Spark Partition의 개념
Partition은 RDDs나 Dataset를 구성하고 있는 최소 단위 객체이다.
각 Partition은 서로 다른 노드에서 분산 처리된다.
Spark에서는 하나의 최소 연산을 Task라고 표현하는데, 이 하나의 Task에서 하나의 Partition이 처리된다. 또한, 하나의 Task는 하나의 Core가 연산 처리한다.
1 Core = 1 Task = 1 Partition
예시) 전체 Core 수를 300개로 세팅한 상태이고, 이 300개가 현재 실행 중인 Task 수이자, 현재 처리 중인 Partition 수에 해당한다. 또한, 전체 Patition 수는 1800개로 세팅했으며, 이는 전체 Task 수이다.
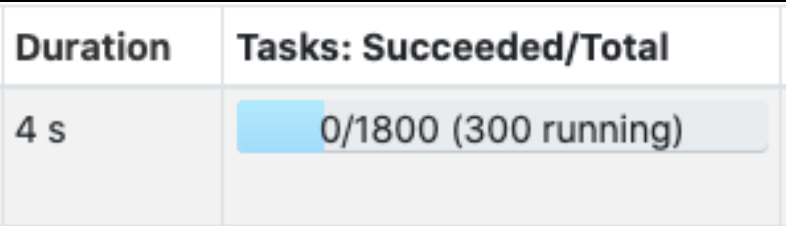
이처럼 설정된 Partition 수에 따라 각 Partition의 크기가 결정된다.
그리고 이 Partition의 크기가 결국 Core 당 필요한 메모리 크기를 결정하게 된다.
- Partition 수 → Core 수
- Partition 크기 → 메모리 크기
따라서, Partition의 크기와 수가 Spark 성능에 큰 영향을 미치는데, 통상적으로는 Partition의 크기가 클수록 메모리가 더 필요하고, Partition의 수가 많을수록 Core가 더 필요하다.
- 적은 수의 Partition = 크기가 큰 Partition
- 많은 수의 Partition = 크기가 작은 Partition
즉, Partition의 수를 늘리는 것은 Task 당 필요한 메모리를 줄이고 병렬화의 정도를 늘린다.
Input Partition
관련 설정 : spark.sql.files.maxpartitionBytes
Input Partition은 처음 파일을 읽을 때 생성하는 Partition이다.
관련 설정값은 spark.sql.files.maxPartitionBytes으로, Input Partition의 크기를 설정할 수 있고, 기본값은 128MB.
파일 (HDFS 상의 마지막 경로에 존재하는 파일)의 크기가 128MB보다 크다면, Spark에서 128MB만큼 쪼개면서 파일을 읽는다. 파일의 크기가 128MB보다 작다면 그대로 읽어 들여, 파일 하나당 Partition 하나가 된다.
대부분의 경우, 필요한 칼럼만 골라서 뽑아 쓰기 때문에 파일이 128MB보다 작습니다. 가끔씩 큰 파일을 다룰 경우에는 이 설정값을 조절해야한다.
Output Partition
관련 설정 : df.repartition(cnt), df.coalesce(cnt)
Output Partition은 파일을 저장할 때 생성하는 Partition이다.
이 Partition의 수가 HDFS 상의 마지막 경로의 파일 수를 지정한다.
기본적으로, HDFS는 큰 파일을 다루도록 설계되어 있어, 크기가 큰 파일로 저장하는 것이 좋다.
보통 HDFS Blocksize에 맞게 설정하면 되는데, 통상적으로 파일 하나의 크기를 256MB에 맞도록 Partition의 수를 설정하면 된다.
Partition의 수는 df.repartition(cnt), df.coalesce(cnt)를 통해 설정한다. 이 repartition와 coalesce를 이용해 Partition 수를 줄일 수 있다.
아래의 예시는, 파일 수를 줄여서 50개로 저장하는 모습.
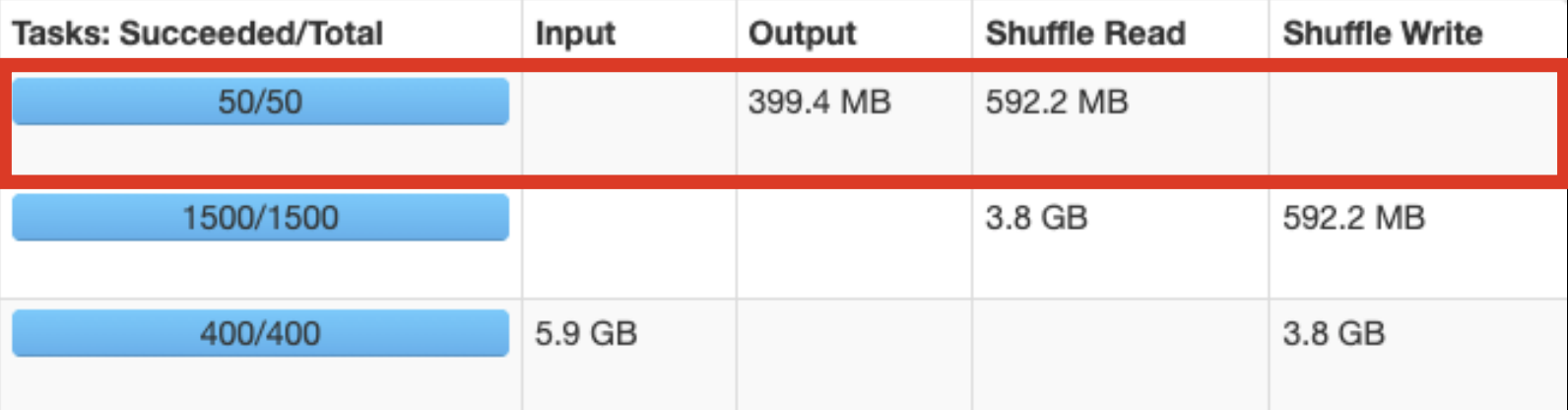
Shuffle Partition
관련 설정 : spark.sql.shuffle.partitions
Spark 성능에 가장 크게 영향을 미치는 Partition으로, Join, groupBy 등의 연산을 수행할 때 Shuffle Partition이 쓰인다.
설정값은 spark.sql.shuffle.partitions이고, 이 설정값에 따라 Join, groupBy 수행 시 Partition의 수(또는 Task의 수)가 결정된다.
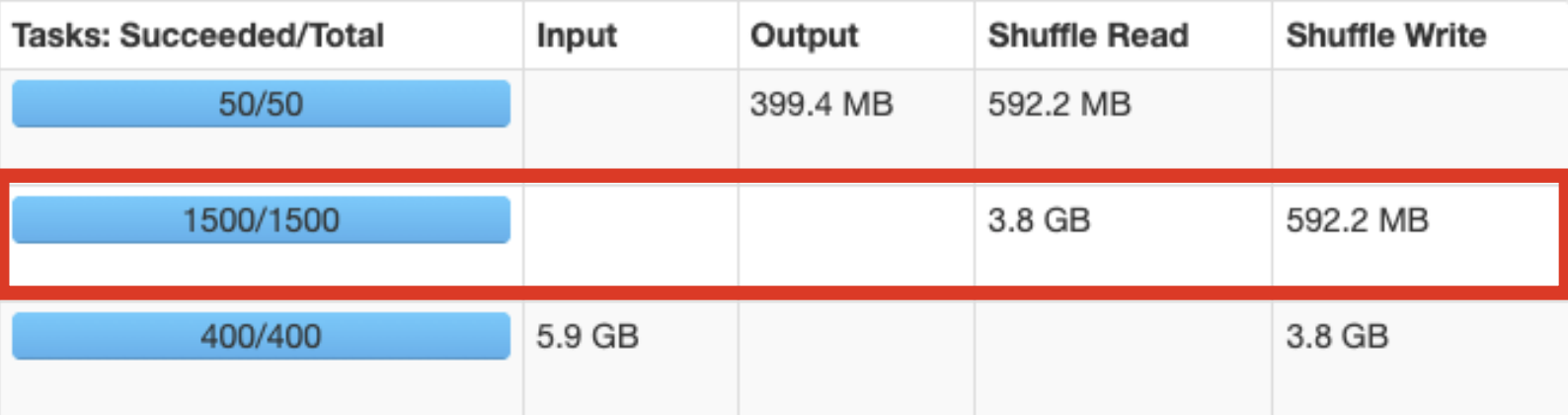
이 설정값은 Core 수에 맞게 설정하라고 하지만, Partition의 크기에 맞추어서 설정해야 한다.
이 Partition의 크기가 크고 연산에 쓰이는 메모리가 부족하다면 Shuffle Spill(데이터를 직렬화하고 스토리지에 저장, 처리 이후에는 역 직렬화하고 연산 재개함)이 일어나기 때문이다.
Shuffle Spill이 일어나면, Task가 지연되고 에러가 발생할 수 있다.
또한, Hadoop 클러스터의 사용률이 높다면, 연달아 에러가 발생하고 Spark가 강제 종료될 수 있다.
Memory Limit Over와 같이, Shuffle Spill도 메모리 부족으로 나타나는데, 보통 이에 대한 대응을 Core 당 메모리를 늘리는 것으로 해결한다.
하지만, 모든 사람이 메모리가 부족하다고 메모리 할당량을 늘린다면, 클러스터가 사용성이 더 떨어지고 작업이 더욱더 실패하게 된다. Partition의 크기를 결정하는 옵션인 spark.sql.shuffle.partitions를 우선적으로 고려해 설정해야 한다고 생각한다.
또한, 일반적으로, 하나의 Shuffle Partition 크기가 100~200MB 정도 나올 수 있도록 spark.sql.shuffle.partitions 수를 조절하는 것이 최적이다.
각 실험별 정리
| 구분 | 실험1 | 실험2 | 실험3 | 실험4 |
|---|---|---|---|---|
| 메모리 / Core 수 | 6GB / 3cores | 6GB / 3cores | 6GB / 3cores | 3GB / 3cores |
| 쿼리 최적화 | X | X | O | O |
| Partition 수 | 300 | 1800 | 1800 | 1800 |
| 수행시간 | 8.4h | 5.5h | 3.5h | 3.7h |
| Shuffle Size | 250GB | 250GB | 250GB | 250GB |
| Shuffle Size / Partition | 840MB | 140MB | 140MB | 140MB |
| Shuffle Spill | 770GB | 220GB | 0 | 0 |
| 에러 수 | 6 | 1 | 0 | 0 |
