
GROUP BY
background
Red Text
INDEX
- GROUP BY란?
- GROUP BY의 목적
- GROUP BY의 사용
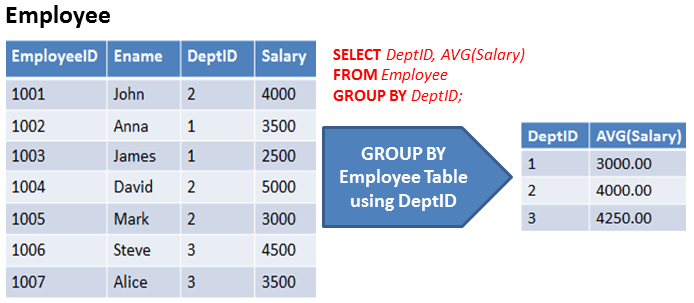
GROUP BY란?
- 같은 값을 가진 행을 그룹짓는 SQL 명령어
- GROUP BY는 COUNT(), MAX(), MIN(), SUM(), AVG() 등 집계 함수와 함께 사용된다.
- GROUP BY절은 각 그룹의 하나만을 리턴한다.
- FROM절과 WHERE절 뒤에 위치한다.
- SQL 7.0이후 부터는 GROUP BY를 할 때 비용을 따져서 정렬하여 그룹핑을 하는 경우도 있고, Hash Match를 통해서 정렬이 이루어지지 않을 수도 있다. 따라서 GROUP BY를 할 때 반드시 ORDER BY는 되지 않으므로 명시적으로 정렬을 원한다면 ORDER BY를 사용하여야 하고 ORDER BY를 사용 하므로써 추가 비용이 발생을 하게 된다.
GROUP BY 실행 순서

Distinct vs GROUP BY
Distinct는 중복된 데이터를 제거하고 unique값을 추출하기 위해 사용되는 SQL명령어로 이는 GROUP BY의 집계 키 기준으로 집합 연산을 위해 사용되어 unique값을 추출하는 GROUP BY와는 차이가 있다.
구문
SELECT column_name(s) FROM table_name WHERE condition GROUP BY column_name(s)SELECT COUNT/MAX/MIN/SUM/AVG(CustomerID), Country FROM Customers GROUP BY Country ORDER BY COUNT/MAX/MIN/SUM/AVG(CustomerID) DESC;SELECT EXTRACT(year FROM date) AS year, EXTRACT(month FROM date) AS month, ROUND(AVG(price), 2) AS avg_price FROM visit GROUP BY 1, 2;
주의
- SELECT 문에 있는 모든 열은 집계 함수가 되거나 GROUP BY 절에 나타나야 한다. GROUP BY 절을 사용하는데 만약 SELECT 문에 집계 함수를 사용하지 않거나 GROUP BY 절에 언급되지 않은 열이 존재한다면 오류가 발생한다.
- GROUP BY가 SELECT 보다 먼저 실행 되지만, SELECT의 alias를 사용할 수 있다. (DBMS에 의하여-mySql 기준) 단, 표준 SQL에서는 지원하지 않는다.
GROUP BY, HAVING, ORDER BY에서 SELECT의 alias를 사용할 수 있다.
WHERE절에서는 SELECT의 alias를 사용할 수 없다.실제 컬럼명만 사용가능하다.
간접적인 방법은 있다. (서브쿼리 등)
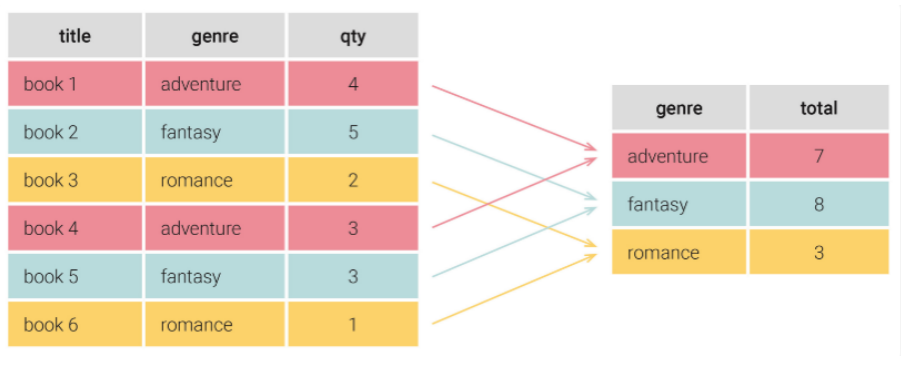
GROUP BY의 목적
위에서 언급한 바와 같이 GROUP BY 절은 주로 집계 함수와 같이 사용되곤 한다. 여기서 집계 함수는 여러 행의 값을 더하거나, 평균값을 내거나, 개수를 세는 등 여러 개의 데이터에 관한 계산을 한다.가장 대표적인 집계 함수는 다음과 같다.
- COUNT() : 행의 개수
- AVG() : 행 안에 있는 값의 평균
- MIN() : 행 안에 있는 값의 최솟값
- MAX() : 행 안에 있는 값의 최댓값
- SUM() : 행 안에 있는 값의 합
즉, 다양한 계산을 하기 위해 행을 그룹화한다.
GROUP BY의 사용
GROUP BY와 집계 함수의 사용
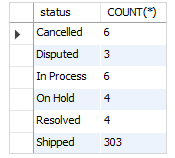
SELECT status, COUNT(*) FROM orders GROUP BY status;
- status값을 기준으로 그룹핑
- 그룹을 기준으로 COUNT 집계함수를 통해 갯수를 추출(열의 추가)
- COUNT()과 COUNT(columnName)의 차이는 NULL 의 포함 여부(COUNT()-NULL포함)
- 결과
GROUP BY와 JOIN 그리고 집계 함수
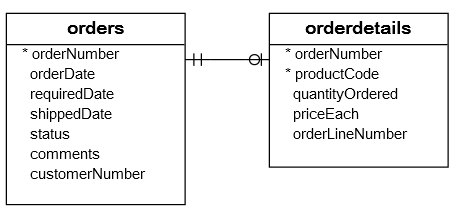
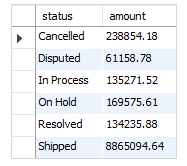
SELECT o.status, SUM(quantityOrdered * priceEach) AS amount FROM orders o INNER JOIN orderdetails od ON o.orderNumber = od.orderNumber GROUP BY o.status;
- status(상태)에 따른 total값을 구하는 쿼리
- orders 테이블을 기준으로 orderNumber가 존재하는 테이블만 추출 후 status로 그룹핑, SUM 집계 함수를 통해 각 status에 해당하는 amount 열을 추가
- 결과
GROUP BY와 표현식
SELECT EXTRACT(year FROM o.orderDate) AS year, SUM(od.quantityOrdered * od.priceEach) AS total FROM orders o INNER JOIN orderdetails od ON o.orderNumber = od.orderNumber WHERE o.status = 'Shipped' GROUP BY YEAR(o.orderDate);
- INNER JOIN 후 WHERE의 조건에 따른 필터링
- GROUP BY에 표현식에 의해 그룹핑
- 집계함수 SUM을 이용한 total 열 추가 및 EXTRACT를 활용한 년도 추출
GROUP BY와 HAVING
SELECT YEAR(o.orderDate) AS year, SUM(od.quantityOrdered * od.priceEach) AS total FROM orders o INNER JOIN orderdetails od ON o.orderNumber = od.orderNumber WHERE status = 'Shipped' GROUP BY YEAR(o.orderDate) or year//mySQl 기준 HAVING year > 2003;
- INNER JOIN 후 WHERE절에 의한 필터링
- SELECT 문의 alias를 이용하여 GROUP BY 그룹핑
- SELECT 문에 의한 결과 셋 도출
- 결과 셋으로부터 HAVING절에 의한 재필터링 처리
- WHERE절은 그룹핑이 되기전 컬럼에 대한 필터링을 처리한다면, HAVING은 그룹핑이 끝난 후 나온 결과셋에서의 필터링을 처리한다.
그 외
- 가능한한 HAVING절의 사용을 피한다.
Having절은 GROUP BY에 의한 결과를 제한할 때 사용한다. 이는 GROUP BY에 Having절을 사용하였을 경우 GROUP BY에 의해서 결과들을 집계한 다음 Having절에 명시한 조건으로 맞지 않는 결과를 버리는 과정을 거친다. 대부분의 경우에서 Having절의 필요없이 GROUP BY와 WHERE절만으로 원하는 결과를 얻을 수 있으므로 피하는게 좋다.
SELECT
CASE GROUPING(orderYear) WHEN 1
THEN 'All Years' ELSE orderYear END AS orderYear
CASE GROUPING(productLine) WHEN 1
THEN 'All Product Lines' ELSE productLine END AS productLine
SUM(orderValue) totalOrderValue
FROM
sales
GROUP BY
orderYear ,
productline
WITH ROLLUP;