Elasticsearch
Apache Lucene(아파치 루씬) 기반의 Java 오픈소스 분산 검색 엔진이다. 방대한 양의 데이터를 신속하게 거의 실시간으로(NRT, Near Real Time) 저장, 검색, 분석할 수 있다.
검색을 위해 단독으로 사용되기도 하며 ELK(Elasticsearch / Logstash / Kibana) 스택으로 사용되기도 한다.
- Logstash
- 다양한 소스(DB, csv파일 등)의 로그 또는 트랜잭션 데이터를 수집, 집계, 파싱하여 Elasticsearch로 전달
- Elasticsearch
- Logstash로부터 받은 데이터를 검색 및 집계를 하여 정보 획득
- Kibana
- Elasticsearch의 빠른 검색을 통해 얻은 데이터를 시각화 및 모니터링

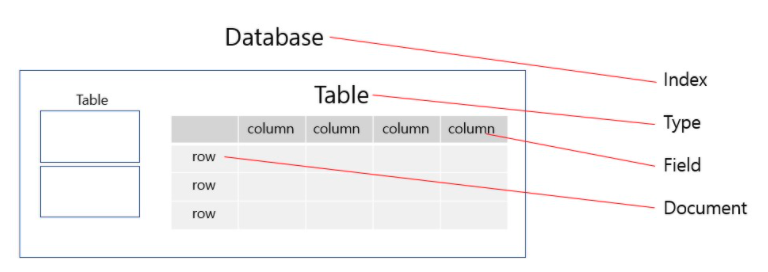
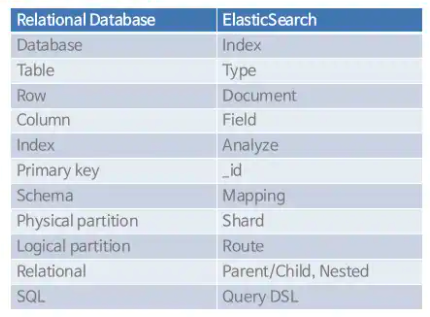
Elasticsearch vs RDBMS
Elasticsearch DSL
Domain Specific Language 로 JSON에 기반한 질의이다. 데이터베이스의 SQL문과 동일하다고 이해하면 된다. 사용자가 원하는 데이터를 추출하기 위한 질의 언어이다.
Query vs Filter
- Query
"이 문서가 해당 쿼리절과 얼마나 잘 일치합니까?" 라는 질문에 대답한다. 문서가 일치하는지 여부를 결정하는 것 외에도 _score 메타 필드에서 관련성 점수를 계산한다. 관련성 점수는 소수점 숫자이며 _score가 높을수록 문서의 관련성이 높아진다. - Filter
"이 문서가 해당 쿼리절과 일치합니까?" 라는 질문에 대답한다. score를 계산하지 않고 간단하게 예 아니오로 계산한다. 주로 구조화된 데이터를 필터링하는데 사용된다. 문서의 score 가 필요없는 데이터 형태를 필터링할 때 사용된다. 또한 자동으로 캐싱되어 성능을 향상시키며 score를 계산하지 않기 때문에 query보다 검색이 빠르다.
검색하고자 하는 용도에 따라 query와 filter를 유연하게 사용해야 좋은 성능을 낼 수 있다.
Query
- term
형태소 분석기에 의해 쪼개진 토큰들을 기반으로 동작한다. 주어진 질의문과 저장된 형태소의 토큰이 정확하게 일치하는 문장을 찾는다. 검색하고자 하는 타입이 텍스트 필드라면 term 쿼리보다는 match 쿼리를 사용하는 것이 좋다. - terms
term은 질의문이 1개 가능하지만 terms는 배열로 여러 개의 질의문을 사용할 수 있다. - match
- 형태소 분석기에 의해 쪼개진 토큰들을 기반으로 동작한다. term과의 차이점은 주어진 질의를 형태소 분석기를 거쳐 쪼갠 다음 조회를 한다. 1개라도 존재하는 토큰이 있으면 결과를 반환한다.
- 검색어가 여럿일 때 검색조건을 or 가 아닌 and 로 바꾸려면
operator옵션을 사용한다.
필드명: 검색어 -> 필드명: {'query': 검색어, 'operator': 'and'}
- multi_match
여러 필드에 단일 질의문을 검색할 때 사용한다. - match_phase
보통 문장을 검색할 때 사용한다. match는 순서와 상관없이 1개 이상 일치하는 토큰이 있으면 결과를 반환하지만 match_phase 는 입력된 질의와 저장된 토큰의 순서가 정확하게 일치해야 한다. - Bool
다른 쿼리들을 조합하여 결과와 score들을 결합하거나 동작을 변경한다. 4개의 인자를 가지고 있다.- must : 쿼리가 참인 도큐먼트들을 검색
- must_not : 쿼리가 거짓인 도큐먼트들을 검색
- should : 검색 결과 중 이 쿼리에 해당하는 도큐먼트의 score를 높인다.
- filter : 쿼리가 참인 도큐먼트를 검색하지만 score를 계산하지 않는다. must 보다 검색속도가 빠르고 캐싱이 가능하다.

개발자꿈나무🌲