Merge Sort
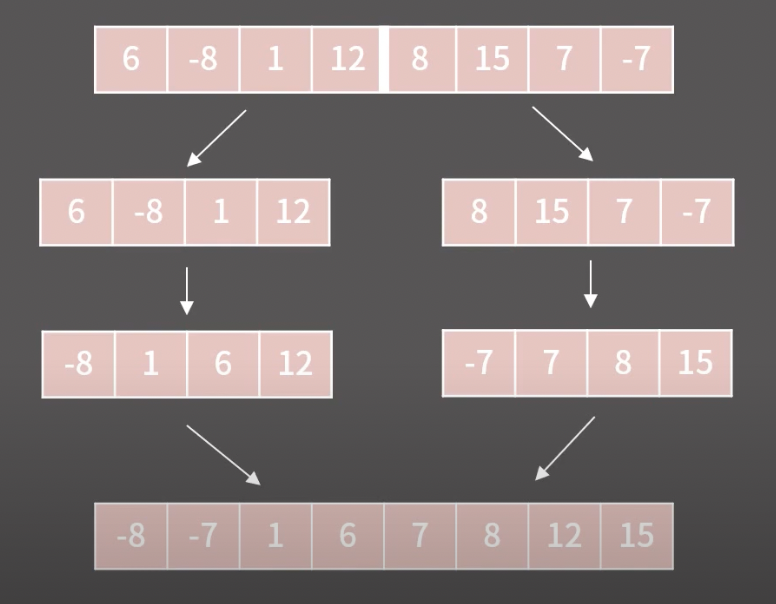
재귀적 방법으로 원소를 반 씩 쪼개나가면서 정렬을 수행하는 방법.- 절반으로 쪼개진 배열의 크기가 1이 될때까지 반복한다.
- 크기가 1로 이루어진 배열들을 하나씩 정렬해가며 다시 배열을 채워나가는 방식
Merge Sort의 시간복잡도
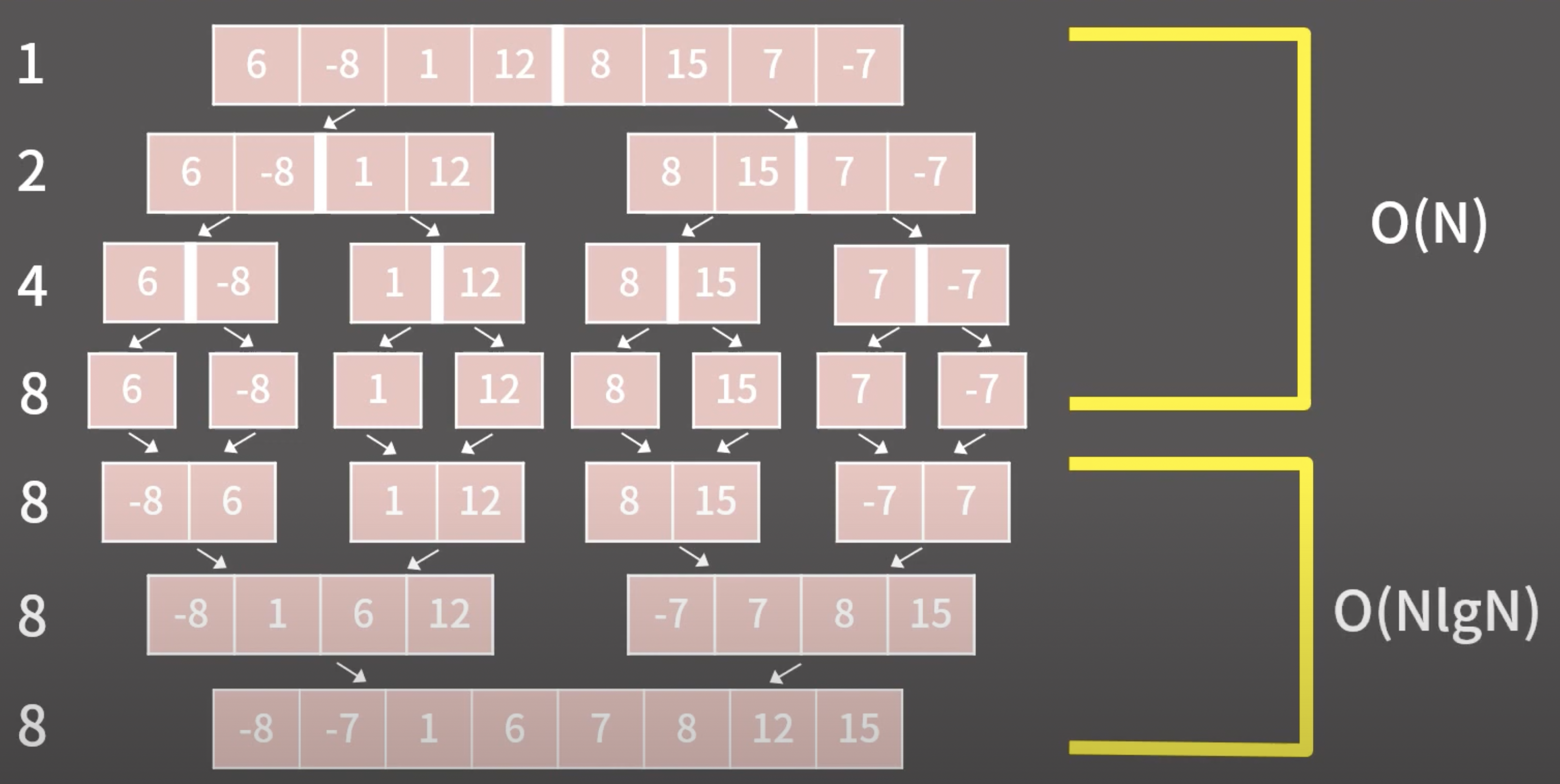
배열을 쪼개는 경우: 첫번째 줄에서는 1번의 쪼갬, 두번째 줄에서는 2번의 쪼갬, 세번째 줄에서는 4번의 쪼갬... n번째 줄에서는 2^n번의 쪼갬이 필요하다... 1+2+4...2^n = 2n....이므로, 이는 시간복잡도 O(n) 의 연산이다.
배열을 합치는 경우: 크기가 1인 배열들을 합쳐서 크기가 N인 원소를 다시 만들어야한다. 이는 매 배열의 크기가 2씩 늘어나는 합쳐짐의 과정을 거친다. 배열의 크기가 2배로 늘어나면서 합치는 과정은 각 단계마다 N의 연산이 필요하고, 또한 해당 연산을 총 log2N번 반복해야 하기떄문에 O(NlogN) 의 연산이 필요하게 된다.
이 둘을 합치면 총 O(NlogN)의 연산이 필요하게 된다.
코드
#include <bits/stdc++.h>
using namespace std;
int n = 10;
int arr[1000001] = {15, 25, 22, 357, 16, 23, -53, 12, 46, 3};
int tmp[1000001]; // merge 함수에서 리스트 2개를 합친 결과를 임시로 저장하고 있을 변수
// mid = (st+en)/2라고 할 때 arr[st:mid], arr[mid:en]은 이미 정렬이 되어있는 상태일 때 arr[st:mid]와 arr[mid:en]을 합친다.
void merge(int st, int en){
int mid = (st+en)/2;
int lidx = st; // arr[st:mid]에서 값을 보기 위해 사용하는 index
int ridx = mid; // arr[mid:en]에서 값을 보기 위해 사용하는 index
for(int i = st; i < en; i++){
if(ridx == en) tmp[i] = arr[lidx++];
else if(lidx == mid) tmp[i] = arr[ridx++];
else if(arr[lidx] <= arr[ridx]) tmp[i] = arr[lidx++];
else tmp[i] = arr[ridx++];
}
for(int i = st; i < en; i++) arr[i] = tmp[i]; // tmp에 임시저장해둔 값을 a로 다시 옮김
}
// a[st:en]을 정렬하고 싶다.
void merge_sort(int st, int en){
if(en == st+1) return; // 리스트의 길이가 1인 경우
int mid = (st+en)/2;
merge_sort(st, mid); // arr[st:mid]을 정렬한다.
merge_sort(mid, en); // arr[mid:en]을 정렬한다.
merge(st, en); // arr[st:mid]와 arr[mid:en]을 합친다.
}
int main(void){
ios::sync_with_stdio(0);
cin.tie(0);
merge_sort(0, n);
for(int i = 0; i < n; i++) cout << arr[i] << ' '; // -53 3 12 15 16 22 23 25 46 357
}Stable Sort
- Merge Sort는 Stable Sort이다. 예를 들어, 정수 배열을 머지 소트를 통해 정렬하는 경우, 만약 배열내의 같은 크기의 정수가 있다면 해당 정수들의 기존 순서들을 유지하면서 정렬을 한다는 의미이다.
이는 파일정렬(날짜> 이름> 크기 등..)과 같은 경우에 사용할 수 있다.
else if(arr[lidx] <= arr[ridx]) tmp[i] = arr[lidx++];
else tmp[i] = arr[ridx++];- 해당 기능을 구현하기 위해 머지소트의 조건문을 다음과 같이 구성하였다. 좌측, 우측 2개의 배열의 원소에서 크기가 같은 원소가 있는 경우, 좌측의 배열을 넣어주어 기존의 우선순위를 유지하도록 하는 것이다.
Quick Sort
- 퀵 소트는 머지 소트와 마찬가지로 재귀적으로 구현하는 정렬방법이다.
- 마찬가지로 배열의 크기가 1일때까지 쪼개나간다.

피벗을 맨 앞의 원소로 두고, l과 r 포인터를 둔다.
이때 포인터 l은피벗보다 큰 값이 나올때까지 오른쪽으로 이동, 포인터 r은피벗보다 작은 값이 나올때까지 왼쪽으로 이동한다.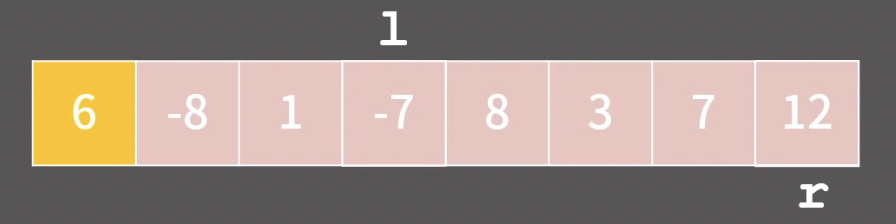
그 다음, l과 r에 해당하는 원소의 위치를 교환한다.이 작업을 r이 l보다 작아질떄까지 반복한다.
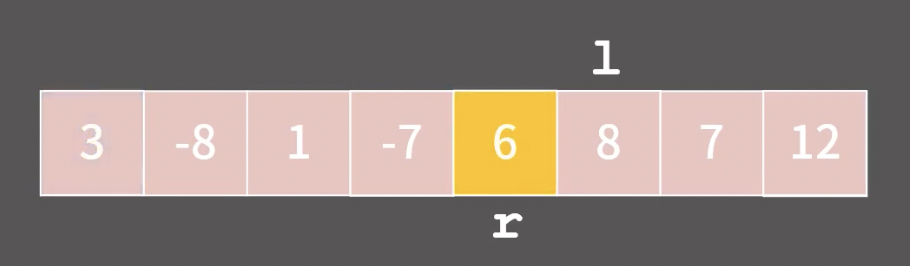
그 다음, 피벗과 r에 해당하는 원소의 위치를 교환하며 마친다. 이제재귀적으로 r을 기준으로 배열을 반으로 쪼개 위의 작업들을 반복해간다.
Quick Sort의 시간복잡도
일반적인 경우
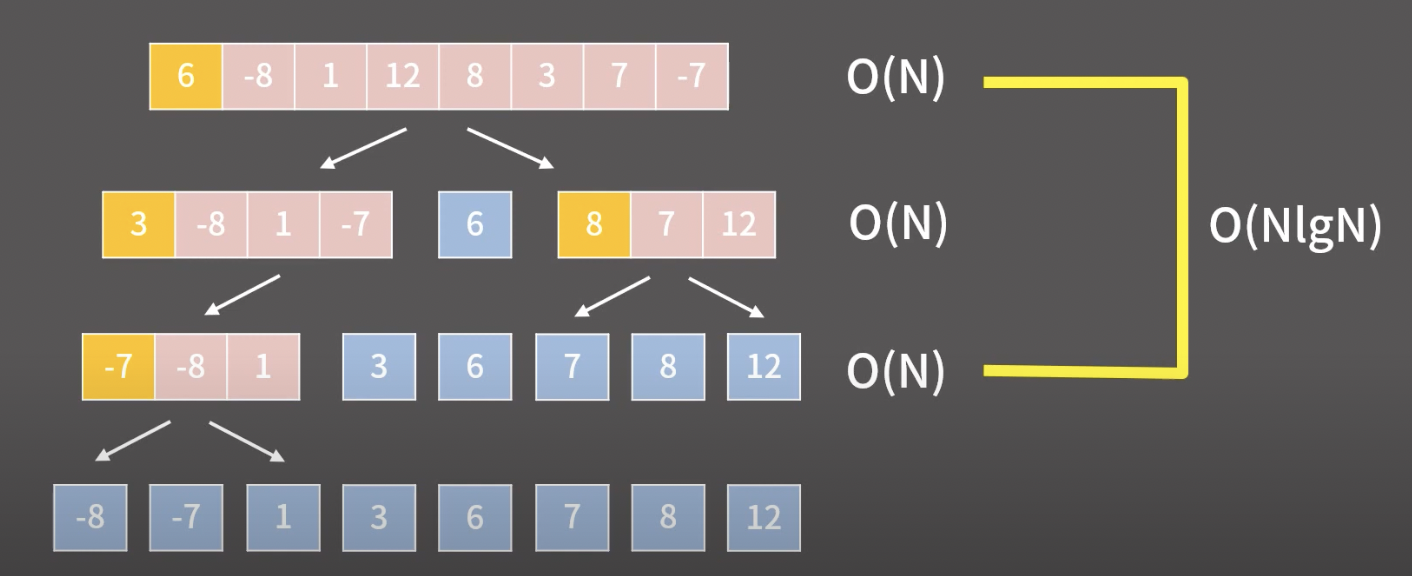
l과 r의 위치를 옮겨가면서 원소를 교환하는 과정은 배열의 크기에 비례하기 때문에 O(n) 의 시간복잡도를 갖는다. 또한, 반으로 쪼개는 과정의 횟수 약 logN 만큼 반복해야하기 때문에 최종적으로 시간복잡도는 O(NlogN) 의 시간복잡도를 갖는다.
최악의 경우
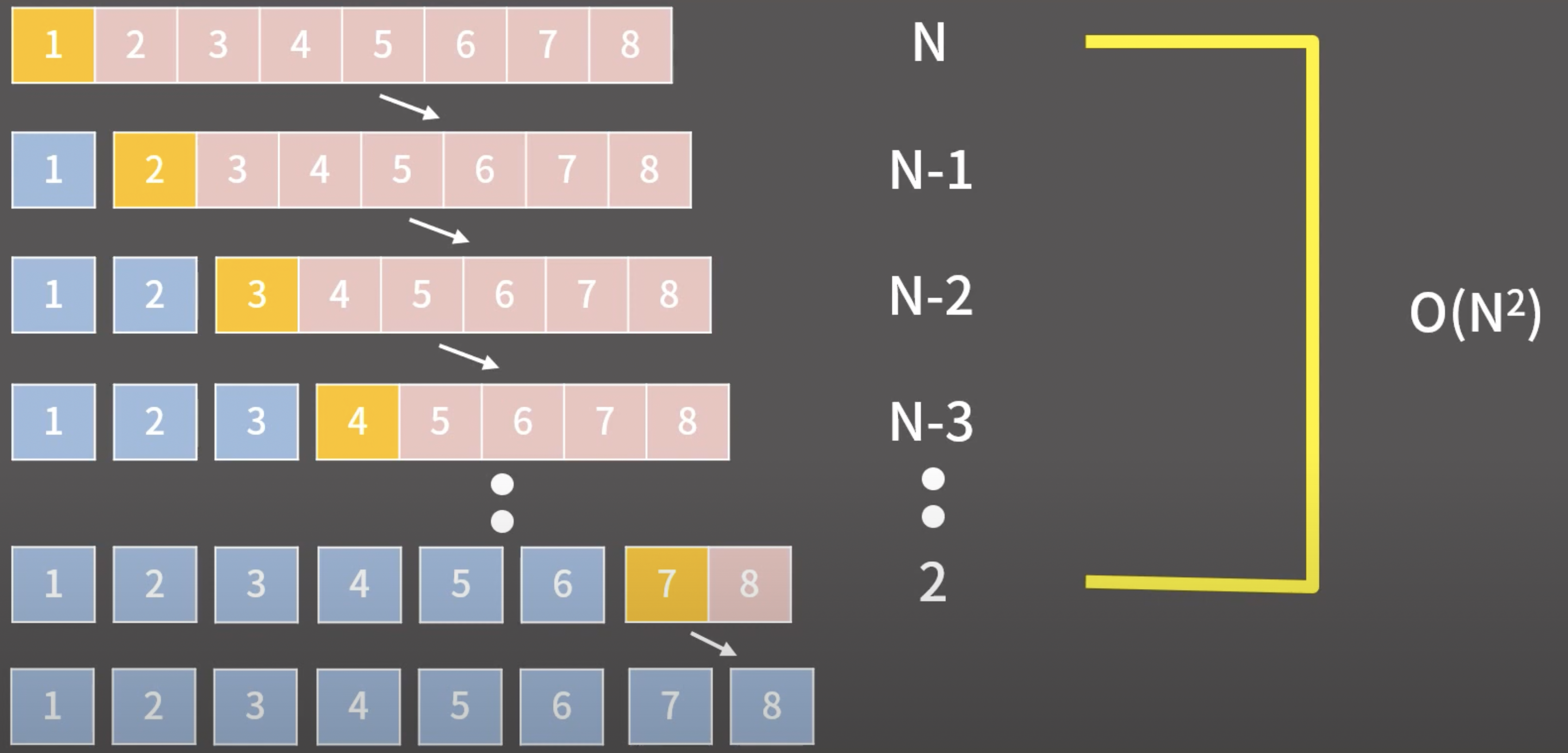
이미 배열이 정렬되어 있는 경우에는, 반으로 쪼개는 과정이 logN 에 비례해 반복하는 것이 아닌 배열의 크기에 비례해 반복해야함으로, O(N^2) 의 시간복잡도를 갖는다.
코드
#include <iostream>
using namespace std;
int n = 8;
int arr[1000001] = {6,-8,-1,12,8,3,7,1};
int tmp[1000001];
void quick_sort(int st, int en)
{
if(st+1>=en) return;
int apos = st+1;
int bpos = en-1;
int pivot = arr[st];
while(1)
{
while(apos <= bpos && arr[apos] <= pivot) apos++;
while(apos <= bpos && arr[bpos] >= pivot) bpos--;
if(apos > bpos) break;
swap(arr[apos],arr[bpos]);
}
swap(arr[st], arr[bpos]);
quick_sort(st, bpos);
quick_sort(bpos+1, en);
}
int main(void)
{
ios::sync_with_stdio(0);
cin.tie(0);
//merge_sort(0,n);
quick_sort(0,n);
for(int i = 0;i<n;i++) cout << arr[i] << ' ';
}Merge Sort vs Quick Sort
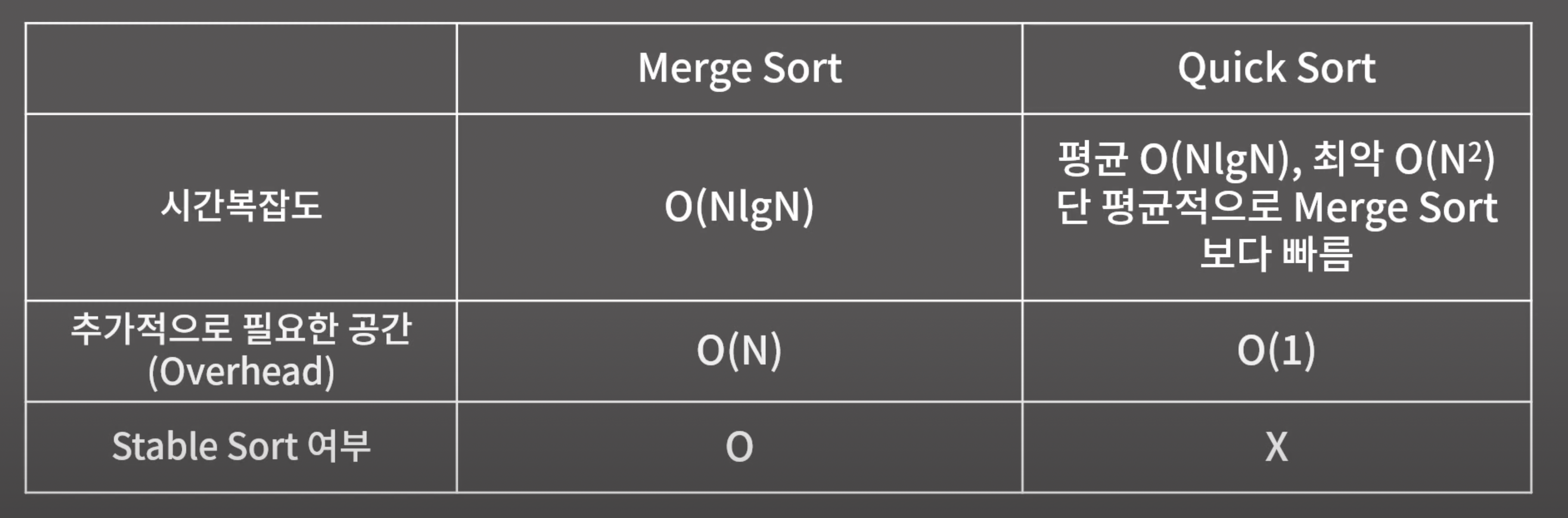
- 머지 소트의 시간복잡도 : 최악의 경우와 최선의 경우 모두
O(NlogN)의 시간복잡도를 가진다. 따라서 코딩테스트에서 직접 구현해야 하는 경우에는 머지소트를 구현해서 사용하는 것이 좋다. - 머지 소트의 오버헤드 : 배열을 임시로 담을 배열이 하나 더 필요함으로
O(n)의 공간복잡도를 갖는다. - 머지소트의 stable 여부 : 동일한 정렬 조건을 갖는 원소에 대해 정렬 전의 순서를 유지하도록 구현이 가능함으로 stable하다.
- 퀵 소트의 시간복잡도 : 최악의 경우(이미 정렬되어 있는 경우)에는
O(N^2)의 시간복잡도를 가지며, 일반적인 경우에는 머지 소트보다 빠른O(NlogN)의 복잡도를 가진다. (cache hit rate, 추가적으로 필요한 배열공간이 없기때문) - 퀵 소트의 오버헤드 : 배열을 임시로 저장해줄 배열이 따로 필요없다.
- 퀵 소트의 stable 여부 : X

개발자 지망생