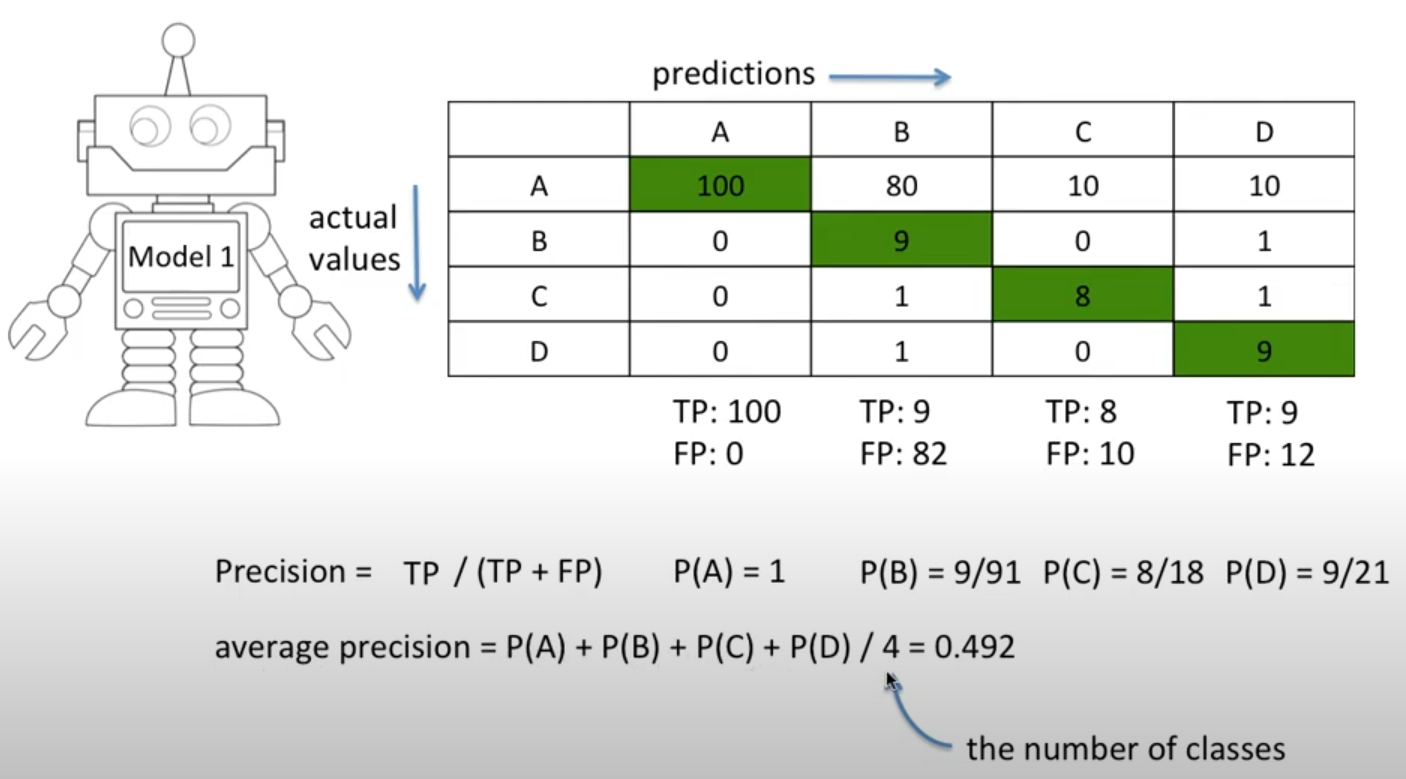
이진 분류 머신러닝 모델에서 성능지표로 쓰이는 accuracy, precision, recall, f1 score 개념을 다중분류 모델에서도 사용할 수 있을까?
다중분류 모델에서 성능 측정하는 방법에 대해서 알아보고자 한다.
1. 기본 개념
1) TP: True Positive
- A,B,C,D로 예측해서 실제로 맞은 것

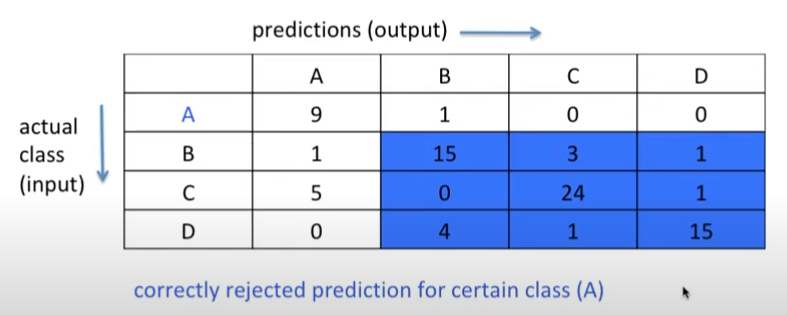
2) TN: True Negative for A
- A가 아니라고 예측해서 실제로 맞은 것
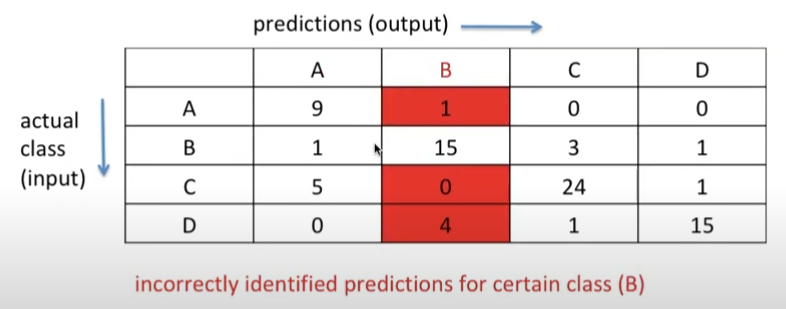
3) FP: False Positive for B
- B라고 예측해서 실제로 틀린 것
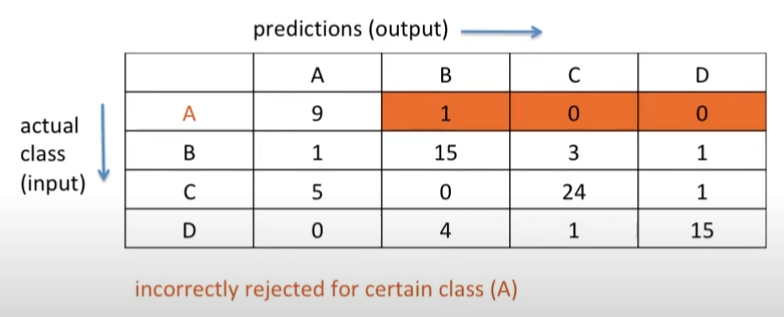
4) FN: False Negative for A
- A가 아니라고 예측해서 실제로 틀린 것
2. 성능지표
각 클래스별 지표의 평균을 최종 성능 지표로 사용한다.
1) Accuracy:
- 전체 데이터 중에서 올바르게 예측한 비율
- balanced data일 경우 accuracy 성능이 결과를 적절하게 반영해준다. 즉 클래스별 개수가 비슷하면 accuracy 성능이 정확하게 나온다.

2) F1 score:
- recall과 precision의 조화 평균
- imbalanced data의 경우 F1 score가 수행 결과를 적절하게 반영해준다.

3) Precision:
- 맞다고 예측한 데이터 중에서 실제로 맞은 비율
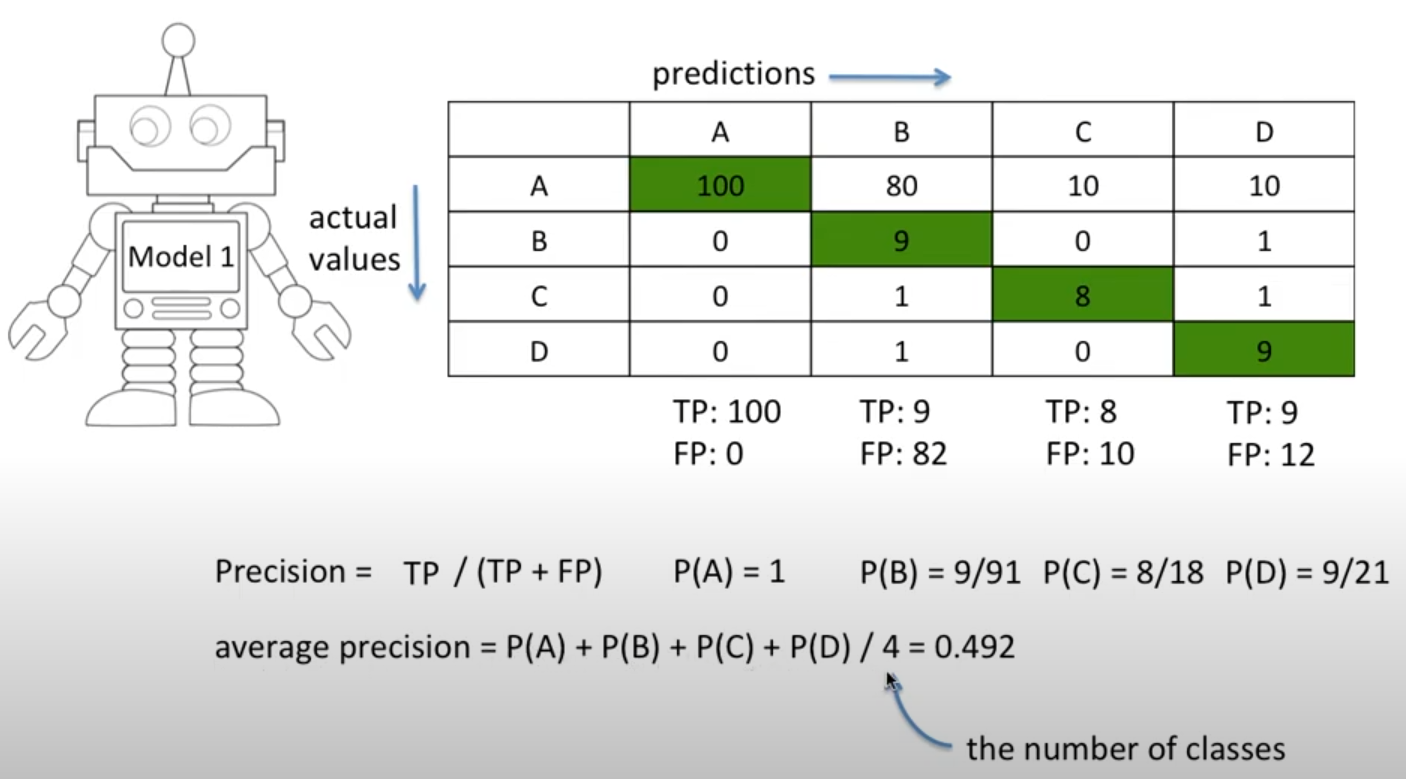
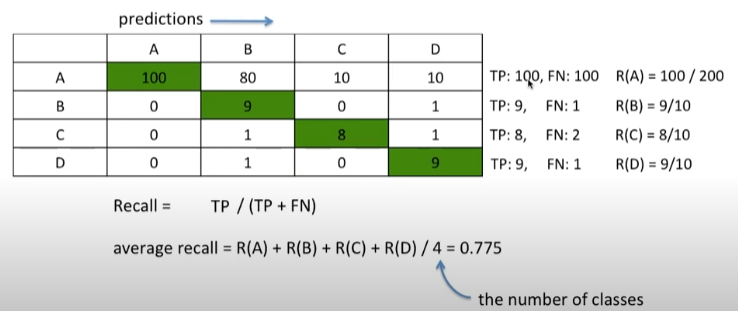
4) Recall:
- 실제로 맞는 데이터 중에서 모델이 맞다고 예측한 비율
학습 자료의 출처는 아래 유튜브 영상입니다.
https://www.youtube.com/watch?v=8DbC39cvvis

머신러닝 딥러닝 학습기록