
- 정렬 알고리즘이란?
-
원소들을 번호 순이나 사전 순서와 같이 특정한 기준을 적용해 순서대로 열거하는 알고리즘
-
대표적인 정렬 알고리즘으로는
버블 정렬,선택 정렬,삽입 정렬,병합 정렬,퀵 정렬등이 있고 다른 정렬로는카운팅 정렬,파이썬 메소드에 의한 정렬이 있다.
- 버블 정렬(Bubble Sort)
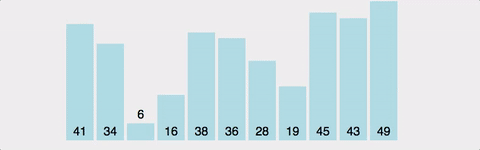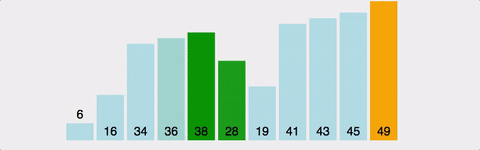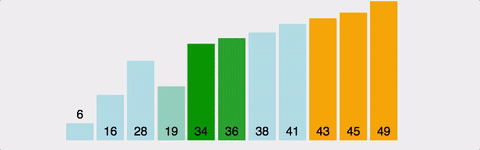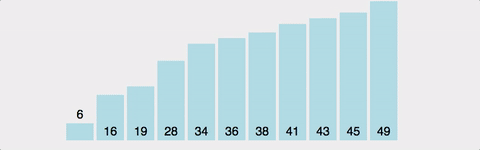
- 버블 정렬은 서로 인접한 두 원소의 크기를 비교하여 조건에 맞지 않으면 원소의 자리를 교환하면서 정렬하는 알고리즘이다.
- 1회전에 첫 번째 원소와 두 번째 원소를 비교하면서 첫 번째 원소가 두 번째 원소보다 크다면 서로 교환한다.(오름차순으로 정렬한다는 전제 하에서) 그 다음 두 번째 원소가 세 번째 원소보다 크다면 서로 교환한다.
length - 1번째 원소와length번째 원소를 비교하여 조건을 만족하면 원소를 교환한다.- 위에 설명한 것처럼
length - 1번째까지 인접한 원소를 교환하는 과정을 반복했으면 다시 첫 번째 원소부터 2회전 정렬을 시작한다.- 모든 원소가 정렬이 될 때까지 n회전 정렬을 수행한다.
버블 정렬(Bubble Sort)의 시간복잡도는O(N^2)이다.
- 버블 정렬 알고리즘 구현 코드
def bubble_sort(array):
# 배열의 길이가 N이라고 할 때 수행되는 횟수는 N-1번이다.
for i in range(len(array) - 1, 0, -1):
for j in range(i):
if array[j] > array[j+1]:
# 인접한 원소 간의 교환을 수행
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
- 본인이 직접 짤 수 있는가? → ✅
- 위의 버블 정렬 알고리즘은 한계가 존재한다.
- 버블 정렬은 가장 큰 값이 맨 마지막 원소로 이동하게 되고 그 다음으로 큰 원소는 다음 패스 때부터 순차적으로 하나씩 이동하게 된다.
- 정렬이 수행되지 않은 리스트의 길이가 n이라면 일반적으로 수행되는 Pass 횟수는 (n-1)번이 된다.
- 1회의 패스 과정에서 인접한 원소 간의 교환이 발생하는데 위의 코드는 정렬이 전부 수행이 된 상황이어도 계속 코드가 동작한다는 점에서 비효율적인 코드라고 할 수 있다.
- 따라서, 위의 코드에서 일부를 개선하여 버블 정렬을 최적화할 수 있는데 최적화 코드는 아래와 같다.
def bubble_sort(array):
for i in range(len(array) - 1, 0, -1):
swapped = False
for j in range(i):
if array[j] > array[j+1]:
# 인접한 원소 간의 교환을 수행
array[j], array[j+1] = array[j+1], array[j]
swapped = True
# 원소 간의 교환이 이루어지지 않았다면?(즉, 모든 원소의 정렬이 정상적으로 수행된 경우)
if not swapped:
break
- 인접한 원소 간의 교환이 이루어지지 않았다면 결국 배열이 정렬이 완료된 상태라는 것을 알 수 있으므로 boolean 자료형을 이용해서 버블 정렬 성능을 개선할 수 있다.
- 선택 정렬(Selection Sort)
- 선택 정렬은 정렬되지 않은 데이터들에 대해 가장 작은 데이터를 찾아 가장 맨 앞에 위치한 원소와 교체하고 맨 처음 위치를 제외한 나머지 리스트를 같은 방법으로 교체하는 정렬 알고리즘이다.
선택 정렬(Selection Sort)의 시간복잡도는O(N^2)이다.
- 선택 정렬 알고리즘 구현 코드
def selection_sort(array):
for i in range(len(array) - 1):
# 맨 첫 번째 원소의 인덱스
min_index = i
for j in range(i+1, len(array)):
# 이후에 나오는 가장 작은 데이터를 찾는다.
if array[j] < array[min_index]:
min_index = j
# 맨 첫 번째 원소와 가장 작은 원소를 교환
array[i], array[min_index] = array[min_index], array[i]
- 본인이 직접 짤 수 있는가? → ✅
- 삽입 정렬(Insertion Sort)

- 삽입 정렬은 한 번에 하나의 항목을 배열의 정렬된 부분에 삽입하면서 정렬을 수행하는 알고리즘이다.
삽입 정렬(Insertion Sort)의 시간복잡도는O(N^2)이다.
- 삽입 정렬 알고리즘 구현 코드
def insertion_sort(array):
for i in range(1, len(array)):
for j in range(i, 0, -1):
if array[j-1] > array[j]:
array[j-1], array[j] = array[j], array[j-1]
else:
break
- 본인이 직접 짤 수 있는가? → ✅
- 퀵 정렬(Quick Sort)
- 기준 데이터를 설정하고 그 기준보다 큰 데이터와 작은 데이터의 위치를 바꾸는 방법이다.
- 이 때, 기준이 되는 데이터를
pivot라고 한다. 일반적으로 가장 많이 사용되는 것은 주어진 array의 첫 번째 요소이다.- pivot을 기준으로 pivot보다 작은 데이터와 pivot보다 큰 데이터로 구분한다.
- 퀵 정렬의 평균 시간복잡도는
O(N log N)이다. 하지만 최악의 경우O(N^2)의 시간복잡도를 가지는데 이는 피벗을 어떻게 선택하느냐에 따라 달라진다.
- 퀵 정렬 알고리즘 구현 코드
def quick_sort(array):
if len(array) <= 1:
return arr
pivot = array[0]
tail = array[1:]
left_side = [x for x in tail if x <= pivot] # pivot보다 작거나 같은 데이터
right_side = [x for x in tail if x > pivot] # pivot보다 큰 데이터
return quick_sort(left_side) + [pivot] + quick_sort(right_side)- 시간적인 측면에서 조금 비효율적이지만 그래도 한 번은 다루고 넘어가는 것이 좋을 것 같아서 이렇게 포스팅을 했다.
def quick_sort(array, start, end):
if start >= end:
return
pivot = start
# 왼쪽에서부터는 피벗보다 큰 값, 오른쪽에서부터는 피벗보다 작은 값
left, right = start + 1, end
while left <= right:
# 피벗보다 큰 데이터를 찾을 때까지 반복함
while left <= end and array[left] <= array[pivot]:
left += 1
# 피벗보다 작은 데이터를 찾을 때까지 반복함
while right > start and array[right] >= array[pivot]
right -= 1
# 엇갈린 경우 : 피벗 - 작은 데이터 교환
if left > right:
array[right], array[pivot] = array[pivot], array[right]
# 엇갈리지 않은 경우 : 작은 데이터 - 큰 데이터 교환
else:
array[right], array[left] = array[left], array[right]
# 분할 이후 피벗 기준 왼쪽 부분과 오른쪽 부분에서 각각 퀵 정렬을 수행
quick_sort(array, start, right - 1)
quick_sort(array, right + 1, end)[알고리즘 동작 과정]
①. 피벗을 배열의 가장 첫 번째 원소로 지정한다. 피벗보다 큰 값을 왼쪽에서부터 찾아서 선택하고 피벗보다 작은 값을 오른쪽에서부터 찾아서 선택한다.
②. 찾은 두 위치의 원소를 교환한다.
③. 위의 ①, ②번 과정을 반복하다가 만약 ①번 과정을 다시 반복하다가 피벗보다 큰 값과 피벗보다 작은 값의 위치가 엇갈린 경우 피벗과 작은 데이터의 위치를 서로 변경한다.
- 병합 정렬(Merge Sort)

- 분할(Divide) : 입력 리스트를 같은 크기의 2개의 부분 리스트로 분할한다.
- 정복(Conquer) : 부분 리스트를 정렬한다.
- 결합(Combine) : 정렬된 부분 리스트를 하나로 통합한다.
- 병합 정렬의 시간복잡도는
O(N log N)이다.
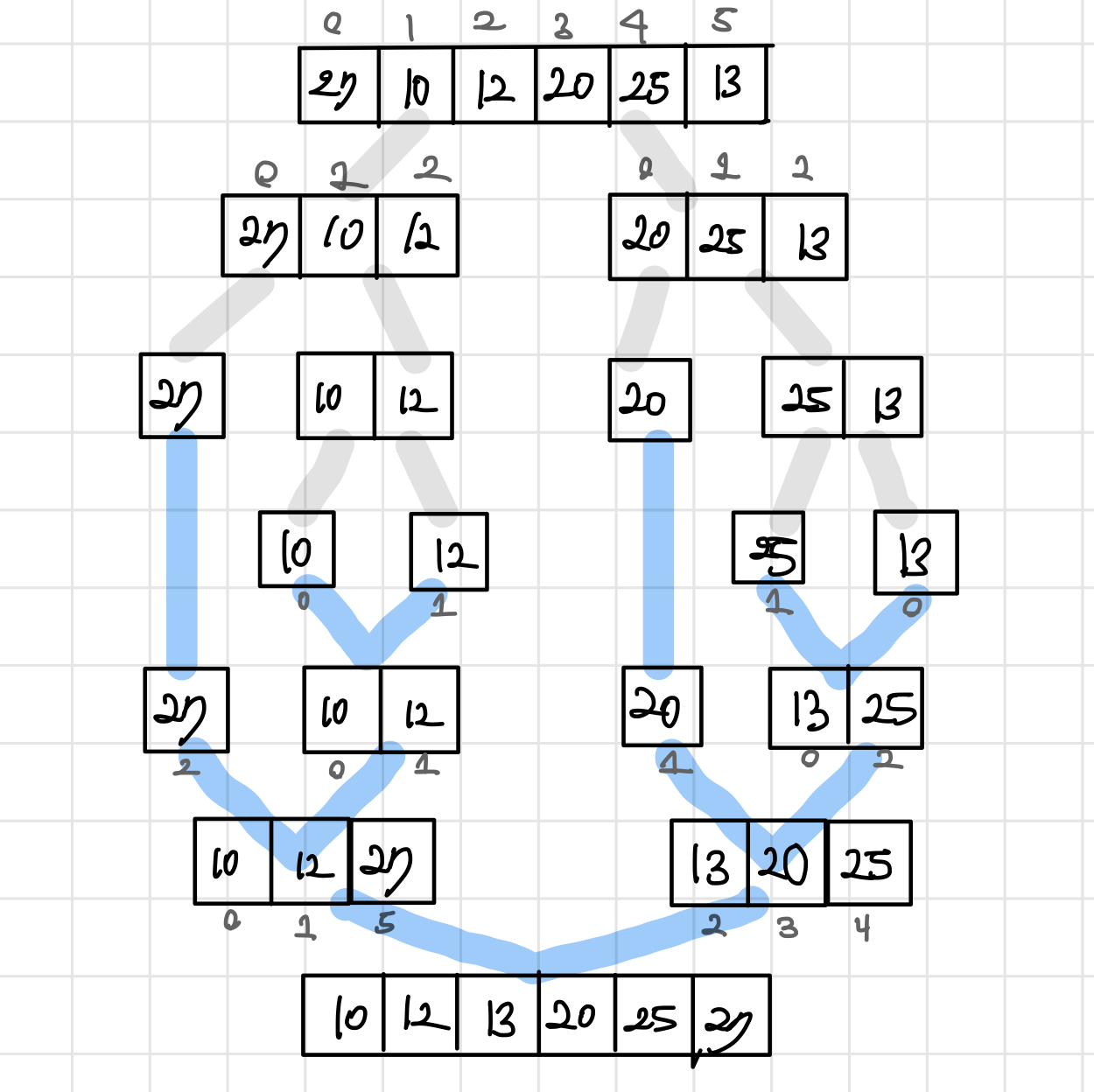
# Divide and Conquer algorithm
# Breaks down problem into multiple subproblems recursively until they become simple to solve
# Solutions are combined to original problem
# O(N log N)의 시간복잡도
# 병합 정렬 : 재귀, 분할 정복 알고리즘
# General Principle
# 1. Split array in half(배열을 반으로 쪼갬)
# 2. Call Merge sort on each half to sort them recursively(반으로 나누어진 각 배열에 대해 merge sort를 호출(재귀))
# 3. Merge both sorted halves into one sorted array(정렬된 두 배열을 하나의 정렬된 배열로 병합)
def merge_sort(arr):
# Split array in half
if len(arr) > 1:
left_arr = arr[:len(arr)//2]
right_arr = arr[len(arr)//2:]
# recursion
# Call merge_sort on each half to sort them recursively
merge_sort(left_arr)
merge_sort(right_arr)
# merge
i = 0
j = 0
k = 0 # merged array index
while i < len(left_arr) and j < len(right_arr):
if left_arr[i] < right_arr[j]:
arr[k] = left_arr[i]
i += 1
k += 1
else:
arr[k] = right_arr[j]
j += 1
k += 1
# Merge both
while i < len(left_arr):
arr[k] = left_arr[i]
i += 1
k += 1
while j < len(right_arr):
arr[k] = right_arr[j]
j += 1
k += 1
- 힙 정렬(Heap Sort)

- 힙(Heap)은 완전이진트리 기반의 자료구조이다.
- 여러 개의 값들 중에서 가장 큰 값이나 가장 작은 값을 빠르게 찾아내도록 만들어진 자료구조다.
- 완전이진트리란 하나의 부모 노드에 대해서 왼쪽 자식 노드 → 오른쪽 자식 노드 순서로 자식 노드가 전부 채워져 있어야 완전이진트리라고 할 수 있다.
- 힙에는 최대 힙(Max Heap)과 최소 힙(Min Heap)이 존재한다. 일반적으로 힙을 사용하는 경우 최소 힙으로 동작하게 된다.
- 힙 정렬의 시간복잡도는
O(N log N)이다.
- 최소 힙(Min Heap)
- 부모 노드의 키 값이 자식 노드의 키 값보다 작거나 같은 완전이진트리
- key(부모 노드) ≤ key(자식 노드)
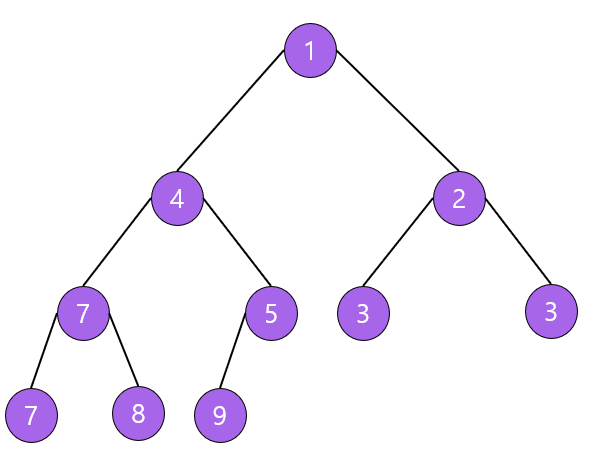
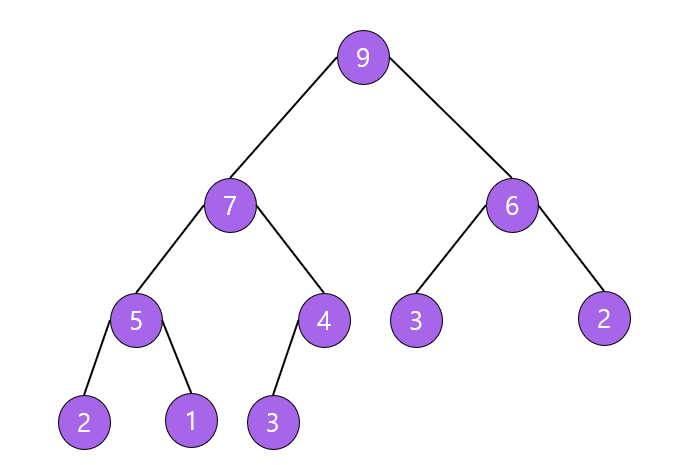
- 최대 힙(Max Heap)
- 부모 노드의 키 값이 자식 노드의 키 값보다 크거나 같은 완전이진트리
- key(부모 노드) ≥ key(자식 노드)
- python
heapq모듈은 heap(priority queue) 알고리즘을 제공한다.heapq는 내장 모듈로 별도의 설치없이 바로 사용할 수 있다.
[힙 함수 활용하기]
heapq.heappush(heap, item): item을 heap에 추가heapq.heappop(heap): heap에서 가장 작은 원소를 pop & return, 비어 있는 경우IndexError가 호출됨heapq.heapify(x): 리스트 x를 heap으로 변환
# python Min Heap Implementation
import heapq
heap = []
heapq.heapify(heap)
heapq.heappush(heap, 50)
heapq.heappush(heap, 10)
heapq.heappush(heap, 20)
print(heap)
# [10, 20, 50]
- 위의 python 코드는 최소 힙에 대한 코드이다. y = -x 변환을 하면 최솟값 정렬이 최댓값 정렬로 바뀐다.
