[Tech Interview] 알고리즘(Algorithm)
[기술 면접]

거품 정렬(Bubble Sort)
목표
- Bubble Sort에 대해 설명할 수 있다.
- Bubble Sort 과정에 대해 설명할 수 있다.
- Bubble Sort을 구현할 수 있다.
- Bubble Sort의 시간복잡도와 공간복잡도를 계산할 수 있다.
Abstract
Bubble Sort는 Selection Sort와 유사한 알고리즘으로 서로 인접한 두 원소의 대소를 비교하고, 조건에 맞지 않다면 자리를 교환하며 정렬하는 알고리즘이다.
Process (Ascending)
-
1회전에 첫 번째 원소와 두 번째 원소를, 두 번째 원소와 세 번쨰 원소를, 세 번째 원소와 네 번째 원소를, ... 이런 식으로 (마지막-1)번째 원소와 마지막 원소를 비교하여 조건에 맞지 않는다면 서로 교환한다.
-
1회전을 수행하고 나면 가장 큰 원소가 맨 뒤로 이동하므로 2회전에서는 맨 끝에 있는 원소는 정렬에서 제외되고, 2회전을 수행하고 나면 끝에서 두 번째 원소까지는 정렬에서 제외된다. 이렇게 정렬을 1회전 수행할 때마다 정렬에서 제외되는 데이터가 하나씩 늘어난다.
Java Code (Ascending)
void bubbleSort(int[] arr) {
int temp = 0;
for(int i=0; i < arr.length; i++) { // 1.
for(int j = 1; j < arr.length-i; j++} { // 2.
if(arr[j-1] > arr[j]) { // 3.
//swap(arr[j-1], arr[j])
temp = arr[j-1];
arr[j-1] = arr[j];
arr[j] = temp;
}
}
}
System.out.println(Arrays.toString(arr));
}-
제외될 원소의 갯수를 의미한다. 1회전이 끝난 후, 배열의 마지막 위치에는 가장 큰 원소가 위치하기 때문에 하나씩 증가시켜준다.
-
원소를 비교할 index를 뽑을 반복문이다. j는 현재 원소를 가리키고, j-1은 이전 원소를 가리키게 되므로, j는 1부터 시작하게 된다.
-
현재 가리키고 있는 두 원소의 대소를 비교한다. 해당 코드는 오름차순 정렬이므로 현재 원소보다 이전 원소가 더 크다면 이전 원소가 뒤로 가야하므로 서로 자리를 교환해준다.
GIF로 이해하는 Bubble Sort

시간복잡도
시간복잡도를 계산하면, (n-1) + (n-2) + (n-3) + ... + 2 + 1 => n(n-1)/2 이므로, O(n^2) 이다. 또한, Bubble Sort는 정렬 여부에 관계없이 2개의 원소를 비교하기 때문에 최선, 평균, 최악의 경우 모두 시간복잡도가 O(n^2) 으로 동일하다. (개선된 Bubble Sort가 존재하지만, 기초를 다지기 위한 학습이므로 여기에서는 패스함)
공간복잡도
주어진 배열 안에서 교환(swap)을 통해 정렬이 수행되므로 O(n) 이다.
장점
- 구현이 매우 간단하고, 소스코드가 직관적이다.
- 정렬하고자 하는 배열 안에서 교환하는 방식이므로, 다른 메모리 공간을 필요로 하지 않는다. => 제자리 정렬(in-place sorting)
- 안정 정렬(Stable Sort) 이다.
단점
- 시간복잡도가 최악, 최선, 평균 모두 O(n^2)으로, 굉장히 비효율적이다.
- 정렬되어 있지 않은 원소가 정렬되었을 때의 자리로 가기 위해서, 교환 연산(swap)이 많이 일어나게 된다.
선택 정렬(Selection Sort)
목표
- Selection Sort에 대해 설명할 수 있다.
- Selection Sort 과정에 대해 설명할 수 있다.
- Selection Sort을 구현할 수 있다.
- Selection Sort의 시간복잡도와 공간복잡도를 계산할 수 있다.
Abstract
Selection Sort는 Bubble Sort과 유사한 알고리즘으로, 해당 순서에 원소를 넣을 위치는 이미 정해져 있고, 어떤 원소를 넣을지 선택하는 알고리즘이다.
Selection Sort와 Insertion Sort를 종종 헷갈려하는데, Selection Sort는 배열에서 해당 자리를 선택하고 그 자리에 오는 값을 찾는 것이라고 생각하면 된다.
Process (Ascending)
- 주어진 배열 중에 최솟값을 찾는다.
- 그 값을 맨 앞에 위치한 값과 교체한다. (pass)
- 맨 처음 위치를 뺀 나머지 배열을 같은 방법으로 교체한다.
Java Code (Ascending)
void selectionSort(int[] arr) {
int indexMin, temp;
for (int i=0; i < arr.length-1; i++) { // 1.
indexMin = i;
for (int j = i+1; j < arr.length; j++) { // 2.
if (arr[j] < arr[indexMin]) { // 3.
indexMin = j;
}
}
// 4. swap(arr[indexMin], arr[i])
temp = arr[indexMin];
arr[indexMin] = arr[i];
arr[i] = temp;
}
System.out.println(Arrays.toString(arr));
}-
우선 위치(index)를 선택해준다.
-
i+1번째 원소부터 선택한 위치(index)의 값과 비교를 시작한다
-
오름차순이므로 현재 선택한 자리에 있는 값보다 순회하고 있는 값이 작다면, 위치(index)를 갱신해준다.
-
'2'번 반복문이 끝난 뒤에는 indexMin에 '1'번에서 선택한 위치(index)에 들어가야 하는 값의 위치(index)를 갖고 있으므로 서로 교환(swap)해준다.
GIF로 이해하는 Selection Sort

시간복잡도
데이터의 개수가 n개라고 했을 때,
- 첫 번째 회전에서의 비교 횟수: 1 ~ (n-1) => n-1
- 두 번째 회전에서의 비교 횟수: 2 ~ (n-1) => n-2
...
(n-1) + (n-2) + .... + 2 + 1 => n(n-1)/2
비교하는 것이 상수 시간에 이루어진다는 가정 아래, n개의 주어진 배열을 정렬하는데 O(n^2) 만큼의 시간이 걸린다. 최선, 평균, 최악의 경우 시간복잡도는 O(n^2)으로 동일하다.
공간복잡도
주어진 배열 안에서 교환(swap)을 통해 정렬이 수행되므로 O(n) 이다.
장점
-
Bubble sort와 마찬가지로 알고리즘이 단순하다.
-
정렬을 위한 비교 횟수는 많지만, Bubble Sort에 비해 실제로 교환하는 횟수는 적기 때문에 많은 교환이 일어나야 하는 자료 상태에서 비교적 효율적이다.
-
Bubble Sort와 마찬가지로 정렬하고자 하는 배열 안에서 교환하는 방식이므로, 다른 메모리 공간을 필요로 하지 않는다. => 제자리 정렬(in-place sorting)
단점
- 시간복잡도가 O(n^2)으로 비효율적이다.
- 불안정 정렬(Unstable Sort) 이다.
삽입 정렬(Insertion Sort)
목표
- Insertion Sort에 대해 설명할 수 있다.
- Insertion Sort 과정에 대해 설명할 수 잇다.
- Insertion Sort을 구현할 수 있다.
- Insertion Sort의 시간복잡도와 공간복잡도를 계산할 수 있다.
- Insertion Sort와 Selection Sort의 차이에 대해 설명할 수 있다.
Abstract
손 안의 카드를 정렬하는 방법과 유사하다.
Insertion Sort는 Selection Sort와 유사하지만, 좀 더 효율적인 정렬 알고리즘이다.
Insertion Sort는 2번째 원소부터 시작하여 그 앞(왼쪽)의 원소들과 비교하여 삽입할 위치를 지정한 후, 원소를 뒤로 옮기고 지정된 자리에 자료를 삽입하여 정렬하는 알고리즘이다.
최선의 경우 O(N)이라는 엄청나게 빠른 효율성을 가지고 있어, 다른 정렬 알고리즘의 일부로 사용될 만큼 좋은 정렬 알고리즘이다.
Process (Ascending)
- 정렬은 2번째 위치(index)의 값을 temp에 저장한다.
- temp와 이전에 있는 원소들과 비교하며 삽입해나간다.
- '1'번으로 돌아가 다음 위치(index)의 값을 temp에 저장하고 반복한다.
Java Code (Ascending)
void insertionSort(int[] arr) {
for(int index = 1; index < arr.length; index++) { // 1.
int temp = arr[index];
int prev = index - 1;
while( (prev >= 0) && (arr[prev] > temp) ) { // 2.
arr[prev+1] = arr[prev];
prev--;
}
arr[prev + 1] = temp; // 3.
}
System.out.println(Arrays.toString(arr));
}-
첫 번째 원소 앞(왼쪽)에는 어떤 원소도 갖고 있지 않기 때문에, 두 번째 위치(index)부터 탐색을 시작한다. temp에 임시로 해당 위치(index) 값을 저장하고, prev에는 해당 위치(index)의 이전 위치(index)를 저장한다.
-
이전 위치(index)를 가리키는 prev가 음수가 되지 않고, 이전 위치(index)의 값이 '1'번에서 선택한 값보다 크다면, 서로 값을 교환해주고 prev를 더 이전 위치(index)를 가리키도록 한다.
-
'2'번에서 반복문이 끝나고 난 뒤, prev에는 현재 temp 값보다 작은 값들 중 제일 큰 값의 위치(index)를 가리키게 된다. 따라서 (prev+1)에 temp 값을 삽입해준다.
GIF로 이해하는 Insertion Sort

시간복잡도
최악의 경우(역으로 정렬되어 있을 경우) Selection Sort와 마찬가지로, (n-1) + (n-2) + .... + 2 + 1 => n(n-1)/2 즉, O(n^2) 이다.
하지만 모두 정렬이 되어 있는(Optimal)한 경우, 한 번씩밖에 비교하지 않으므로 O(n)의 시간복잡도를 가지게 된다. 또한, 이미 정렬되어 있는 배열에 자료를 하나씩 삽입/제거하는 경우에는 현실적으로 최고의 정렬 알고리즘이 되는데, 탐색을 제외한 오버헤드가 매우 적기 때문이다.
최선의 경우는 O(n)의 시간복잡도를 갖고, 평균과 최악의 경우 O(n^2)의 시간복잡도를 갖게 된다.
공간복잡도
주어진 배열 안에서 교환(swap)을 통해 정렬이 수행되므로 O(n) 이다.
장점
- 알고리즘이 단순하다.
- 대부분의 원소가 이미 정렬되어 있는 경우, 매우 효율적일 수 있다.
- 정렬하고자 하는 배열 안에서 교환하는 방식이므로, 다른 메모리 공간을 필요로 하지 않는다. => 제자리 정렬(in-place sorting)
- 안정 정렬(Stable Sort) 이다.
- Selection Sort나 Bubble Sort와 같은 O(n^2) 알고리즘에 비교하여 상대적으로 빠르다.
단점
- 평균과 최악의 시간복잡도가 O(n^2)으로 비효율적이다.
- Bubble Sort와 Selection Sort와 마찬가지로, 배열의 길이가 길어질수록 비효율적이다.
Conclusion
Selection Sort와 Insertion Sort는 k번째 반복 이후, 첫 번째 k 요소가 정렬된 순서로 온다는 점에서 유사하다.
하지만 Selection Sort는 k+1번째 요소를 찾기 위해 나머지 모든 요소들을 탐색하지만, Insertion Sort는 k+1번째 요소를 배치하는 데 필요한 만큼의 요소만 탐색하기 때문에 훨씬 효율적으로 실행된다는 차이가 있다.
퀵 정렬(Quick Sort)
목표
- Quick Sort에 대해 설명할 수 있다.
- Quick Sort 과정에 대해 설명할 수 있다.
- Quick Sort을 구현할 수 있다.
- Quick Sort의 시간복잡도와 공간복잡도를 계산할 수 있다.
- Quick Sort의 최악인 경우를 개선시킬 수 있다.
Abstract
Quick Sort은 분할 정복(divide and conquer) 방법을 통해 주어진 배열을 정렬한다.
분할 정복(divide and conquer) 방법
: 문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음,
결과를 모아서 원래의 문제를 해결하는 전략이다.Quick Sort은 불안정 정렬에 속하며, 다른 원소와의 비교만으로 정렬을 수행하는 비교 정렬에 속한다. 또한 Merge Sort와 달리 Quick Sort는 배열을 비균등하게 분할한다.
Process (Ascending)
-
배열 가운데서 하나의 원소를 고른다. 이렇게 고른 원소를 피벗(pivot)이라고 한다.
-
피벗 앞에는 피벗보다 값이 작은 모든 원소들이 오고, 피벗 뒤에는 피벗보다 값이 큰 모든 원소들이 오도록 피벗을 기준으로 배열을 둘로 나눈다. 이렇게 배열을 둘로 나누는 것을 분할(Divde)이라고 한다. 분할을 마친 뒤, 피벗은 더이상 움직이지 않는다.
-
분할된 두 개의 작은 배열에 대해 재귀(Recursion)적으로 이 과정을 반복한다.
- 재귀 호출이 한 번 진행될 때마다 최소한 하나의 원소는 최종적으로 위치가 정해지므로, 이 알고리즘은 반드시 끝난다는 것을 보장할 수 있다.
Java Code (Ascending)
퀵 정렬은 다음의 단계들로 이루어진다.
- 정복 (conquer)
부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출을 이용하여 다시 분할 정복 방법을 적용한다.
public void quickSort(int[] array, int left, int right) {
if(left >= right) return;
// 분할
int pivot = partition();
// 피벗은 제외한 2개의 부분 배열을 대상으로 순환 호출
quickSort(array, left, pivot-1); // 정복(Conquer)
quickSort(array, pivot+1, right); // 정복(Conquer)
}- 분할 (Divide)
입력 배열을 피벗을 기준으로 비균등하게 2개의 부분 배열 (피벗을 중심으로 왼쪽: 피벗보다 작은 요소들, 오른쪽: 피벗보다 큰 요소들)로 분할한다.
public int partition(int[] array, int left, int right) {
/**
// 최악의 경우, 개선 방법
int mid = (left + right) / 2;
swap(array, left, mid);
*/
int pivot = array[left]; // 가장 왼쪽 값을 피벗으로 설정
int i = left, j = right;
while(i < j) {
while(pivo < array[j]) {
j--;
}
while(i < j && pivot >= array[i]) {
i++;
}
swap(array, i, j);
}
array[left] = array[i];
array[i] = pivot;
return i;
}Quick Sort 개선
partition() 함수에서 피벗 값이 최소나 최대값으로 지정되어 파티션이 나누어지지 않았을 때, O(n^2)에 대한 시간복잡도를 가진다.
즉, 정렬하고자 하는 배열이 오름차순 정렬되어 있거나 내림차순 정렬되어 있으면 O(n^2)의 시간복잡도를 가진다. 이 때, 배열에서 가장 앞에 있는 값과 중간값을 교환해준다면 확률적으로나마 시간복잡도 O(nlog₂n)으로 개선할 수 있다. 하지만 이 방법으로 개선한다고 해도 Quick Sort의 최악의 시간복잡도가 O(nlog₂n)가 되는 것은 아니다.
GIF로 이해하는 Quick Sort

시간복잡도
최선의 경우(Best cases) : T(n) = O(nlog₂n)
- 비교 횟수
(log₂n)
레코드의 개수 n이 2의 거듭제곱이라고 가정(n=2^k) 했을 때, n=2^3의 경우, s^3 -> 2^2 -> 2^1 -> 2^0 순으로 줄어들어 순환 호출의 깊이가 3임을 알 수 있다.

이것을 일반화하면 n=2^k의 경우, k(k=log₂n) 임을 알 수 있다.
- 각 순환 호출 단계의 비교 연산
(n)
각 순환 호출에서는 전체 리스트의 대부분의 레코드를 비교해야 하므로 평균 n번 정도의 비교가 이루어진다.
따라서, 최선의 시간복잡도는 순환 호출의 깊이 * 각 순환 호출 단계의 비교 연산 = nlog₂n 가 된다. 이동 횟수는 비교 횟수보다 적으므로 무시할 수 있다.
최악의 경우(Worst cases) : T(n) = O(n^2)
최악의 경우는 정렬하고자 하는 배열이 오름차순 정렬되어 있거나 내림차순 정렬되어 있는 경우다.
- 비교 횟수
(n)

레코드의 개수 n이 2의 거듭제곱이라고 가정(n=2^k) 했을 때, 순환 호출의 깊이는 n 임을 알 수 있다.
- 각 순환 호출 단계의 비교 연산
(n)
각 순환 호출에서는 전체 리스트의 대부분의 레코드를 비교해야 하므로 평균 n번 정도의 비교가 이루어진다.
따라서, 최악의 시간복잡도는 순환 호출의 깊이 * 각 순환 호출 단계의 비교 연산 = n^2다. 이동 횟수는 비교 횟수보다 적으므로 무시할 수 있다.
평균의 경우(Average cases) : T(n) = O(nlog₂n)
공간복잡도
주어진 배열 안에서 교환(swap)을 통해 정렬이 수행되므로 O(n) 이다.
장점
- 불필요한 데이터의 이동을 줄이고, 먼 거리의 데이터를 교환할 뿐만 아니라, 한 번 결정된 피벗들이 추후 연산에서 제외되는 특성 때문에 시간 복잡도가 O(nlog₂n)를 가지는 다른 정렬 알고리즘과 비교했을 때도 가장 빠르다.
- 정렬하고자 하는 배열 안에서 교환하는 방식이므로, 다른 메모리 공간을 필요로 하지 않는다.
단점
- 불안정 정렬(Unstable Sort) 이다.
- 정렬된 배열에 대해서는 Quick Sort의 불균형 분할에 의해 오히려 수행시간이 더 많이 걸린다.
Conclusion
평균적으로 가장 빠른 정렬 알고리즘이다. JAVA에서 Arrays.sort() 내부적으로도 Dual Pivot Quick Sort로 구현되어 있을 정도로 효율적인 알고리즘이다.
병합 정렬(Merge Sort)
합병 정렬이라고도 부르며, 분할 정복 방법을 통해 구현
분할 정복이란?
큰 문제를 작은 문제 단위로 쪼개면서 해결해나가는 방식
빠른 정렬로 분류되며, 퀵 소트와 함께 많이 언급되는 정렬 방식이다.
퀵 소트와는 반대로 안정 정렬에 속함
시간복잡도
| 평균 | 최선 | 최악 |
|---|---|---|
| Θ(nlogn) | Ω(nlogn) | O(nlogn) |
요소를 쪼갠 후 다시 합병시키면서 정렬해 나가는 방식으로, 쪼개는 방식은 퀵 정렬과 유사
- mergeSort
public void mergeSort(int[] array, int left, int right) {
if(left < right) {
int mid = (left + right) / 2;
mergeSort(array, left, mid);
mergeSort(array, mid+1, right);
merge(array, left, mid, right);
}
}정렬 로직에 있어서 merge() 메소드가 핵심
퀵 소트와의 차이점
퀵 정렬 : 우선 피벗을 통해 정렬(partition) → 영역을 쪼갬(quickSort)
합병 정렬 : 영역을 쪼갤 수 있을 만큼 쪼갬(mergeSorg) → 정렬(merge)
- merge()
public static void merge(int[] array, int left, int mid, int right) {
int[] L = Arrays.copyOfRange(array, left, mid + 1);
int[] R = Arrays.copyOfRange(array, mid + 1, right + 1);
int i = 0, j = 0, k = left;
int ll = L.length, rl = R.length;
while(i < ll && j < rl) {
if(L[i] <= R[j]) {
array[k] = L[i++];
}
else {
array[k] = R[j++];
}
k++;
}
// remain
while(i < ll) {
array[k++] = L[i++];
}
while(j < rl) {
array[k++] = R[j++];
}
}이미 합병의 대상이 되는 두 영역이 각 영역에 대해서 정렬되어 있기 때문에 단순히 두 배열을 순차적으로 비교하면서 정렬할 수 있다.
합병 정렬은 순차적인 비교로 정렬을 진행하므로, LinkedList의 정렬이 필요할 때 사용하면 효율적이다.
- LinkedList를 퀵 정렬을 사용해 정렬하면?
성능이 좋지 않음
퀵 정렬은 순차 접근이 아닌 임의 접근이기 때문
LinkedList는 삽입, 삭제 연산에서 유용하지만 접근 연산에서는 비효율적임
따라서 임의로 접근하는 퀵 소트를 활용하면 오버헤드 발생이 증가하게 됨
배열은 인덱스를 이용해서 접근 가능하지만, LinkedList는 Head 부터 탐색해야 함
배열[O(1)] vs LinkedList[O(n)]
private void solve() {
int[] array = { 230, 10, 60, 550, 40, 220, 20 };
mergeSort(array, 0, array.length - 1);
for (int v : array) {
System.out.println(v);
}
}
public static void mergeSort(int[] array, int left, int right) {
if (left < right) {
int mid = (left + right) / 2;
mergeSort(array, left, mid);
mergeSort(array, mid + 1, right);
merge(array, left, mid, right);
}
}
public static void merge(int[] array, int left, int mid, int right) {
int[] L = Arrays.copyOfRange(array, left, mid + 1);
int[] R = Arrays.copyOfRange(array, mid + 1, right + 1);
int i = 0, j = 0, k = left;
int ll = L.length, rl = R.length;
while (i < ll && j < rl) {
if (L[i] <= R[j]) {
array[k] = L[i++];
} else {
array[k] = R[j++];
}
k++;
}
while (i < ll) {
array[k++] = L[i++];
}
while (j < rl) {
array[k++] = R[j++];
}
}힙 정렬(Heap Sort)
완전 이진 트리를 기본으로 하는 힙(Heap) 자료구조를 기반으로 한 정렬 방식
완전 이진 트리란?
삽입할 때 왼쪽부터 차례대로 추가하는 이진 트리
힙 소트는 불안정 정렬에 속함
시간 복잡도
| 평균 | 최선 | 최악 |
|---|---|---|
| Θ(nlogn) | Ω(nlogn) | O(nlogn) |
과정
1. 최대 힙을 구성
2. 현재 힙 루트는 가장 큰 값이 존재함. 루트의 값을 마지막 요소와 바꾼 후, 힙의 사이즈를 하나 줄임
3. 힙의 사이즈가 1보다 크면 위의 과정을 반복

루트를 마지막 노드로 대체 (11 → 4), 다시 최대 힙 구성

이와 같은 방식으로 최대 값을 하나씩 뽑아내면서 정렬하는 것이 힙 소트
public void heapSort(int[] array) {
int n = array.length;
// max heap 초기화
for (int i = n / 2-1; i >= 0; i--) {
heapify(array, n, i); // 1
}
// extract 연산
for (int i = n-1; i > 0; i--) {
swap(array, 0, i);
heapify(array, i, 0); // 2
}
}1번째 heapify
일반 배열을 힙으로 구성하는 역할
자식 노드로부터 부모 노드를 비교
- n / 2-1부터 0까지 인덱스가 도는 이유는?
부모 노드의 인덱스를 기준으로 왼쪽 자식노드 (i2 + 1), 오른쪽 자식노드(i2 + 2) 이기 때문
2번째 heapify
요소가 하나 제거된 이후에 다시 최대 힙을 구성하기 위함
루트를 기준으로 진행 (extract 연산 처리를 위해)
public void heapify(int array[], int n, int i) {
int p = i;
int l = i*2 + 1;
int r = i*2 + 2;
// 왼쪽 자식노드
if (l < n && array[p] < array[l]) {
p = l;
}
// 오른쪽 자식노드
if (r < n && array[p] < array[r]) {
p = r;
}
// 부모노드 < 자식노드
if(i != p) {
swap(array, p, i);
heapigy(array, n, p);
}
}다시 최대 힙을 구성할 때까지 부모 노드와 자식 노드를 swap하며 재귀 진행
퀵정렬과 합병정렬의 성능이 좋기 때문에 힙 정렬의 사용빈도가 높지는 않음
하지만 힙 자료구조가 많이 활용되고 있으며, 이때 함께 따라오는 개념이 힙 소트
힙 소트가 유용할 때
-
가장 크거나 가장 작은 값을 구할 때
최소 힙 or 최대 힙의 루트 값이기 때문에 한 번의 힙 구성을 통해 구하는 것이 가능
-
최대 k 만큼 떨어진 요소들을 정렬할 때
삽입 정렬보다 더욱 개선된 결과를 얻어낼 수 있음
전체 소스 코드
private void solve() {
int[] array = { 230, 10, 60, 550, 40, 220, 20 };
heapSort(array);
for (int v : array) {
System.out.println(v);
}
}
public static void heapify(int array[], int n, int i) {
int p = i;
int l = i * 2 + 1;
int r = i * 2 + 2;
if (l < n && array[p] < array[l]) {
p = l;
}
if (r < n && array[p] < array[r]) {
p = r;
}
if (i != p) {
swap(array, p, i);
heapify(array, n, p);
}
}
public static void heapSort(int[] array) {
int n = array.length;
// init, max heap
for (int i = n / 2-1; i >= 0; i --) {
heapify(array, n, i);
}
// for extract max element from heap
for (int i = n-1; i > 0; i--) {
swap(array, 0, i);
heapify(array, i, 0);
}
}
public static void swap(int[] array, int a, int b) {
int temp = array[a];
array[a] = array[b];
array[b] = temp;
}기수 정렬(Radix sort)
Comparison Sort
N개 원소의 배열이 있을 때, 이를 모두 정렬하는 가짓수는 N!임
따라서 Comparison Sort를 통해 생기는 트리의 말단 노드가 N! 이상의 노드 갯수를 갖기 위해서는 2^h >= N! 를 만족하는 h를 가져야 하고, 이 식을 h > O(nlgn)을 가져야 한다.
(h는 트리의 높이. 즉, Comparison sort의 시간 복잡도임)
이런 O(nlgn)을 줄일 수 있는 방법은 Comparison을 하지 않는 것!
Radix sort
데이터를 구성하는 기본 요소(Radix)를 이용하여 정렬을 진행하는 방식
입력 데이터의 최댓값에 따라서 Counting Sort의 비효율성을 개선하기 위해서
Redis Sort를 사용할 수 있음
자릿수의 값 별로 (예) 둘째 자리, 첫째 자리) 정렬을 하므로, 나올 수 있는 값의 최대 사이즈는 9임
(범위 : 0 ~ 9)
-
시간 복잡도 : O(d * (n + b))
- d는 정렬할 숫자의 자릿수, b는 10 (k와 같으나 10으로 고정되어 있다.
- Counting Sort의 경우 : O(n + k) 로 배열의 최댓값 k에 영향을 받음
-
장점 : 문자열, 정수 정렬 가능
-
단점 : 자릿수가 없는 것은 정렬할 수 없음 (부동 소숫점)
중간 결과를 저장할 bucket 공간이 필요함
소스 코드
void countSort(int arr[], int n, int exp) {
int buffer[n];
int i, count[10] = {0};
// exp의 자릿수에 해당하는 count 증가
for (i = 0; i < n; i++) {
count[(arr[i] / exp) % 10]++;
}
// 누적합 구하기
for (i = 1; i < 10; i++) {
count[i] += count[i - 1];
}
// 일반적인 Counting sort 과정
for (i = n-1; i >= 0; i--) {
buffer[count[(arr[i]/exp) % 10] - 1] = arr[i];
count[(arr[i]/exp) % 10]--;
}
for (i = 0; i < n; i++) {
arr[i] = buffer[i];
}
}
void radixsort(int arr[], int n) {
// 최댓값 자리만큼 돌기
int m = getMax(arr, n);
// 최댓값을 나눴을 때, 0이 나오면 모든 숫자가 exp의 아래
for (int exp = 1; m / exp > 0; exp *= 10) {
countSort(arr, n, exp);
}
}
int main() {
int arr[] = { 170, 45, 75, 90, 802, 24, 2, 66 };
int n = sizeof(arr) / sizeof(arr[0]); // 좋은 습관
radixsort(arr, n);
for (int i = 0; i < n; i++) {
count << arr[i] << " ";
}
return 0;
}Question
Q1) 낮은 자릿수부터 정렬하는 이유는?
MSD(Most-Significant-Digit)과 LSD(Least-Significant-Digit)을 비교하라는 질문
MSD는 가장 큰 자릿수부터 Counting sort 하는 것을 의미하고,
LSD는 가장 작은 자릿수부터 Counting sort 하는 것을 의미함 (즉, 둘 다 할 수 있음)
-
LSD의 경우 1600000과 1을 비교할 때, Digit의 개수만큼 따져야하는 단점이 있음
그에 반해 MSD는 마지막 자릿수까지 확인해 볼 필요가 없음 -
LSD는 중간에 정렬 결과를 알 수 없음 (예) 10004와 70002의 비교)
반면, MSD는 중간에 중요한 숫자를 알 수 있으므로 시간을 줄일 수 있음
그러나 정렬이 되었는지 확인하는 과정이 필요하고, 이 때문에 메모리를 더 많이 사용함 -
LSD는 알고리즘이 일관됨 (Branch Free Algorithm)
그러나 MSD는 일관되지 못함 → 따라서 Radis sort는 주로 LSD를 언급함 -
LSD는 자릿수가 정해진 경우, 좀 더 빠를 수 있음
계수 정렬(Counting Sort)
Comparision Sort
N개 원소의 배열이 있을 때, 이를 모두 정렬하는 가짓수는 N!임
따라서 Comparison Sort를 통해 생기는 트리의 말단 노드가 N! 이상의 노드 갯수를 갖기 위해서는 2^h >= N! 를 만족하는 h를 가져야 하고, 이 식을 h > O(nlgn)을 가져야 한다. (h는 트리의 높이. 즉, Comparison sort의 시간 복잡도임)
Counting Sort 과정
시간 복잡도 : O(n + k) → k는 배열에서 등장하는 최댓값
공간 복잡도 : O(k) → k 만큼의 배열을 만들어야 함
각 숫자가 몇 번 등장했는지 counting 한다.
소스 코드
int arr[5]; // [5, 4, 3, 2, 1]
int sorted_arr[5];
// 과정 1 - counting 배열의 사이즈를 최댓값 5가 담기도록 크게 잡기
int counting[6]; // 단점 : counting 배열의 사이즈 범위를 가능한 값의 범위만큼 크게 잡아야 하므로 비효율적이 됨
// 과정 2 - counting 배열의 값을 증가해주기
for (int i = 0; i < arr.length; i++) {
counting[arr[i]]++;
}
// 과정 3 - counting 배열을 누적합으로 만들어주기
for (int i = 1; i < counting.length; i++) {
counting[i] += counting[i - 1];
}
// 과정 4 - 뒤에서부터 배열을 돌면서, 해당하는 값의 인덱스에 값을 넣어주기
for (int i = arr.length - 1; i >= 0; i--) {
counting[arr[i]]--;
sorted-arr[counting[arr[i]]] = arr[i];
}-
정렬하는 숫자가 특정한 범위 내에 있을 때 사용
- Suffix Array를 얻을 때, 시간복잡도 O(nlgn)으로 얻을 수 있음
-
장점 : O(n)의 시간 복잡도
-
단점 : 배열 사이즈 N만큼 돌 때, 증가시켜주는 Counting 배열의 크기가 큼 (메모리 낭비가 심함)
이분 탐색(Binary Search)
탐색 범위를 두 부분으로 분할하면서 찾는 방식
처음부터 끝까지 돌면서 탐색하는 것보다 훨씬 빠른 장점을 지님
* 시간복잡도
전체 탐색 : 0(N)
이분 탐색 : 0(logN)진행 순서
- 우선 정렬을 해야 함
- left와 right로 mid 값 설정
- mid와 내가 구하고자 하는 값을 비교
- 구할 값이 mid보다 높으면: left = mid + 1
구할 값이 mid보다 낮으면: right = mid - 1 - left > right가 될 때까지 계속 반복
소스 코드
public static int solution(int[] arr, int M) { // arr 배열에서 M을 찾기
Arrays.sort(arr); // 정렬
int start = 0;
int end = arr.lenght - 1;
int mid = 0;
while (start <= end) {
mid = (start + end) / 2;
if(M == arr[mid]) {
return mid;
} else if (arr[mid] < M) {
start = mid + 1;
} else if (M < arr[mid]) {
end = mid - 1;
}
}
throw new NoSuchElementException("타겟이 존재하지 않음");
}해시 테이블(Hash Table)
알고리즘 문제를 풀기 위해 필수적으로 알아야 할 개념
브루트 포스(완전 탐색)로는 시간초과에 빠지게 되는 문제에서는 해시를 적용시켜야 한다.
N(1~100000)의 값만큼 문자열이 입력된다.
처음 입력되는 문자열은 "OK", 들어온 적이 있던 문자열은 "문자열+index"로 출력하면 된다.
ex)
Input
5
abcd
abc
abcd
abcd
abOutput
OK
OK
abcd1
abcd2
OK똑같은 문자열이 들어왔는지 체크해보고, 들어온 문자열은 인덱스 번호를 부여해서 출력해주면 된다.
하지만, 현재 N값은 최대 10만이다. 브루트 포스로 접근하면 N^2이 되므로 100억번의 연산이 필요해서 시간초과에 빠질 것이다.
따라서 해시 테이블을 이용해 문제를 해결해야 한다.
입력된 문자열 값을 해시 키로 변환시켜 저장하면서 최대한 시간으 줄여 나가도록 구현해야 한다.
해시 테이블 구현
해시 테이블은 탐색을 최대한 줄여주기 위해, input에 대한 key 값을 얻어내서 관리하는 방식이다.
현재 최대 N값은 10만이다. 이차원 배열로 1000/100으로 나누어 관리하면 더 효율적일 것이다.
충돌 값이 들어오는 것을 감안하여 두 번째 배열 값에 4를 곱해서 선언한다.
key 값을 얻어서 저장할 때, 서로 다른 문자열이라도 같은 key 값으로 들어올 수 있다.
(이것이 해시에 대한 일노을 배울 때 나오는 충돌 현상이다.)
충돌이 일어나는 것을 최대한 피해야 하지만, 무조건 피할 수 있다는 보장은 없다. 그래서 두 번째 배열 값을 조금 넉넉히 선언해두는 것이다.이를 고려하여 final 값으로 선언한 해시 값은 아래와 같다.
static final int HASH_SIZE = 1000;
static final int HASH_LEN = 400;
static final int HASH_VAL = 17; // 소수로 할 것HASH_VAL 값은 우리가 input 값을 받았을 때 해당하는 key 값을 얻기 위해 활용한다.
최대한 input 값들마다 key 값이 겹치지 않게 하기 위해서는 소수로 선언해야 한다. (그래서 보통 17, 19, 23으로 선언)
key 값을 얻는 메소드 구현 방법은 아래와 같다.
public static int getHashKey(String str) {
int key = 0;
for (int i =0; i < str.length(); i++) {
key = (key * HASH_VAL) + str.charAt(i);
}
if(key < 0) key = -key; // 만약 key 값이 음수면 양수로 바꿔주기
return key % HASH_SIZE;
}input 값을 매개변수로 받는다. 만약 string 값으로 들어온다고 가정할 때,
string 값의 한 글자(character)마다 int형 값을 얻어낼 수 있다.
이를 활용하여 string 값의 length 만큼 반복문을 돌면서,
그 문자열만의 key 값을 만들어내는 것이 가능하다.
이 key 값을 배열 인덱스로 활용할 것이기 때문에 key 값이 음수이면 안 된다.
만약 key 값의 결과가 음수이면 양수로 바꿔주는 조건문이 필요하다.
마지막으로, return 값으로 key를 HASH_SIZE로 나눈 나머지 값을 얻어야 한다.
현재 계산된 key 값이 매우 크기 때문에 HASH_SIZE로 나눈 나머지 값으로 key를 활용한다.
위의 과정을 통해 input으로 받은 string 값의 key 값을 얻을 수 있다.
해당 key 값의 배열에서 값이 들어온 적이 있는지 확인하는 과정이 필요하다.
(모든 곳을 탐색할 필요 없음. 이 key에 해당하는 배열만 확인하면 된다.)
static int[][] data = new int[HASH_SIZE][HASH_LEN];
string str = "apple";
int key = getHashKey(str); // apple에 대한 key 값을 얻음
data[key][index]; // 이 곳에 apple을 저장해서 관리하면 찾는 시간을 줄일 수 있음여기서 HASH_SIZE가 1000이고, 우리가 key 값을 리턴할 때 100으로 나눈 나머지로 저장했기 때문에 이 안에서만 key 값이 들어오게 된다.
ArrayList로 2차원 배열을 관리하면 구현이 간편하다.
하지만 라이브러리를 사용하지 못 하는 경우, 배열로 선언해서 추가해나가야 한다.
또한, ArrayList의 활용보다는 배열을 사용하는 것이 시간을 단축시킬 수 있다.
이제 해당 key 배열에서 apple이 들어온 적이 있는 지 체크해야 한다.
데이터의 수가 많으면 key 배열 안에서 다른 문자열이라도 같은 key로 저장되는 값들이 존재할 수 있으므로, 해당 key 배열을 돌면서 apple과 일치하는 문자열이 있는지 확인하는 과정이 필요하다.
따라서 key 값을 매개변수로 넣고, 문자열이 들어왔던 적이 있는지 체크하는 함수를 구현해야 한다.
public static int checking(int key) {
int len = length[key]; // 현재 key에 담긴 수 (같은 key 값으로 들어오는 문자열이 있을 수 있다.)
if(len != 0) { // 이미 들어온 적이 있음
for (int i = 0; i < len; i++) { // 이미 들어온 문자열이 해당 key 배열에 있는지 확인
if(str.equals(s_data[key][i])) {
data[key][i]++;
return data[key][i];
}
}
}
// 들어온 적이 없으면 해당 key 배열에서 문자열을 저장하고 길이를 1 늘리기
s_data[key][length[key]++] = str;
return - 1; // 처음으로 들어가는 경우 -1을 리턴
}length[] 배열은 HASH_SIZE만큼 선언된 것으로
key 값을 얻은 후, 처음 들어온 문자열일 때마다 숫자를 1씩 늘려
해당 key 배열에 몇 개의 데이터가 저장되어 있는지 확인하는 공간이다.
출력해야 하는 조건
처음 들어온 것은 "OK", 다시 들어온 것은 "data + 들어온 수" 이다.
-
"OK"로 출력해야 하는 조건
해당 key의 배열 length가 0일 때는 무조건 처음 들어오는 데이터이다.
또한 1 이상일 때, 그 key 배열 안에서 만약 apple을 찾지 못했다면 이 또한 처음 들어오는 데이터이다. -
"data + 들어온 수"로 출력해야 하는 조건
만약 1 이상일 때, key 배열에서 apple 값을 찾았다면
이제 "apple + 들어온 수"를 출력하도록 구현해야 한다.
그래서 3개의 배열을 선언해서 활용한다.
static int[][] data = new int[HASH_SIZE][HASH_LEN];
static int[] length = new int[HASH_SIZE];
static String[][] s_data = new String[HASH_SIZE][HASH_LEN];- data[][] 배열 : input으로 받는 문자열이 들어온 수를 저장하는 곳
- length[][] 배열 : key 값마다 들어온 수를 저장하는 곳
- s_data[][] 배열 : input으로 받은 문자열을 저장하는 곳
진행 과정을 설명하면 다음과 같다.
- apple → banana → abc → abc 순으로 입력된다.
- apple과 abc의 key 값은 5로 같다고 가정한다.
1. apple이 들어오고, key 값을 얻으니 5가 나옴
length[5]는 0이므로 처음 들어온 데이터임
→ length[5]++ 하고 "OK" 출력
2. banana가 들어오고, key 값을 얻으니 3이 나옴
length[3]은 0이므로 처음 들어온 데이터임
→ length[3]++ 하고 "OK" 출력
★ 중요!
3. abc가 들어오고, key 값을 얻으니 5가 나옴
length[5]는 0이 아님. 해당 key 값에 누가 들어온 적이 있음
length[5]만큼 반복문을 돌면서 s_data[key]의 배열과 abc가 일치하는 값이 있는지 확인
현재 length[5]는 1이고, s_data[key][0] = "apple"이므로 일치하는 값이 없음
→ length[5]를 1 증가시키고, s_data[key][length[5]]에 abc를 넣고 "OK" 출력
★ 중요!
4. abc가 들어오고, key 값을 얻으니 5가 나옴
length[5] = 2임. s_data[key]를 2만큼 반복문을 돌면서 abc가 있는지 찾음
1번째 인덱스 값에는 apple이 저장되어 있고, 2번째 인덱스 값에서 abc가 일치
따라서 해당 data[key][index] 값을 1 증가시키고, 이 값을 return
→ 메인 함수에서 input으로 들어온 abc 값과 return 값으로 나온 1을 붙여서 출력 (abc1)전체 소스코드
package CodeForces;
import java.io.BufferReader;
import java.io.InputStreamReader;
public class Solution {
static final int HASH_SIZE = 1000;
static final int HASH_LEN = 400;
static final int HASH_VAL = 17; // 소수로 할 것
static int[][] data = new int[HASH_SIZE][HASH_LEN];
static int[] length = new int[HASH_SIZE];
static String[][] s_data = new String[HASH_SIZE][HASH_LEN];
static String str;
static int N;
public static void main(String[] args) throws Exception {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sb = new StringBuilder();
N = Integer.parseInt(br.readLIne()); // 입력 수 (1~100000)
for (int i = 0; i < N; i++) {
str = br.readLine();
int key = getHashKey(str);
int cnt = checking(key);
if(cnt != -1) { // 이미 들어왔던 문자열
sb.append(str).append(cnt).append("\n");
}
else sb.append("OK").append("\n");
}
System.out.println(sb.toString());
}
public static int getHashKey(String str) {
int key = 0;
for (int i = 0; i < str.length(); i++) {
key = (key * HASH_VAL) + str.charAt(i) + HASH_VAL;
}
if(key < 0 ) key = -key; // 만약 key 값이 음수이면 양수로 바꿔주기
return key % HASH_SIZE;
}
public static int checking(int key) {
int len = length[key]; // 현재 key에 담긴 수 (같은 key 값으로 들어오는 문자열이 있을 수 있음)
if(len != 0) { // 이미 들어온 적이 있음
for (int i = 0; i < len; i++) { // 이미 들어온 문자열이 해당 key 배열에 있는지 확인
if(str.equals(s_data[key][i])) {
data[key][i]++;
return data[key][i];
}
}
}
// 들어온 적이 없으면 해당 key 배열에서 문자열을 저장하고 길이를 1 늘리기
s_data[key][length[key]++] = str;
return -1; // 처음으로 들어가는 경우 -1을 리턴
}
}DFS & BFS
그래프 알고리즘으로, 경로를 찾는 문제를 풀 때 상황에 맞게 DFS와 BFS를 활용한다.
DFS
루트 노드 혹은 임의 노드에서 다음 브랜치로 넘어가기 전에, 해당 브랜치는 모두 탐색하는 방법
스택 or 재귀함수를 통해 구현한다.
- 모든 경로를 방문해야 할 경우, 사용에 적합

시간 복잡도
- 인접 행렬 : O(V^2)
- 인접 리스트 : O(V+E)
V는 접점, E는 간선을 뜻한다.
소스 코드
#include <stdio.h>
int map[1001][1001], dfs[1001];
void init(int *, int size);
void DFS(int v, int N) {
dfs[v] = 1;
printf("%d", v);
for (int i = 1; i <= N; i++) {
if (map[v][i] == 1 && dfs[i] == 0) {
DFS(i, N);
}
}
}
int main(void) {
init(map, sizeof(map) / 4);
init(dfs, sizeof(dfs) / 4);
int N, M, V;
scanf("%d%d%d", &N, &M, &V);
for (int i = 0; i < M; i++)
{
int start, end;
scanf("%d%d", &start, &end);
map[start][end] = 1;
map[end][start] = 1;
}
DFS(V, N);
return 0;
}
void init(int * arr, int size) {
for (int i = 0; i < size; i++)
{
arr[i] = 0;
}
}BFS
루트 노드 또는 임의 노드에서 인접한 노드부터 먼저 탐색하는 방법
큐를 통해 구현한다. (해당 노드의 주변부터 탐색해야 하므로)
- 최소 비용 (모든 곳을 탐색하는 것보다 최소 비용이 우선일 때)에 적합

시간 복잡도
- 인접 행렬 : O(V^2)
- 인접 리스트 : O(V+E)
소스 코드
#include <stdio.h>
int map[1001][1001], bfs[1001];
int queue[1001];
void init(int *, int size);
void BFS(int v, int N) {
int front = 0, rear = 0;
int pop;
printf("%d ", v);
queue[rear++] = v;
bfs[v] = 1;
while (front < rear) {
pop = queue[front++];
for (int i = 1; i <= N; i++) {
if (map[pop][i] == 1 && bfs[i] == 0) {
printf("%d ", i);
queue[rear++] = i;
bfs[i] = 1;
}
}
}
returnl
}
int main(void) {
init(map, sizeof(map) / 4);
init(bfs, sizeof(bfs) / 4);
init(queue, sizeof(queue) / 4);
int N, M, V;
scanf("%d%d%d", &N, &M, &V);
for (int i = 0; i < M; i++)
{
int start, end;
scanf("%d%d", &start, &end);
map[start][end] = 1;
map[end][start] = 1;
}
BFS(V, N);
return 0;
}
void init(int * arr, int size) {
for (int i = 0; i < size; i++)
{
arr[i] = 0;
}
}최장 증가 수열(LIS)
최장 증가 수열 : 가장 긴 증가하는 부분 수열
[ 7, 2, 3, 8, 4, 5 ] → 해당 배열에서는 [2,3,4,5]가 LIS로 답은 4
구현 방법 (시간복잡도)
- DP : O(N^2)
- Lower Bound : O(NlogN)
DP 활용 코드
int arr[] = {7, 2, 3, 8, 4, 5};
int dp[] = new int[arr.length]; // LIS 저장 배열
for (int i = 1; i < dp.length; i++) {
for (int j = i-1; j >= 0; j--) {
if(arr[i] > arr[j]) {
dp[i] = (dp[i] < dp[j]+1) ? dp[j]=1 : dp[i];
}
}
}
for (int i = 0; i < dp.length; i++) {
if(max < dp[i]) max = dp[i];
}
// 저장된 dp 배열 값 : [0, 0, 1, 2, 2, 3]
// LIS : dp 배열에 저장된 값 중 최댓값 + 1하지만 N^2으로 해결할 수 없는 문제라면?
(ex. 배열의 길이가 최대 10만일 때)
→ 이 때는 Lower Bound를 활용한 LIS 구현을 진행해야 한다.
최소 공통 조상(LCA)
최소 공통 조상(Lowest Common Ancestor)을 찾는 알고리즘
→ 두 정점이 만나는 최초 부모의 정점을 찾는 것!
트리 형식이 아래와 같이 주어졌다고 할 때
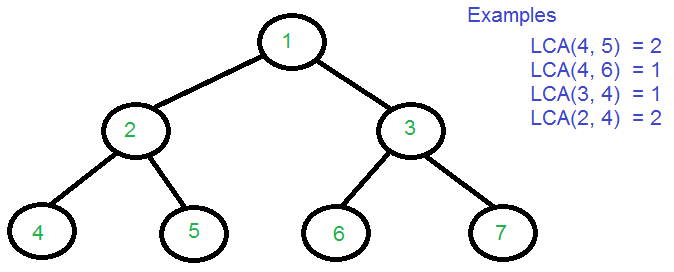
4와 5의 LCA는? → 4와 5의 첫 부모 정점은 '2'
4와 6의 LCA는? → 첫 부모 정점은 root인 '1'
찾는 방법은?
해당 정점의 depth와 parent를 저장해두는 방식이다. 현재 그림에서의 depth는 다음과 같을 것이다.
[depth : 정점]
0 → 1 (root 정점)
1 → 2, 3
2 → 4, 5, 6, 7parent는 정점마다 가지는 부모 정점을 저장해둔다. 위의 예시에서 저장된 parent 배열은 다음과 같다.
// 1 ~ 7번 정점 (root는 부모가 없기 때문에 0)
int parent[] = {0, 1, 1, 2, 2, 3, 3}이제 이 두 배열을 활용해서 두 정점이 주어졌을 때, LCA를 찾을 수 있다.
과정은 다음과 같다.
// 두 정점의 depth 확인하기
while(true) {
if(depth가 일치)
if(두 정점의 parent 일치?) LCA 찾음(종료)
else 두 정점을 자신의 parent 정점 값으로 변경
else // depth 불일치
depth가 더 깊은 정점을 해당 정점의 parent 정점으로 변경(depth가 감소됨)
}트리 문제에서 공통 조상을 찾아야하는 문제나, 정점과 정점 사이의 이동거리(또는 방문경로)를 저장해야 할 경우에 사용한다.
동적 계획법(Dynamic Programming)
복잡한 문제를 간단한 여러 개의 문제로 나누어 푸는 방법
흔히 말하는 DP가 바로 이 '동적 계획법' 이다.
한 가지 문제에 대해서, 단 한 번만 풀도록 만들어주는 알고리즘이다.
즉, 똑같은 연산을 반복하지 않도록 만들어준다.
실행 시간을 줄이기 위해 많이 이용되는 수학적 접근 방식의 알고리즘이라고 할 수 있다.
동적 계획법은 Optimal Substructure 에서 효과를 발휘한다.
- Optimal Substructure : 답을 구하기 위해 이미 했던 똑같은 계산을 계속 반복하는 문제 구조
접근 방식
커다란 문제를 쉽게 해결하기 위해 작게 쪼개서 해결하는 방법인 분할 정복과 매우 유사하다.
하지만 간단한 문제로 만드는 과정에서 중복 여부에 대한 차이점이 존재한다.
즉, 동적 계획법은 간단한 작은 문제들 속에서 '계속 반복되는 연산'을 활용하여 빠르게 풀 수 있는 것이 핵심이다.
조건
- 작은 문제에서 반복이 일어남
- 같은 문제는 항상 정답이 같음
이 두 가지 조건이 충족한다면, 동적 계획법을 이용하여 문제를 풀 수 있다.
같은 문제가 항상 정답이 같고, 반복적으로 일어난다는 점을 활용해 메모이제이션(Memoization)으로 큰 문제를 해결해나가는 것이다.
- 메모이제이션(Memoization) : 한 번 계산한 문제는 다시 계산하지 않도록 저장해두고 활용하는 방식
피보나치 수열에서 재귀를 활용하여 문제를 풀 경우, 같은 연산을 계속 반복함을 알 수 있다.
이 때, 메모이제이션을 통해 같은 작업을 되풀이 하지 않도록 구현하면 효율적이다.
fibonacci(5) = fibonacci(4) + fibonacci(3)
fibonacci(4) = fibonacci(3) + fibonacci(2)
fibonacci(3) = fibonacci(2) + fibonacci(1)
이처럼 같은 연산이 계속 반복적으로 이용될 때, 메모이제이션을 활용하여 값을 미리 저장해두면 효율적임구현 방식
- Bottom-up : 작은 문제부터 차근차근 구하는 방법
- Top-down : 큰 문제를 풀다가 풀리지 않는 작은 문제가 있다면 그 때 해결하는 방법 (재귀 방식)
Bottom-up은 해결이 용이하지만, 가독성이 떨어짐
Top-down은 가독성이 좋지만, 코드 작성이 어려움
동적 계획법으로 문제를 풀 때는, 우선 작은 문제부터 해결해 나가는 것이 좋다.
작은 문제들을 풀어나가다 보면 이전에 해결했던 더 작은 문제들이 활용되는 것을 확인할 수 있다.
이에 대한 규칙을 찾았을 때, 점화식을 도출해내어 동적 계획법을 적용시킨다.
다익스트라(Dikstra) 알고리즘
DP를 활용한 최단 경로 탐색 알고리즘
다익스트라 알고리즘은 특정한 정점에서 다른 모든 정점으로 가는 최단 경로를 기록한다.
여기서 DP가 적용되는 이유는, 굳이 한 번 최단 거리를 구한 곳은 다시 구할 필요가 없기 때문이다.
이를 활용해 정점에서 정점까지 간선을 따라 이동할 때 최단 거리를 효율적으로 구할 수 있다.
다익스트라를 구현하기 위해 두 가지를 저장해야 한다.
- 해당 정점까지의 최단 거리를 저장
- 정점을 방문했는지 저장
시작 정점으로부터 정점들의 최단 거리를 저장하는 배열과 방문 여부를 저장하는 것이다.
다익스트라의 알고리즘 순서는 다음과 같다.
- 최단 거리 값은 무한대 값으로 초기화한다.
for(int i = 1; i <= n; i++) {
distance[i] = Integer.MAX_VALUE;
}- 시작 정점의 최단 거리는 0이다. 그리고 시작 정점을 방문 처리한다.
distance[start] = 0;
visited[start] = true;- 시작 정점과 연결된 정점들의 최단 거리 값을 갱신한다.
for(int i = 1; i <=n; i++) {
if(!visited[i] && map[start][i] != 0) {
distance[i] = map[start][i];
}
}- 방문하지 않은 정점 중 최단 거리가 최소인 정점을 찾는다.
int min = Integer.MAX_VALUE;
int midx = -1;
for(int i = 1; i <=n; i++) {
if(!visited[i] && distance[i] != Integer.MAX_VALUE) {
if(distance[i] < min) {
min = distance[i];
midx = i;
}
}
}- 찾은 정점을 방문 체크로 변경 후, 해당 정점과 연결된 방문하지 않은 정점의 최단 거리 값을 갱신한다.
visited[midx] = true;
for(int i = 1; i <= n; i++) {
if(!visited[i] > distance[midx] + map[midx][i]) {
distance[i] = distance[midx] + map[midx][i];
}
}
} - 모든 정점을 방문할 때까지 4~5번을 반복한다.
다익스트라 적용 시 알아야 할 점
- 인접 행렬로 구현하면 시간 복잡도는 O(N^2) 이다.
- 인접 리스트로 구현하면 시간 복잡도는 O(N*logN) 이다.
선형 탐색으로 시간 초과가 발생하는 문제는 인접 리스트로 접근해야 한다. (우선순위 큐)
- 간선의 값이 양수일 때만 가능하다.
비트마스크(BitMask)
집합의 요소들의 구성 여부를 표현할 때 유용한 테크닉
비트마스크를 사용하는 이유
- DP나 순열 등 배열 활용만으로 해결할 수 없는 문제
- 작은 메모리와 빠른 수행 시간으로 해결이 가능 (But 원소의 수가 많지 않아야 함)
- 집합을 배열의 인덱스로 표현할 수 있음
- 코드가 간결해짐
비트(Bit)란?
컴퓨터에서 사용되는 데이터의 최소 단위 (0과 1)
2진법을 생각할 것!
우리가 흔히 사용하는 10진수를 2진수로 바꾸면?
9(10진수) → 1001(2진수)
비트마스킹 활용해보기
0과 1로 flag 활용하기
[1, 2, 3, 4, 5] 라는 집합이 있다고 가정할 때
여기서 임의로 몇 개를 골라 뽑아서 확인을 해야하는 상황이다. (즉, 부분집합을 의미)
{1}, {2}, ... , {1,2}, ... , {1,2,5}, ... , {1,2,3,4,5}물론, 간단히 for문을 돌려가며 배열에 저장하여 경우의 수를 구할 수 있다.
하지만 비트마스킹을 활용하면, 각 요소를 인덱스처럼 표현하여 효율적인 접근이 가능하다.
[1,2,3,4,5] → 11111
[2,3,4,5] → 11110
[1,2,5] → 10011
[2] → 00010집합의 i 번째 요소가 존재하면 1, 그렇지 않으면 0을 의미하는 것이다.
이러한 2진수는 다시 10진수로 변환이 가능하다.
11111은 10진수로 31이므로, 부분집합을 정수를 통해 나타내는 것이 가능하다는 것을 알 수 있다.
31은 [1,2,3,4,5] 전체에 해당하는 부분집합에 해당한다는 의미!
이로써, 해당 부분집합에 i 를 추가하고 싶을 때, i 번째 비트를 1로만 바꿔주면 표현이 가능해진다.
이런 행위는 비트 연산을 통해 제어가 가능하다.
비트 연산
AND, OR, XOR, NOT, SHIFT
- AND(&) : 대응하는 두 비트가 모두 1일 때, 1을 반환
- OR(|) : 대응하는 두 비트 중 모두 1이거나 하나라도 1일 때, 1을 반환
- XOR(^) : 대응하는 두 비트가 서로 다를 때, 1을 반환
- NOT(~) : 비트 값을 반전하여 반환
- SHIFT(>>, <<) : 왼쪽 혹은 오른쪽으로 비트를 옮겨 반환
- 왼쪽 시프트 :
A * 2^B - 오른쪽 시프트 :
A / 2^B
- 왼쪽 시프트 :
[왼 쪽] 0001 → 0010 → 0100 → 1000 : 1 → 2 → 4 → 8
[오른쪽] 1000 → 0100 → 0010 → 0001 : 8 → 4 → 2 → 1비트 연산연습 문제 : 백준 12813
백준 12813번 - 구현 코드
#include <stdio.h>
int main(void) {
unsigned char A[100001] = { 0, };
unsigned char B[100001] = { 0, };
unsigned char ret[100001] = { 0, };
int i;
scanf("%s %s", &A, &B);
// AND
for (i = 0; i < 100000; i++)
ret[i] = A[i] & B[i];
puts(ret);
// OR
for (i = 0; i < 100000; i++)
ret[i] = A[i] | B[i];
puts(ret);
// XOR
for (i = 0; i < 100000; i++)
ret[i] = A[i] != B[i] ? '1' : '0';
puts(ret);
// ~A
for (i = 0; i < 100000; i++)
ret[i] = A[i] == '1' ? '0' : '1';
puts(ret);
// ~B
for (i = 0; i < 100000; i++)
ret[i] = B[i] == '1' ? '0' : '1';
puts(ret);
return 0;
}다시 비트마스크로 돌아와 비트 연산을 활용해보자
크게 삽입, 삭제, 조회로 나누어 진다.
1. 삽입
현재 이진수로 10101로 표현되고 있을 때, i 번째 비트 값을 1로 변경하려고 한다.
i = 3일 때, 변경 후에는 11101이 나와야 한다.
이 때는 OR 연산을 활용한다.
10101 | 1 << 31 << 3은 1000이므로, 10101 | 01000이 되어 11101을 만들 수 있다.
2. 삭제
반대로 0으로 변경하려면, AND 연산과 NOT 연산을 활용한다.
11101 & ~1 << 3~1 << 3은 10111이므로, 11101 & 10111이 되어 10101을 만들 수 있다.
3. 조회
i번째 비트가 무슨 값인지 알려면, AND 연산을 활용한다.
10101 & 1 << i
3번째 비트 값 : 10101 & (1 << 3) = 10101 & 01000 → 0
4번째 비트 값 : 10101 & (1 << 4) = 10101 & 10000 → 10000이처럼 결과값이 0이 나왔을 때는 i 번째 비트 값이 0인 것을 파악할 수 있다. (반대로 0이 아니면 무조건 1인 것)
이러한 방법을 활용하여 문제를 해결하는 것이 비트마스크다.
비트마스크연습 문제 : 백준 2098
해당 문제는 모든 도시를 한 번만 방문하면서 다시 시작점으로 돌아오는 최소 거리 비용을 구해야 한다.
완전탐색으로 답을 구할 수는 있지만, N이 최대 16이기 때문에 16!으로 시간초과에 빠지게 된다.
따라서 DP를 활용해야 하며, 방문 여부를 배열로 관리하기 힘드므로 비트마스크를 활용하기 좋은 문제이다.
