📌 목차
- 프로젝트 주제
- 기획의도
- 선행자료 조사
- 데이터 수집 및 특성
- 모델
- 확장성
1. 프로젝트 주제
- 멀티 모달을 활용한 영상(영화)장면 검색 모델
- 텍스트로 원하는 장면을 검색하면 해당하는 장면을 띄워주는 모델 구현
2. 기획의도
1) 기업과제
- 사이디라이트라는 기업에서 자체 OTT 플랫폼 내 '원하는 장면을 검색할 수 있는 서비스'를 함께 제공하고자 하는 목적으로 본 프로젝트를 제안함
2) 영상 데이터의 중요성 증대
- 전 세계 데이터의 비율에서 영상의 비율이 80%까지 증가한 만큼 영상 데이터의 중요도가 높아짐
- 영상 검색 기술의 고도화로, 인공지능이 영상을 실시간으로 이해하면 기술의 활용도가 높아짐
3) Pain-pint End-user
- 영상 레퍼런스 체크에 있어서 영상 검색 기술에 대한 니즈가 존재
- 영상 편집자들의 경우, 영상 편집에 걸리는 시간이 실제 영상 시간의 몇십배인 경우가 多
본 프로젝트의 기술이 상용화 된다면 영상 편집 시간을 대폭 단축할 수 있을 것으로 예상
3. 선행자료 조사
- Google Video Intelligence API
- 문맥을 고려하지 않고 객체들을 독립적으로 검색하는 장면검색 모델 => 키워드가 아닌 문장으로 장면을 검색할 수 있는 모델을 만드는 것이 필요함- 객체들의 독립적 집합이 아닌 유기적 결합을 고려한 장면 검색 모델로 방향 설정
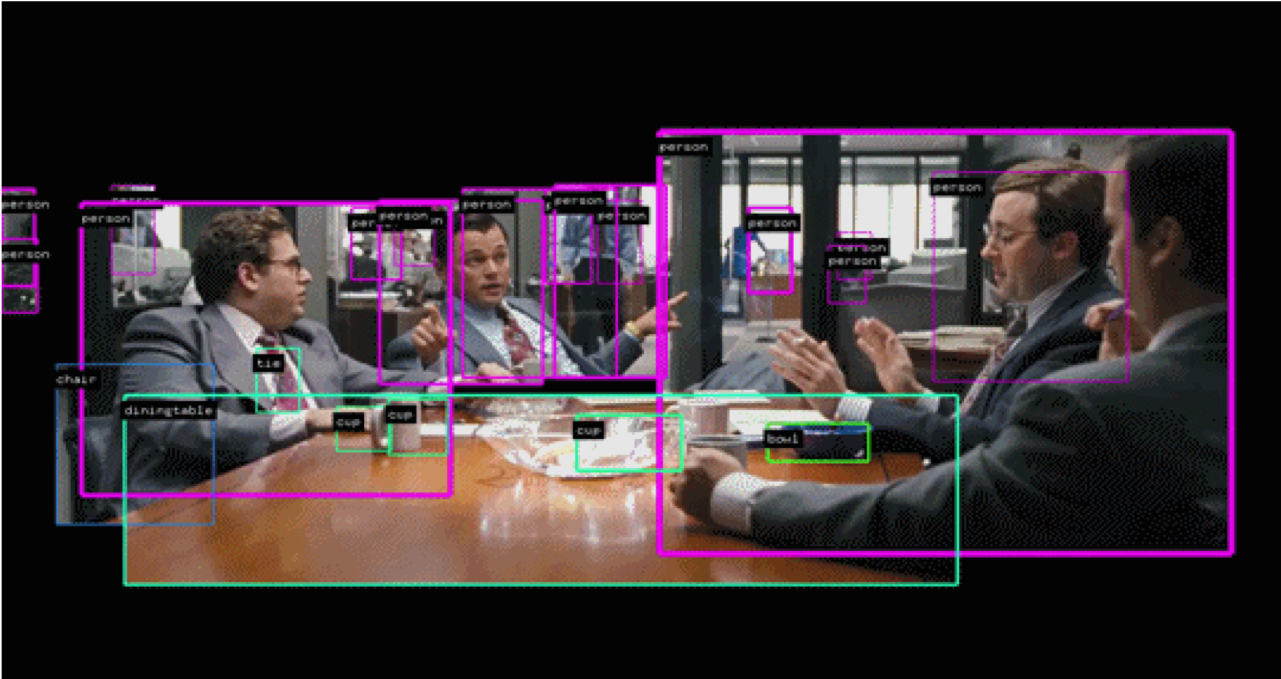
4. 데이터 수집 및 특성
📌 Action Dataset: UCF-101

- UCF-101은 YouTube에서 수집한 비디오 중 액션 데이터 세트로, 101개의 액션 카테고리로 구성
- 인간 대 물체 상호 작용, 포즈, 인간 대 인간 상호 작용, 악기 연주, 스포츠 특성을 가진 행동 비디오를 포함하고 있음
- 총 비디오수는 13320개가 있고 훈련데이터셋과 시험 데이터셋의 비율은 약 3:1 입니다.
📌 Image Dataset for Object Detection

YTBB
- 이미지의 객체를 인식하고, 시간에 따른 객체의 이동 변화를 연구하기 위한 데이터셋
- 24만개 동영상에서 23개 오브젝트에 대해 백만개 이상의 사각 영역 좌표를 표시
VPCD
- 데이터 세트는 얼굴 수준의 주석이 있는 기존 비디오 데이터 세트를 기반으로 구축
- 신체 부호를 추가하고 주석을 달며 음성 발화에 주석을 달 수 있음
📌 Sound Dataset
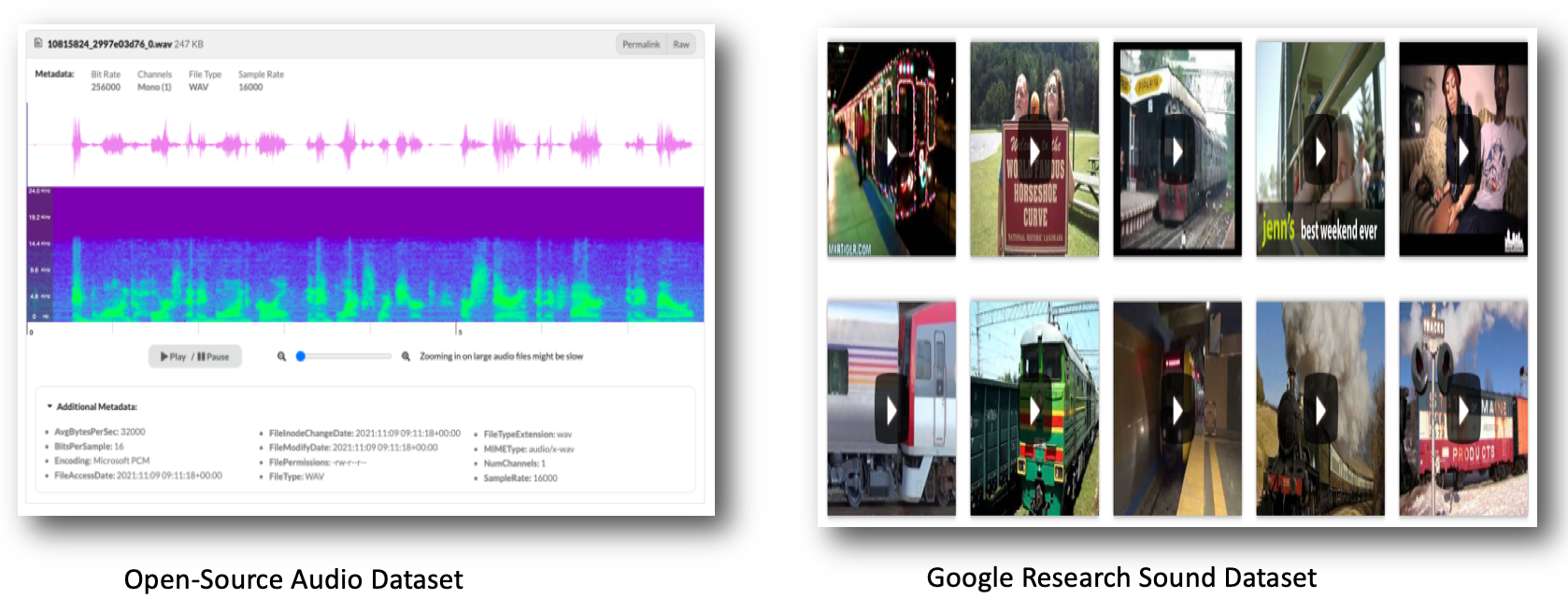
Open-Source Audio Dataset
- 오픈 소스 데이터: 사운드의 이미지화된 데이터가 있고 for vector화
- 구글 리서치 사운드 데이터셋: 각 사운드의 샘플 비디오와 소리 녹음 데이터
Google Research Sound Dataset
- 각 사운드의 샘플 비디오와 소리 녹음 데이터
📌 Multi-Modal
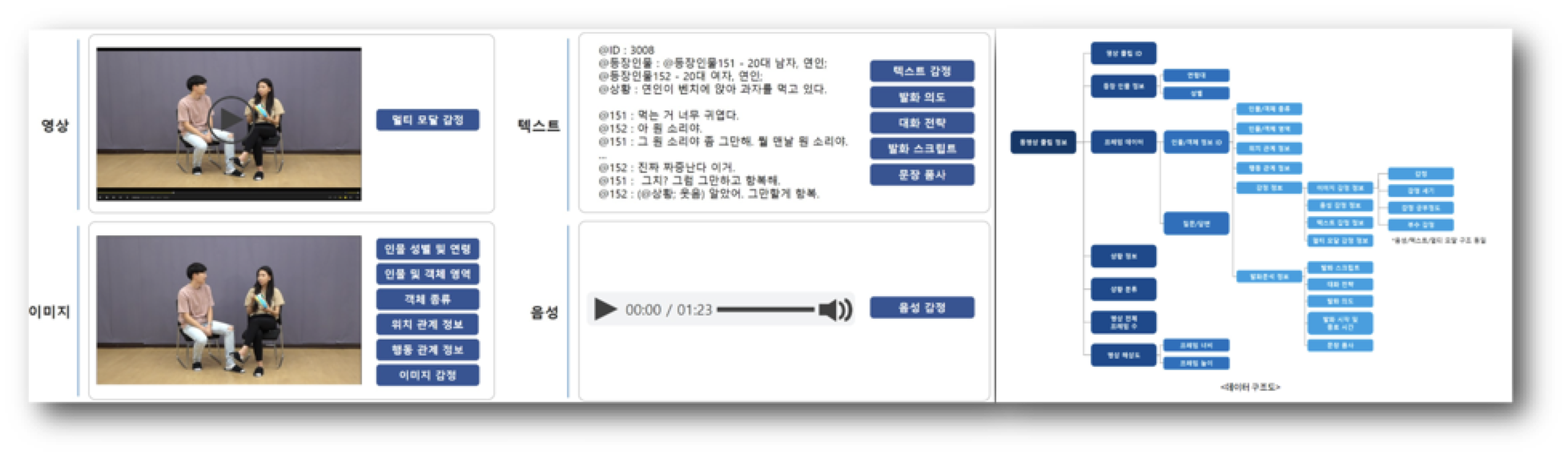
Ai-Hub 멀티 모달 학습 데이터
- 영상, 이미지, 텍스트, 음성을 장면에 따라 라벨링해 묶어놓은 데이터셋
5. 모델
Type 1 ≈ Google Video Intelligence
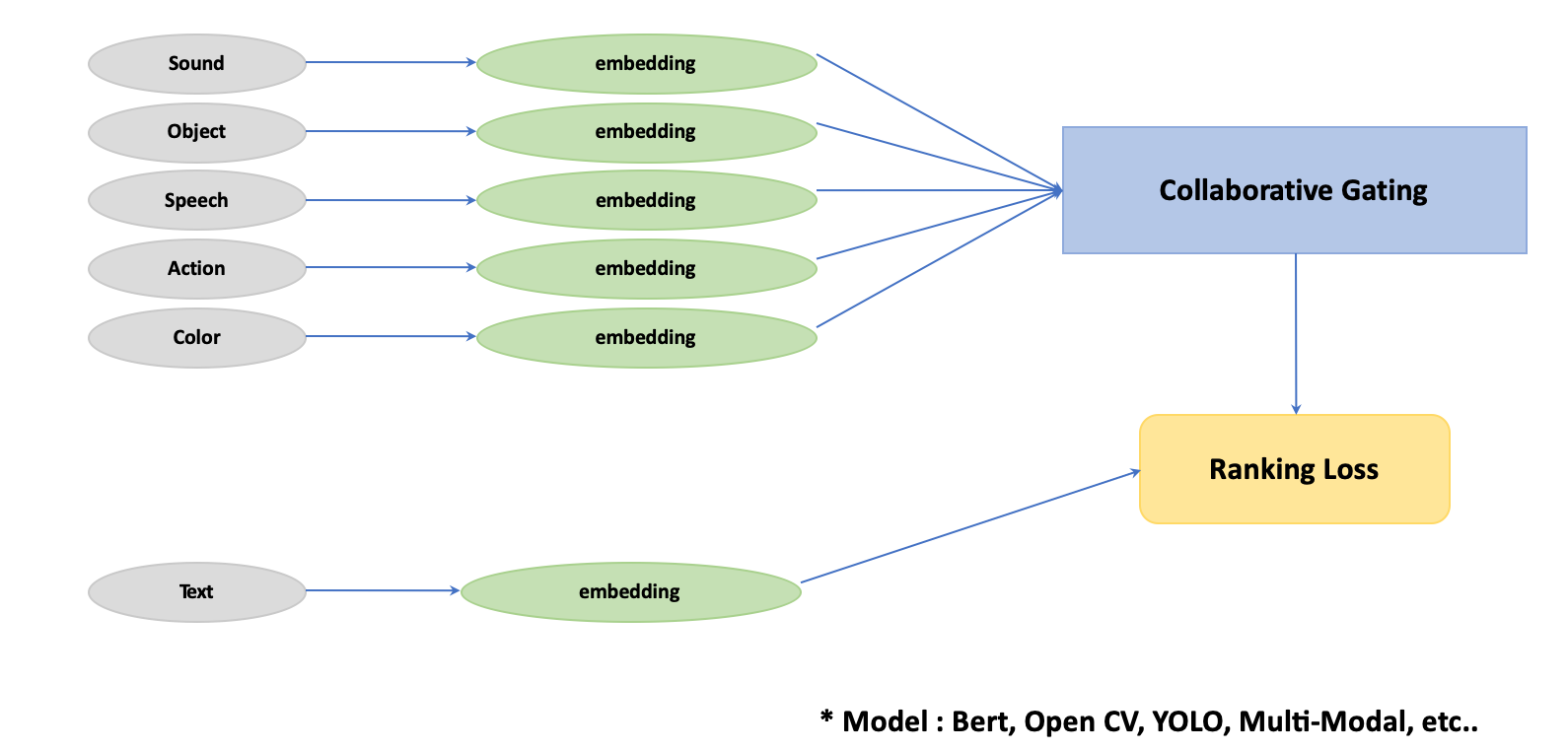
- 사운드, 오브젝트, 스피치, 액션, 색감 등을 각각의 모델을 통해 임베딩한다.
- 임베딩된 값을 collaborative gating을 통해서 input text query문과 유사도 분석을 한다.
- 가장 유사도가 높은 장면을 출력해준다.
- 성능의 지표는 랭킹로스로 판단 가능하다.
Type 2 ≈ End to End Task Model
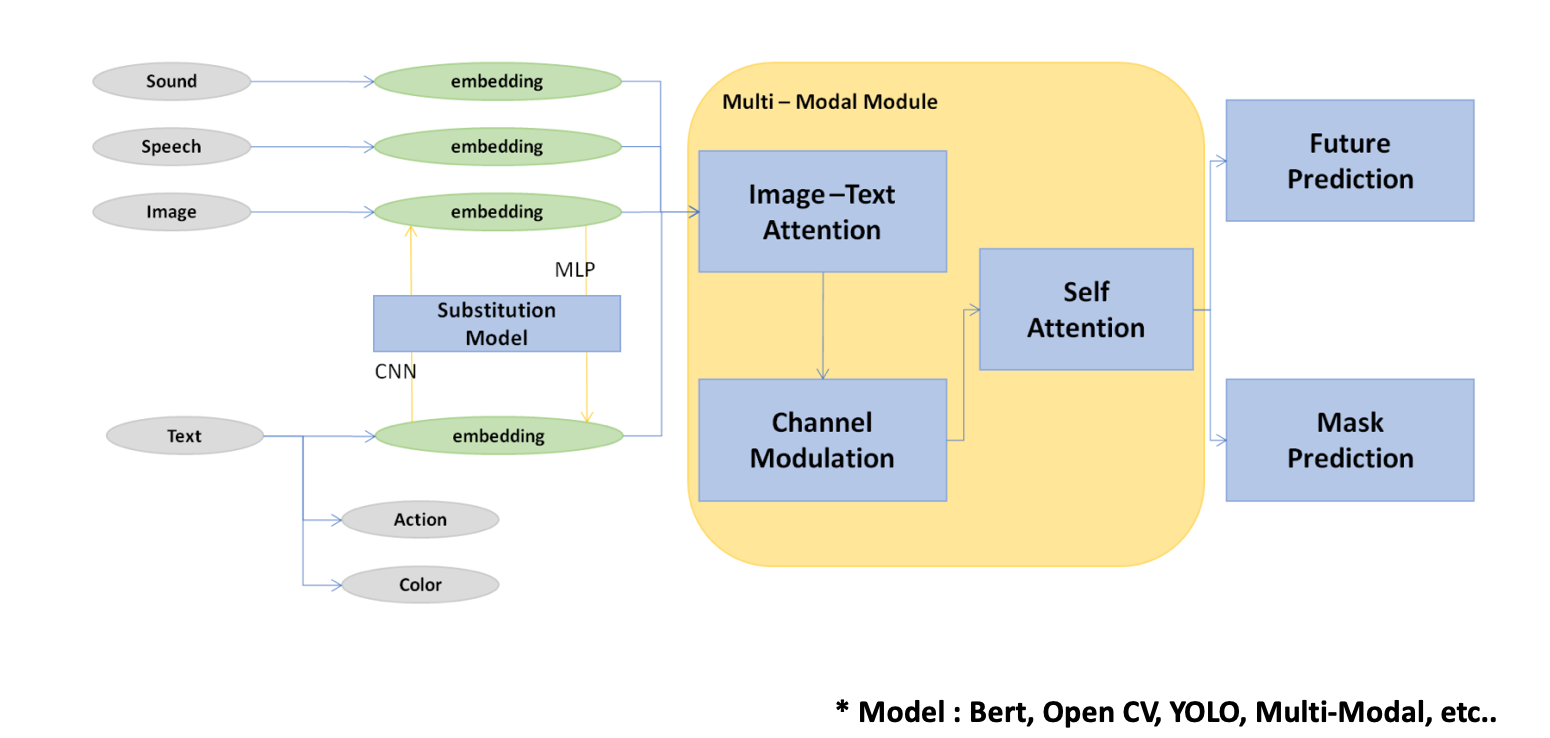
- Type 1을 => Type 2로 디벨롭
- 사운드, 스피치, 이미지와 텍스트를 각각의 모델을 통해서 임베딩
- 이 때, 텍스트 임베딩에 액션, 컬러는 태스크를 부여해서 모델의 정확도를 높여줌
- 이미지와 텍스트 임베딩을 치환 모델을 통해 묶어주고, 멀티모달 모델을 통해 장면 검색을 수행한다.
6. 확장성
- 사이디라이트 장기목표
-장면 검색 기술을 활용하여 나레이션 및 자막 자동 생성
-시청각 장애인을 위한 영상 재생 서비스 제공 - 타깃 확장
-OTT 플랫폼 내 장면 검색 기술 도입
-인터넷 강의 시청시 특정 장면을 주제나 상황으로 검색
-강의 라벨링 자동화 - 수익 모델 고려
-특정 장면에서 등장하는 상품이나 ost 음원을 커머스 사업과 연계 (SK Scene Discovery) - 도메인 전환
-CCTV 장면인식을 통한 범죄 예방 및 검거

머신러닝 딥러닝 학습기록