
오늘은 yolov5 모델을 이용하여 image detection을 해보겠습니다.
저는
python==3.9,2
torch==1.2.0+cu102
버젼을 사용했습니다.
제가 사용한 데이터는 roboflow에서 제공하는 Pothole dataset입니다.
위 사진과 같이 도로에 움푹파인 구멍들이 labeling된 데이터셋입니다.
pothole dataset은 아래의 링크에서 다운받을 수 있습니다.
https://public.roboflow.com/object-detection/pothole
다음은 yolov5 github입니다.
아래의 주소를 gitclone 하셔도 좋고 들어가셔서 직접 다운받으셔도 무관합니다
https://github.com/ultralytics/yolov5
%cd /put/your/direction/to/download/models
!git clone https://github.com/ultralytics/yolov5다운받은 Yolov5모델은 이렇게 구성되어 있네요.
Yolo의 원리 및 세부사항을 알고싶으신 분들은 아래의 링크 참조하시면 될것 같습니다.
저도 많은도움이 되었네요.
https://colab.research.google.com/drive/1KKp9-Fhr-PmN_Cndebb0wSy-JgcZuPST?usp=sharing
자 그럼 본격적으로 들어가 보도록 하겠습니다.
#%%get iamgedata
from glob import glob
train_img_list=glob('/home/nvidia/dogcat/yolov5/pothole_dataset/train/images/*.jpg')
test_img_list=glob('/home/nvidia/dogcat/yolov5/pothole_dataset/test/images/*.jpg')
valid_img_list=glob('/home/nvidia/dogcat/yolov5/pothole_dataset/valid/images/*.jpg')
print(len(train_img_list),len(test_img_list),len(valid_img_list))glob을 사용하여 다운받은 pothole dataset에서 이미지 데이터를 가져옵니다.
경로는 개인이 다운받은 경로로 수정하시면 됩니다.
길이를 보니 465 67 133으로 잘 가져와졌군요.
#%%set imagedata
import yaml
with open('/home/nvidia/dogcat/yolov5/pothole_dataset/train.txt','w') as f:
f.write('\n'.join(train_img_list)+'\n')
with open('/home/nvidia/dogcat/yolov5/pothole_dataset/test.txt','w') as f:
f.write('\n'.join(test_img_list)+'\n')
with open('/home/nvidia/dogcat/yolov5/pothole_dataset/valid.txt','w') as f:
f.write('\n'.join(valid_img_list)+'\n')다음은 가져온 파일을 yaml파일로 만들어줍니다.
#%%writetemplate function
from IPython.core.magic import register_line_cell_magic
@register_line_cell_magic
def writetemplate(line,cell):
with open(line,'w') as f:
f.write(cell.format(**globals()))다음은 여러가지 template들은 text처럼 사용할수 있도록 하는 함수를 만들어 줍니다.
%cat /home/nvidia/dogcat/yolov5/pothole_dataset/data.yamlcat을 이용해서 data,yaml을 확인해봅니다.
train: ../train/images
val: ../valid/images
nc: 1
names: ['pothole']
이렇게 나오네요. 이것을 우리가 가진 데이터와 적합하게 바꿔줍니다.
#%%set data.yaml
%%writetemplate /home/nvidia/dogcat/yolov5/pothole_dataset/data.yaml
train: /home/nvidia/dogcat/yolov5/pothole_dataset/train/images
test: /home/nvidia/dogcat/yolov5/pothole_dataset/test/images
val: /home/nvidia/dogcat/yolov5/pothole_dataset/valid/images
nc: 1
names: ['pothole']이렇게 말이죠.
개인적으로 저는 경로를 사용할 때 절대경로를 사용하는 것을 선호합니다.
하지만 상대경로를 사용하여도 무관합니다.
%cat /home/nvidia/dogcat/yolov5/pothole_dataset/data.yaml다시 한번 확인해보면 잘 바뀌어져 있네요.
#%%get numclasses in data
with open("/home/nvidia/dogcat/yolov5/pothole_dataset/data.yaml",'r') as stream:
num_classes=str(yaml.safe_load(stream)['nc'])다음은 data의 확인을 위해 data.yaml을 가져와서 클래스의 갯수를 변수에 저장시켜줍니다.
알고 있지만 습관적으로 이런 작업을 해주면 실수가 줄어들겠죠?
%cat /home/nvidia/dogcat/yolov5/models/yolov5s.yaml저는 yolov5s모델을 이용해서 학습할 것이기 때문에 모델확인을 위해 cat을 사용해줍니다

위와 같이 모델의 구조를 확인할 수 있습니다.
%%writetemplate /home/nvidia/dogcat/yolov5/models/custom_yolov5s.yaml
# Parameters
nc: (num_classes) # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]복사후 미리 정의해둔 writetemplate를 이용하여 저희가 사용할 모델을 nc를 수정후 저장하여 줍니다.
원본을 수정하기보단 새로 정의하여 주는것이 안전합니다.
%cat /home/nvidia/dogcat/yolov5/models/custom_yolov5s.yaml수정한 custom model을 확인하여보면 역시나 잘 정의되었네요.
#%%train
!python /home/nvidia/dogcat/yolov5/train.py --img 640 --batch 32 --epochs 100 --data /home/nvidia/dogcat/yolov5/pothole_dataset/data.yaml --cfg /home/nvidia/dogcat/yolov5/models/custom_yolov5s.yaml --weights '' --name pothole_results --cacheyolov5의 train.py를 사용하여 학습시켜줍니다.
파라미터들은 위의 값이 절대적인 수치가 아님을 알려드립니다.
각자의 필요에 따라 파라미터를 수정 후 사용하시길바랍니다.
#%%load tensorboard
%load_ext tensorboard
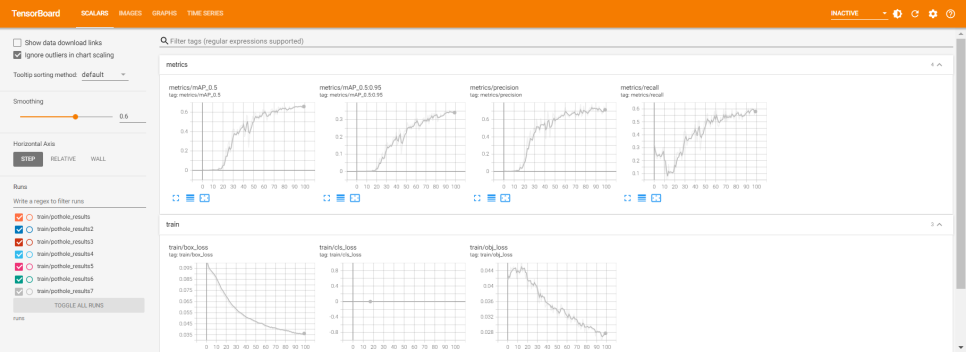
%tensorboard --logdir runs혹시 google colaboraty에서 파일을 실행하시는분은 위의 코드로 학습결과를 더 간편히 볼 수 있습니다
#%%check result folder list
!ls /home/nvidia/dogcat/yolov5/runs/train/pothole_results4/학습 후 결과들이 저장된 파일에는 이런형식으로 저장되어있네요.

#%%result
from IPython.display import Image,clear_output,display
display(Image(filename='/home/nvidia/dogcat/yolov5/runs/train/pothole_results4/results.png',width=1000))그 중 result.png파일을 보면 학습과정을 한눈에 볼수 있습니다.
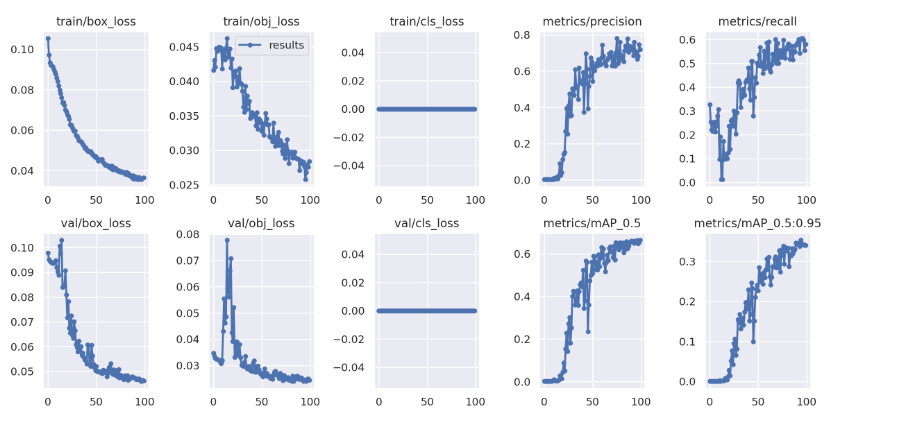
validation의 loss를 보니 epoch을 더 높이면 더 좋은 결과를 얻을 수 있을것 같습니다
#%%first trainbatch
display(Image(filename='/home/nvidia/dogcat/yolov5/runs/train/pothole_results4/train_batch0.jpg',width=1000))첫번째 train batch의 데이터들을 살펴봐줍니다.

#%%labeled first validation batch
display(Image(filename='/home/nvidia/dogcat/yolov5/runs/train/pothole_results4/val_batch0_labels.jpg',width=1000))위의 코드로 라벨링된 validation데이터도 체크해줍니다.

#%%check wights folder list
%ls /home/nvidia/dogcat/yolov5/runs/train/pothole_results4/weights가중치 파일을 보면 가장 수치가 좋았던 모델과 마지막으로 학습니 끝난 모델 두개가 저장되어 있네요.
일반적인 상황에서는 best.pt를 사용하면 좋겠죠?
best.pt last.pt
#%%run detect.py
!python /home/nvidia/dogcat/yolov5/detect.py --weights /home/nvidia/dogcat/yolov5/runs/train/pothole_results4/weights/best.pt --img 640 --conf 0.4 --source /home/nvidia/dogcat/yolov5/pothole_dataset/test/imagesdetect.py 에 best.pt를 적용해서 test image들을 object detection해봅니다. 제 기준으로는 꽤 빠른 속도로 진행되네요.
size가 작은 모델을 사용한것이 효과 있는것 같습니다.
import glob
import random
from IPython.display import Image,display
image_name=random.choice(glob.glob('/home/nvidia/dogcat/yolov5/runs/detect/exp2/*.jpg'))
display(Image(filename=image_name))random하게 detection이 끝난 image들을 가져와서 잘 되었는지 확인해줍니다.

잘 detection 되었네요.
이상입니다. 긴 글 봐주셔서 감사합니다~.
