오늘의 학습 목표는 회귀 문제를 이해하고 K-최근접 이웃 알고리즘을 사용해서 농어의 무게를 예측하는 회귀 문제를 푸는 것입니다.
1. K-최근접 이웃 회귀
지도학습 알고리즘은 크게 분류와 회귀로 나뉩니다.
- 분류: 샘플을 몇 개의 클래스 중 하나로 분류하는 문제
- 회귀: 임의의 어떤 숫자를 예측하는 문제
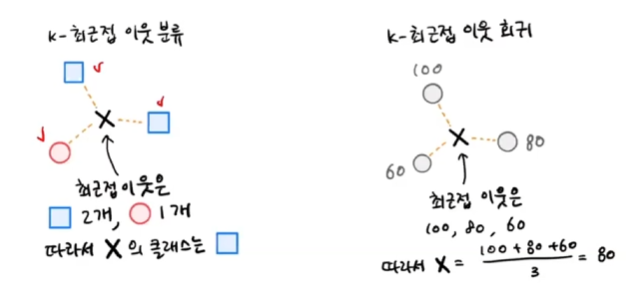
K-최근접 이웃 분류 알고리즘
- 예측하려는 샘플에 가장 가까운 샘플 k 선택
- 샘플들의 클래스를 확인하여 다수 클래스를 새로운 샘플의 클래스로 예측
K-최근접 이웃 회귀 알고리즘
- 분류와 같이 예측하려는 샘플에 가장 가까운 샘플 k개 선택
- 이웃한 샘플의 타깃은 클래스가 아니라 임의의 수치
- 샘플의 수치를 사용해 평균값으로 샘플의 타깃 예측
k-최근접 이웃 회귀의 경우 x라는 샘플과 이웃한 샘플의 타깃값이 각각 100, 80, 60이라면 x의 예측 타깃값은 80이 됩니다.
데이터 준비
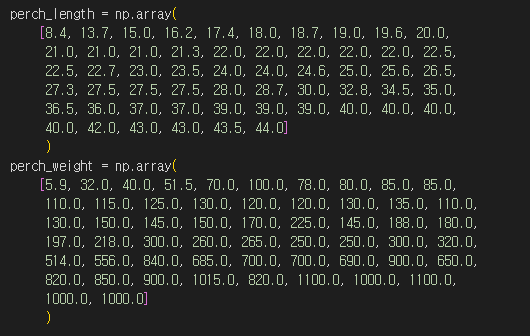
농어의 길이로 농어의 무게를 예측하는 문제를 해결해야 합니다. 따라서 길이가 특성, 무게가 타깃이되는 데이터를 만들어야 합니다. 우선 특성과 타깃 정보를 넘파이 배열 형태로 생성합니다.
산점도 그리기
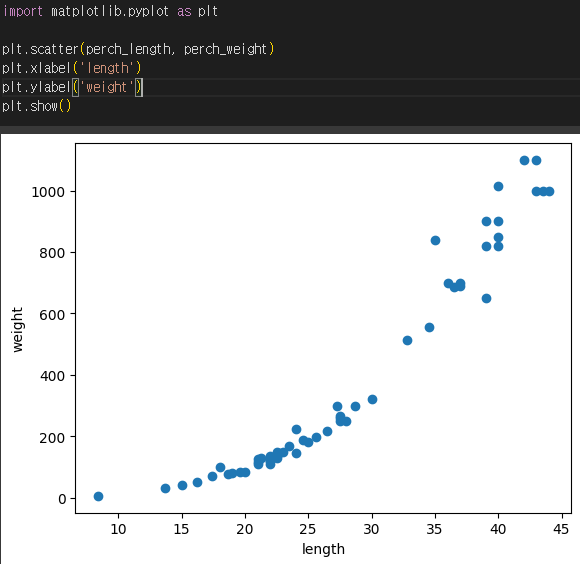
데이터의 형태를 눈으로 확인하기 위해 산점도를 그립니다. 하나의 특성을 사용하기 때문에 특성을 x, 타깃을 y 축에 놓습니다.
훈련 세트와 테스트 세트 분리

사이킷런에 사용할 훈련 세트는 2차원 배열이어야 합니다. perch_length가 1차원 배열이기 때문에 이를 나눈 train_input과 test_input도 1차원 배열입니다. 따라서 1차원 배열을 2차원 배열로 바꾸는 작업이 필요합니다.
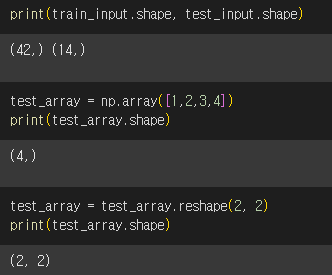
원소가 4개인 1차원 배열(4, )을 원소가 2개인 2차원 배열(2, 2)로 바꾸는 작업을 예제로 수행했습니다.
reshape( )
- 넘파이 배열의 크기를 바꿀 수 있는 매서드
- 크기가 바뀐 새로운 배열을 반환할 때 지정한 크기가 원본 배열의 원소 개수와 다르면 에러 발생
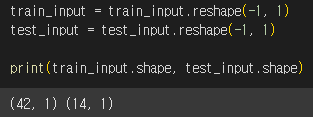
이번에는 train_input과 test_input을 2차원 배열로 바꿔보겠습니다. reshape( ) 매서드의 크기에 -1을 지정하면 나머지 원소를 모두 채우라는 의미입니다.
2. 결정계수()
K-최근접 이웃 회귀 알고리즘 구현
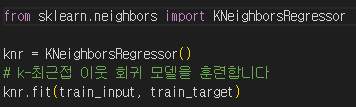
사이킷런에서 k-최근접 이웃 회귀 알고리즘을 구현한 클래스는 KNeighborsRegressor 입니다. 회귀 모델을 호출하고 훈련을 시켰습니다. 아래에서 테스트 세트의 점수를 확인해보겠습니다.
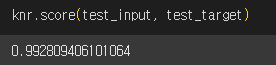
회귀의 경우에 모델 평가가 어떻게 이루어질까요? 분류 모델의 경우에는 테스트 세트에 있는 샘플을 정확하게 분류했는지를 판단했습니다. 하지만 회귀에서는 정확한 숫자를 맞춘다는 것은 거의 불가능합니다. 예측하는 값이나 타깃 모두 임의의 수치이기 때문입니다.
따라서 회귀의 경우에는 결정계수()로 모델의 성능을 평가합니다.
이번에는 정확도 이외에 다른 값으로 모델의 성능을 확인해보겠습니다.
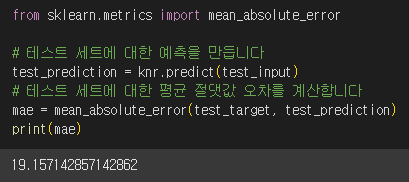
sklearn.metrics
- mean_absolute_error : 타깃과 예측값의 절댓값 오차를 평균하여 반환
결과에서 예측이 평균적으로 19g 정도 타깃값과 다르다는 것을 알 수 있습니다.
이번에는 훈련세트를 사용해서 모델을 평가해보겠습니다.
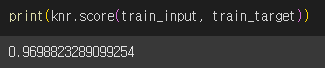
이상한 점을 발견했습니다.
모델을 훈련세트에 훈련하면 훈련 세트에 잘 맞는 모델이 만들어집니다. 따라서 테스트 세트로 평가하는 것보다 훈련세트로 평가하는 것이 보통 더 좋은 점수가 나와야 합니다.
- 과대적합:
훈련 세트에서 점수가 좋았는데 테스트 세트에서는 점수가 나쁘다면 모델이 훈련세트에 과대적합되었다고 말합니다.
- 과소적합:
훈련세트보다 테스트 세트의 점수가 높거나 두 점수가 모두 너무 낮은 경우는 모델이 훈련 세트에 과소적합되었다고 말합니다.
현재 학습된 모델은 훈련 세트보다 테스트 세트의 점수가 높으니 과소 적합압니다. 과소 적합이 일어나는 원인은 훈련세트와 테스트 세트의 크기가 매우 작기 때문입니다.
이 문제를 해결하기 위해 모델을 좀 더 복잡하게 만들어보겠습니다. 즉, 훈련 세트에 더 잘 맞게 만들면 테스트 세트의 점수는 조금 낮아질 것입니다.
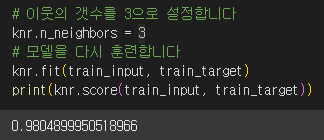
k-최근접 이웃 알고리즘으로 모델을 더 복잡하게 만드는 방법은 이웃의 개수 k를 줄이는 것입니다.
n_neibors
- k-최근접 이웃 알고리즘의 이웃의 개수를 변경하는 매서드
- 기본값은 5
k 를 5에서 3으로 줄이고 모델을 다시 훈련했습니다. k의 값을 줄였더니 훈련 세트의 결정계수가 높아졌습니다.
테스트 세트의 점수도 확인해보겠습니다.
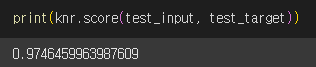
테스트 세트의 점수가 훈련 세트의 점수보다 낮아졌으므로 과소적합 문제를 해결한 것으로 보입니다👏🏻👏🏻
다음 장에서는 선형 회귀에 대해서 학습해보겠습니다~!
자료출처: 한빛미디어
