2014년 발표된 VGGNet은 컨볼루션 신경망(ConvNet)의 깊이가 모델 성능에 미치는 영향을 체계적으로 연구한 선구적인 논문이다. 당시 ImageNet과 같은 대규모 데이터셋과 GPU의 발전으로 딥러닝이 컴퓨터 비전 분야에서 획기적인 성과를 내고 있었으며, VGG는 ILSVRC-2014에서 top-5 error rate 7.3%로 2위를 차지한 모델이다.
Abstract
- 이 논문은 대규모 이미지 인식을 위해 합성곱 신경망(ConvNet)의 깊이가 성능에 미치는 영향을 조사한 내용이다.
- 3×3의 작은 합성곱 필터를 사용하였으며, 16~19개의 가중 레이어를 가진 네트워크를 통해 기존보다 성능을 크게 향상시킬 수 있음을 보여준다.
1. Introduction
아키텍처의 혁신
- 작은 필터 크기: 모든 컨볼루션 레이어에서 3×3 크기의 매우 작은 필터를 사용
- 네트워크 깊이 확장: 컨볼루션 레이어를 점진적으로 추가하여 네트워크의 깊이를 늘림
- 일관된 설계 원칙: 작은 필터 크기를 일관되게 유지하면서 깊이만 변화를 줌
주요 특징
- 기존 AlexNet의 구조를 개선하여 더 높은 정확도 달성
- 단순하고 균일한 아키텍처로 설계되어 구현과 이해가 용이
- 다른 데이터셋에도 잘 일반화되는 특성 보유
성과
- ILSVRC 2014 분류 및 지역화 부문에서 최고 수준의 정확도 달성
- 다양한 이미지 인식 태스크에서 우수한 성능 입증
- 전이학습에도 효과적임을 확인
의의
- 신경망의 깊이가 성능 향상에 직접적인 영향을 미친다는 것을 실험적으로 입증
- 단순하고 규칙적인 구조로도 뛰어난 성능을 달성할 수 있다는 것을 보여줌
- 현대 딥러닝 아키텍처 설계의 기초가 되는 중요한 통찰 제공
2. ConvNet Configurations
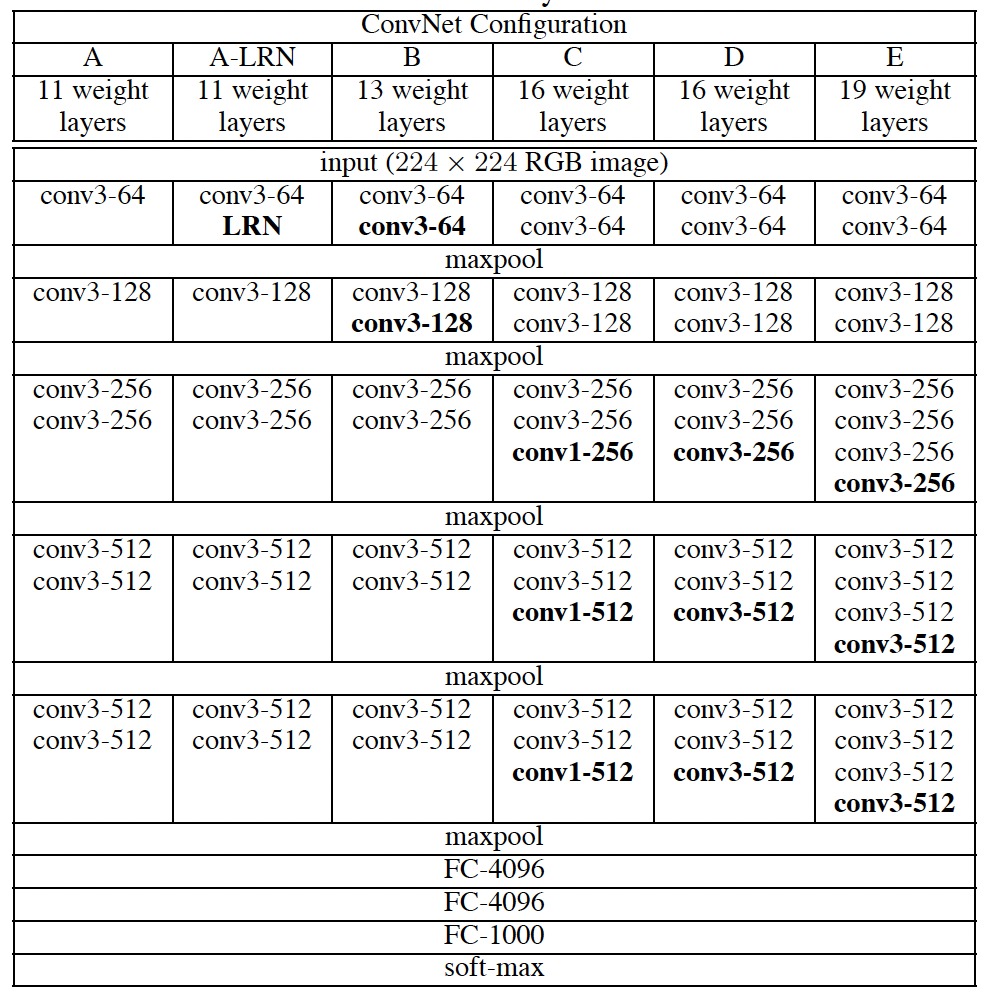
2-1. Architecture
입력 처리
- 224×224 RGB 이미지 입력
- 전처리: RGB 평균값을 픽셀별로 차감
- 일관된 작은 필터 크기(3×3) 사용
- stride=1로 고정하여 공간 정보 보존
네트워크 구조
입력층(224×224 RGB)
↓
다중 Conv 층 (3×3 필터, stride=1)
+ Max Pooling (2×2, stride=2)
↓
FC 층 (4096)
↓
FC 층 (4096)
↓
출력층 (1000 클래스)
+ Softmax2-2. Configurations
다양한 네트워크 구성
- A부터 E까지 다양한 깊이의 모델 실험
- A: 11층 (8 Conv + 3 FC)
- E: 19층 (16 Conv + 3 FC)
- 채널 수: 64에서 512까지 점진적 증가
2-3. Discussion
작은 필터 크기 사용의 장점
-
수용영역(Receptive Field) 확장
- 3×3 필터 2층 = 5×5 수용영역
- 3×3 필터 3층 = 7×7 수용영역
-
파라미터 효율성
- 3×3 필터 3개층: 27C² 파라미터
- 7×7 필터 1개층: 49C² 파라미터
- 약 45% 파라미터 감소 효과
-
비선형성 강화
- 여러 층의 ReLU 활성화 함수 적용
- 더 복잡한 특징 학습 가능
3. Classification Framework
3.1 Training
- 훈련은 Krizhevsky et al. (2012)의 방식을 따르며, mini-batch gradient descent와 momentum을 사용
- 학습 속도 조정, weight decay, dropout을 통해 정규화를 수행
최적화 파라미터
{
"batch_size": 256,
"momentum": 0.9,
"weight_decay": 5e-4,
"dropout_rate": 0.5,
"initial_learning_rate": 1e-2
}학습 과정
- 미니배치 경사하강법 + 모멘텀 사용
- 74 에포크 (370K 반복) 동안 학습
- 검증 정확도 정체 시 학습률 1/10로 감소
네트워크 초기화
- 얕은 네트워크(A 구조) 먼저 학습
- 깊은 네트워크는 얕은 네트워크의 가중치로 일부 초기화
- 처음 4개 Conv layer와 마지막 3개 FC layer 초기화
- 중간층은 랜덤 초기화
입력 이미지 처리
- 기본 크기: 224×224
- 스케일 파라미터 S 도입
- S = 256 (기본)
- S = 384 (고해상도)
데이터 증강 기법
- 랜덤 크롭
- 수평 뒤집기
- RGB 색상 변화
멀티스케일 학습
class TrainingScales:
SINGLE_SCALE = {
"base": 256,
"high_res": 384
}
MULTI_SCALE = {
"range": [Smin, Smax],
"sampling": "random"
}3.2 Testing
- 테스트 시, 입력 이미지는 일정한 크기로 조정되고 네트워크는 전 이미지에 대해 밀집(dense) 평가를 수행
- 다중 크롭(multi-crop) 평가와의 차이를 비교하며 두 방식의 장점을 결합하여 성능을 높이는 방법을 제시
네트워크 변환 과정
-
FC층을 Conv층으로 변환
- 첫 FC층 → 7×7 Conv층
- 나머지 FC층 → 1×1 Conv층
-
Fully-Convolutional 네트워크 적용
class FullyConvolutionalNet: def convert_fc_to_conv(self): """FC층을 Conv층으로 변환""" def forward(self, image): """전체 이미지에 대해 밀집 예측""" feature_maps = self.conv_layers(image) spatial_average = self.global_average_pooling(feature_maps) return spatial_average
앙상블 예측
- 원본 + 수평 뒤집기
- Soft-max 출력 평균
2. 다중 크롭 전략
class MultiCropTesting:
SCALES = 3
CROPS_PER_SCALE = 50 # 5x5 grid + 2 flips
TOTAL_CROPS = 150 # 3 scales × 50 crops-
Dense Evaluation
- 전체 이미지 처리
- 자연스러운 경계 조건
-
Multi-Crop Evaluation
- 더 정교한 샘플링
- 다양한 경계 조건
- 넓은 수용영역
3.3 Implementation Details
GPU 병렬화
class MultiGPUTraining:
def __init__(self, num_gpus):
self.num_gpus = num_gpus
def distribute_batch(self, batch):
"""배치를 GPU별로 분배"""
def aggregate_gradients(self, gradients):
"""GPU별 그래디언트 평균"""성능
- 4 GPU 시스템에서 3.75x 속도 향상
- 훈련 시간: 2-3주 (NVIDIA Titan Black GPU 4개 기준)
구현 특이사항
- Caffe 프레임워크 기반
- 주요 수정사항:
- 다중 GPU 지원
- 전체 크기 이미지 처리
- 다중 스케일 지원
데이터 병렬화 프로세스
class DataParallelTraining:
def forward_backward_pass(self, batch):
# 배치를 GPU별로 분할
sub_batches = self.split_batch(batch)
# GPU별 병렬 처리
gradients = []
for gpu_id, sub_batch in enumerate(sub_batches):
grad = self.process_on_gpu(gpu_id, sub_batch)
gradients.append(grad)
# 그래디언트 동기화 및 평균
return self.synchronize_and_average(gradients)4. Classification Experiments
4.1 Single Scale Evaluation
- 단일 크기의 입력 이미지를 통해 네트워크의 성능을 평가합니다. 깊이가 깊을수록 성능이 향상됨을 확인했습니다.
4.2 Multi-Scale Evaluation
- 다중 크기로 조정된 이미지를 사용하여 테스트를 수행하며, 성능이 더욱 향상됨을 확인합니다.
4.3 Multi-Crop Evaluation
- 다중 크롭 평가가 밀집 평가보다 성능이 약간 더 우수하며, 두 방식을 결합할 때 가장 좋은 성능을 낸다고 설명합니다.
4.4 ConvNet Fusion
- 여러 개의 ConvNet 모델의 출력을 결합하여 성능을 극대화하는 방법을 실험합니다.
4.5 Comparison with the State of the Art
- GoogLeNet 등 최신 모델과의 비교에서 VGGNet이 단일 네트워크 기준으로 더 우수한 성능을 보임을 보여줍니다.
5. Conclusion
- 네트워크의 깊이가 이미지 분류 정확도에 중요한 역할을 하며, 16-19층의 매우 깊은 구조가 기존의 성과를 뛰어넘는 성능을 보여줍니다.

머신러닝 딥러닝 학습기록