같다.
큐브리드는 두 가지 LOB 타입을 지원한다.
-
Binary Large Object(BLOB)
- 바이너리 데이터를 DB 외부에 저장하기 위한 타입이다.
- 데이터의 최대 길이는 외부 저장소에서 생성 가능한 파일 크기이다.
-
Character Large Object(CLOB)
- 문자열 데이터를 DB 외부에 저장하기 위한 타입이다.
- 데이터의 최대 길이는 외부 저장소에서 생성 가능한 파일 크기이다.
큐브리드는 ENUM 데이터 타입을 지원한다.
- ENUM 타입은 열거형 문자열 상수들의 중복 없는 순서 집합으로 구성되어 있는 타입이다.
External LOB(Large Object) 타입은 텍스트 또는 이미지 등 크기가 큰 객체를 처리하기 위한 데이터 타입이다.
7-3. 날짜 자료형
| 타입 | 바이트 | 최솟값 | 최댓값 |
|---|---|---|---|
| DATE | 4 | 0001년 1월 1일 | 9999년 12월 31일 |
| TIME | 4 | 00시 00분 00초 | 23시 59분 59초 |
| TIMESTAMP | 4 | 1970년 1월 1일 0시 0분 1초(GMT) 1970년 1월 1일 9시 0분 1초(KST) | 2038년 1월 19일 3시 14분 7초(GMT) 2038년 1월 19일 12시 14분 7초(KST) |
| DATETIME | 4 | 0001년 1월 1일 0시 0분 0.000초 | 9999년 12월 31일 23시 59분 59.999초 |
7-4. 자료형 비료
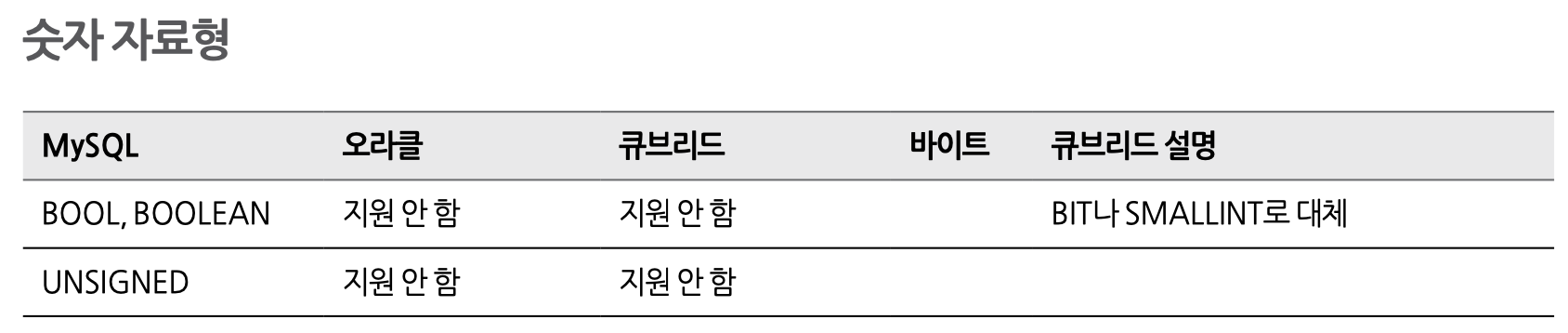
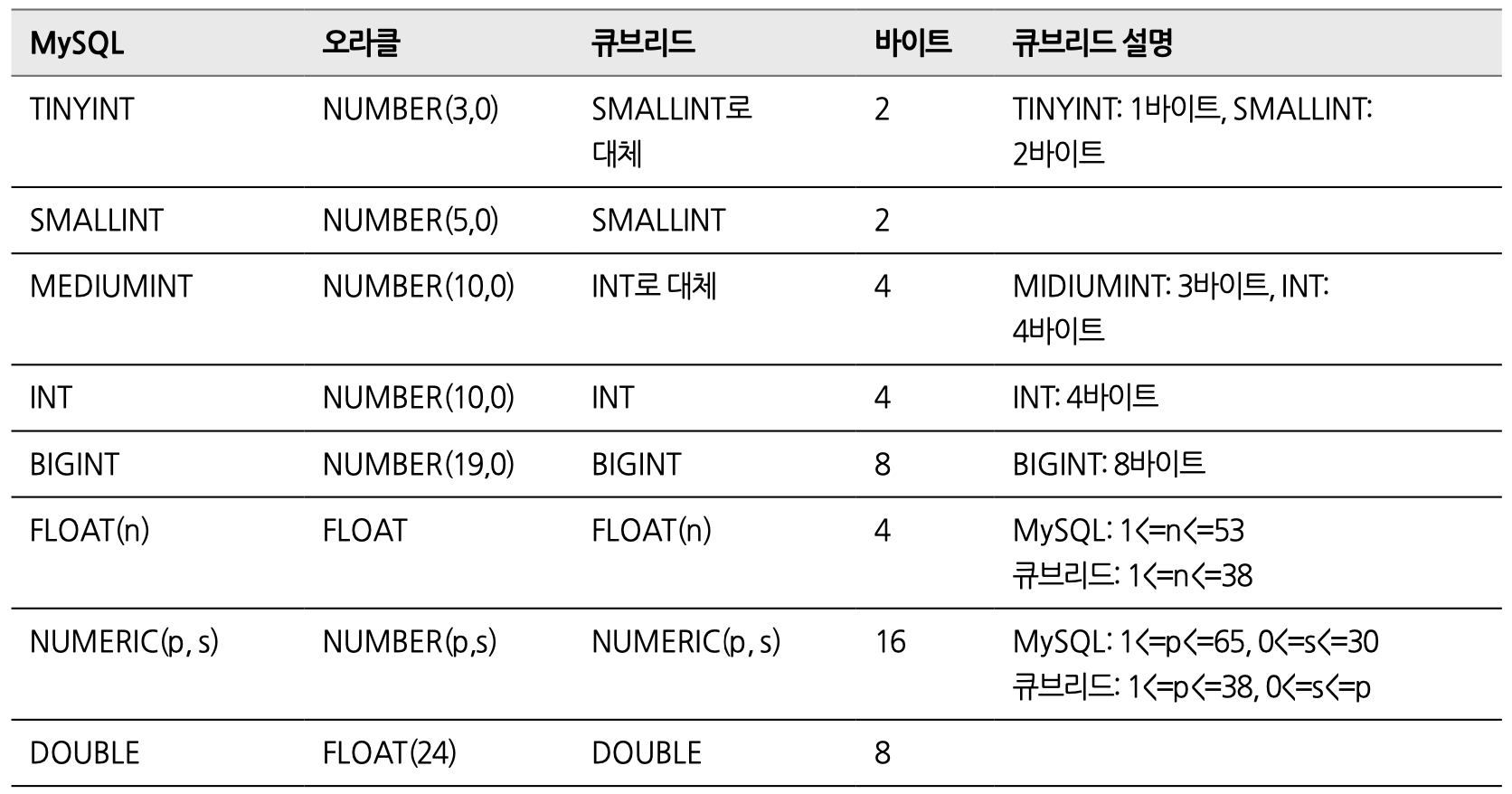


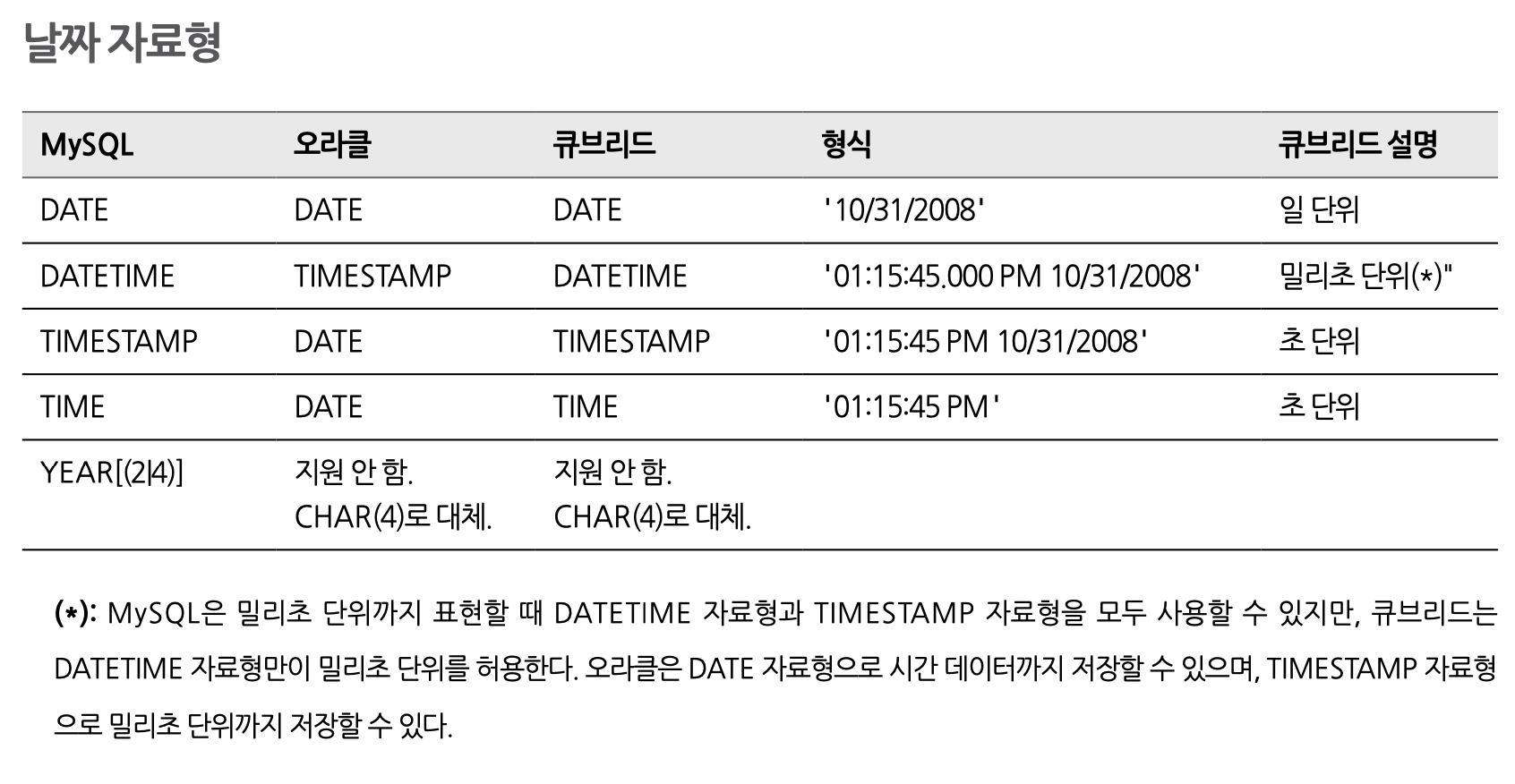
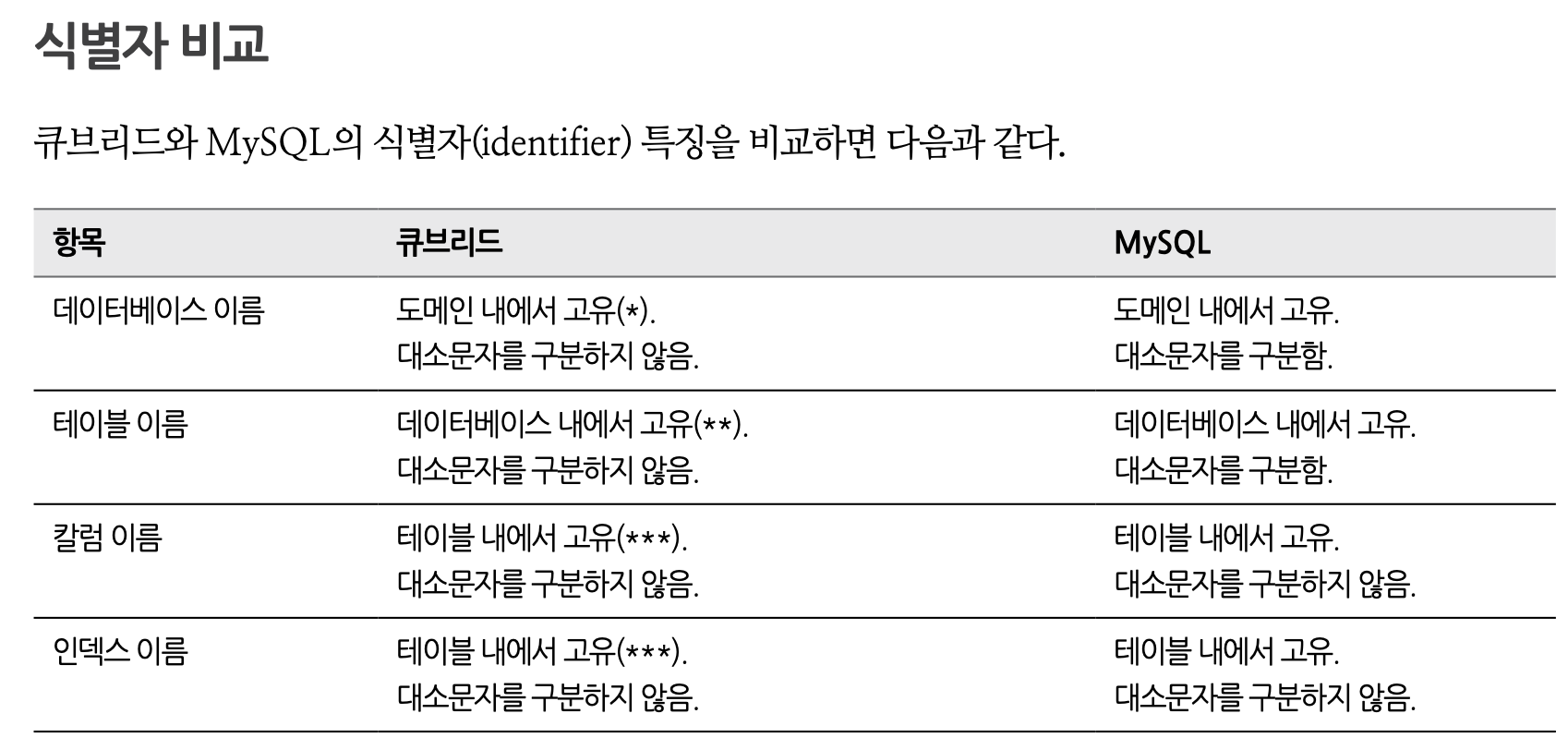
8. 식별자 비교

본 시리즈의 글들은 CUBRID DB엔진 오픈 스터디를 진행하며 팀원들과 함께 공부한 내용을 정리한 것입니다.
Github 링크
SQL 발표 내용
참고
CUBRID Manual
도서 『시작하세요! 큐브리드』
