알고리즘
1.[알고리즘 공부] Stack
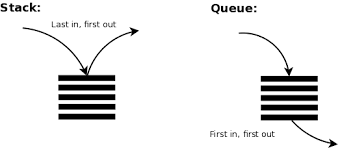
참고자료구조는 데이터의 표현과 저장 방법을 의미그러므로 , 자료구조를 알아야 알고리즘을 배울 수 있음.스택은 연결리스트인데 뒤로 넣고 뒤로만 뺄 수 있습니다. push와 pop만 할 수 있으며, 스택은 실행이 되는 특정한 순서를 따르는 선형적 데이터 구조입니다.스택1출
2.[알고리즘 공부] 힙
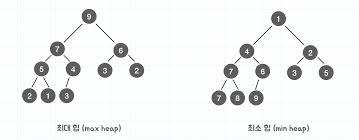
참고(https://overcome-the-limits.tistory.com/9유저가 회원가입을 한다고 생각해봅시다. 만약 유저의 아이디와 비밀번호를 DB에 저장하게 될 텐데, 그렇다면 입력받은 데이터를 내부 DB에 그대로 저장해야 할까요? 물론 데이터를 저장
3.[알고리즘] 큐 - Queue
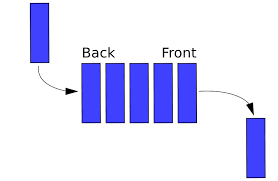
스택과 같이 큐는 같은 선형적 구조는 특정한 순서를 따릅니다.순서는 FIFO(First In First Out) 선입선출입니다.큐1출처: https://devowen.com/211스택과 큐의 차이점은 제거에 있습니다.스택은 가장 최근에 추가된 데이터를 제거하지
4.[알고리즘 공부] 해시
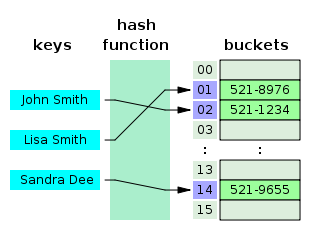
참고(https://overcome-the-limits.tistory.com/9유저가 회원가입을 한다고 생각해봅시다. 만약 유저의 아이디와 비밀번호를 DB에 저장하게 될 텐데, 그렇다면 입력받은 데이터를 내부 DB에 그대로 저장해야 할까요? 물론 데이터를 저장
5.[알고리즘 공부] 완저탐색기법 - 비트마스크, 순열 ,재귀
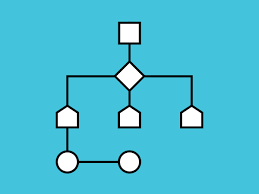
참고완전 탐색 자체가 알고리즘은 아니기 때문에 완전 탐새 방법을 이용하기 위해서 다양한 알고리즘 기법이 이용됨.단순히 반복문과 조건문으로 모든 경우를 만들어 답을 구하는 방법.이방법만을 사용하는 문제는 거의 나오지 않음.나올 수 있는 모든 경우의 수가 각각의 원소가 포
6.[알고리즘 공부] 너비 우선 탐색(BFS), 깊이 우선 탐색(DFS)
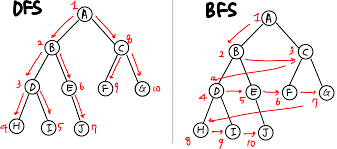
참고참고2너비우선탐색(Breadth-First Search, BFS)는 하나의 요소를 방문하고 그 요소에 인접한 모든 요소를 우선 방문하는 방식깊이우선탐색(Depth-First Search, DFS)는 트리의 한 요소(노드)와 다음 수준(level)의 자식 노드를 따라
7.[알고리즘 공부] 그리디(탐욕법)
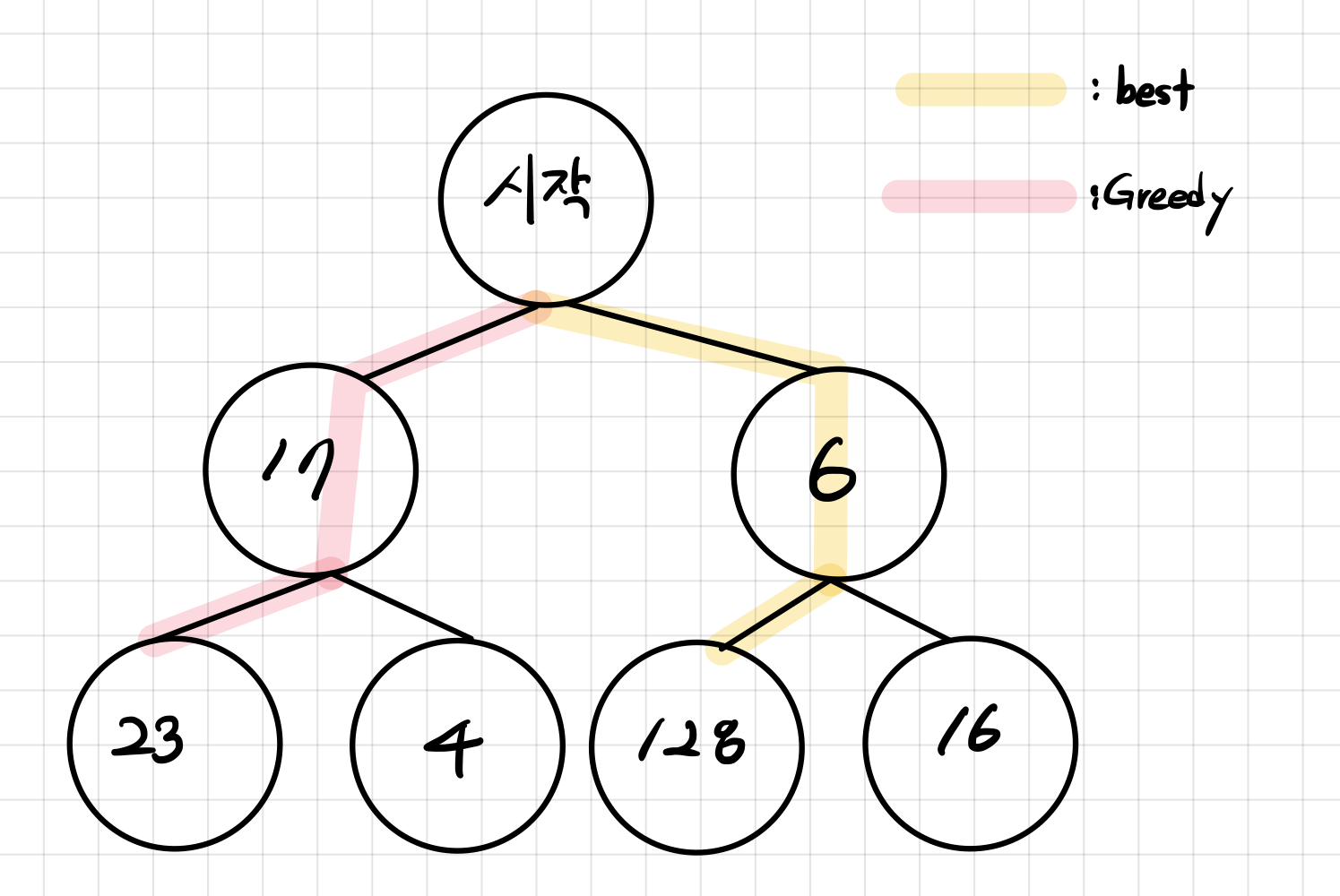
현재 상황에서 가장 좋은 최적의 해 만 고르는 방법.매 순간 최적의 해를 선택하며, 현재의 선택이 나중에 어떠한 영향을 미칠지는 고려하지 않는다.문제를 여러 개의 부분 문제로 나누고, 각 부분 문제마다 답을 구해 결국 원하는 답을 구한다.지금 이 순간 당장 최적인 것을
8.[알고리즘 공부] 정렬(선택, 삽입, 퀵, 계수)

선택 정렬은 가장 작은 값을 탐색한 다음 그 값을 정렬이 안된 배열의 맨 앞에 위치한 값과 교체하는 알고리즘.i라는 시작점을 두고 j반복문을 돌려 최솟값을 찾아 시작점과 교체해주는 반복을 거쳐서 정렬해주는 방식삽입 정렬은 아직 정렬되지 않은 임의의 데이터를 이미 정렬된
9.[알고리즘 공부] 동적계획법
참고큰 문제를 한 번에 해결하기 힘들 때 작은 문제로 나누어 푸는데,이 때 이전에 계산한 값을 저장해두었다가 다시 사용하는 것이 핵심큰 문제를 작은 문제로 분할하여 푼다는 점에서 분할정복 알고리즘과 유사하지만, 한 번 계산했던 값은 저장한다는 점에서 (Memoizati
10.[알고리즘 공부] 이진탐색 (이분탐색)
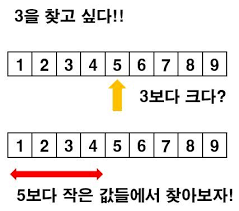
참고이진 탐색 알고리즘(Binary Search Algorithm)은 이미 정렬되어 있는 배열에서 탐색 범위를 두 부분 리스트로 나눠 절반씩 좁혀가 필요한 부분에서만 탐색하도록 제한하여 원하는 값을 찾는 알고리즘입니다.예를 들어 1부터 10까지의 배열에서 3을 찾는다면
11.[알고리즘 공부] 그래프
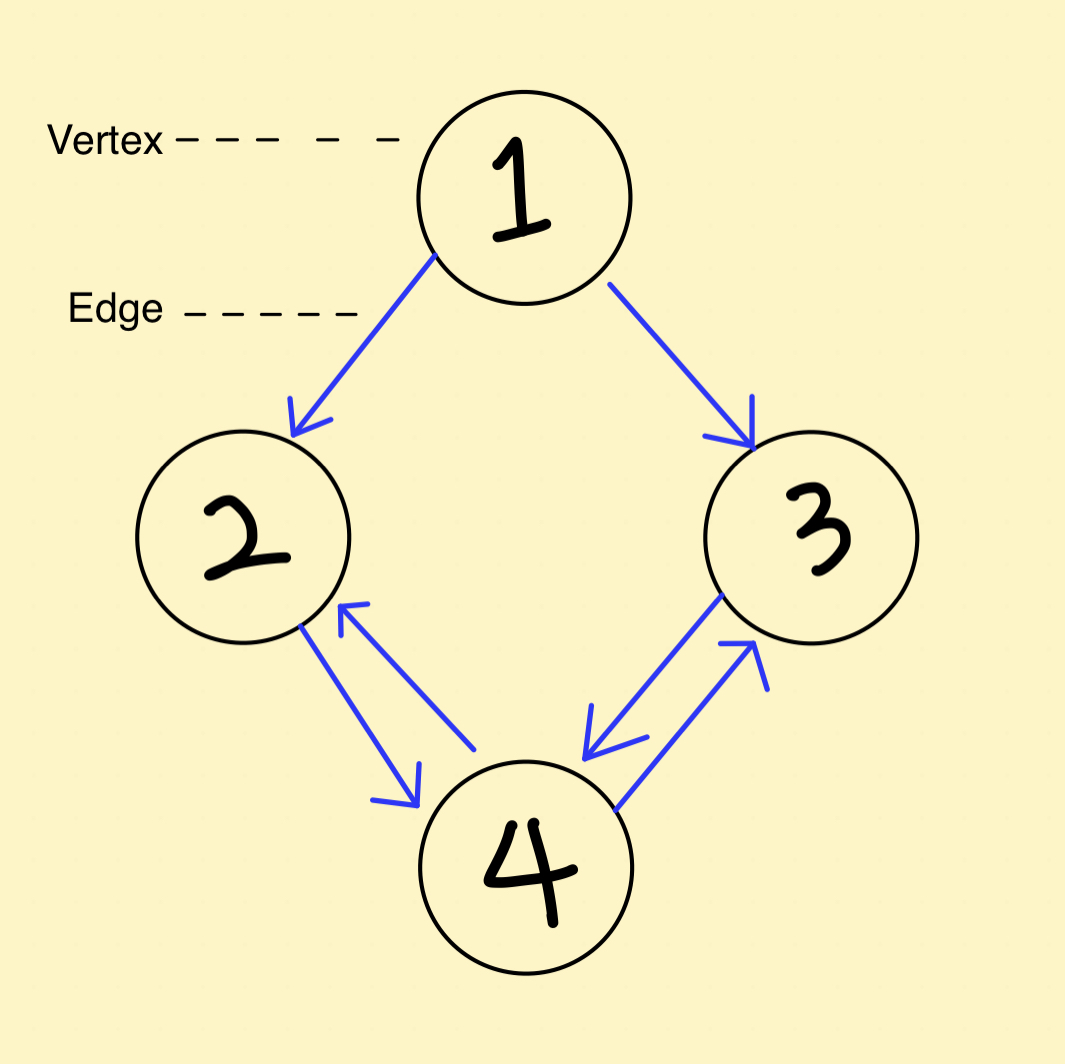
참고그래프는 여러개의 점들이 서로 복잡하게 연결되어 있는 관계를 표현한 자료구조직접적인 관계가 있는 경우 두 점 사이를 이어주는 선이 있다.간접적인 관계라면 몇 개의 점과 선에 걸쳐 있다.하나의 점을 그래프에서는 정점(vertex)이라고 표현하고,하나의 선은 간선(ed