KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation (TACL 2021) paper review
paper review
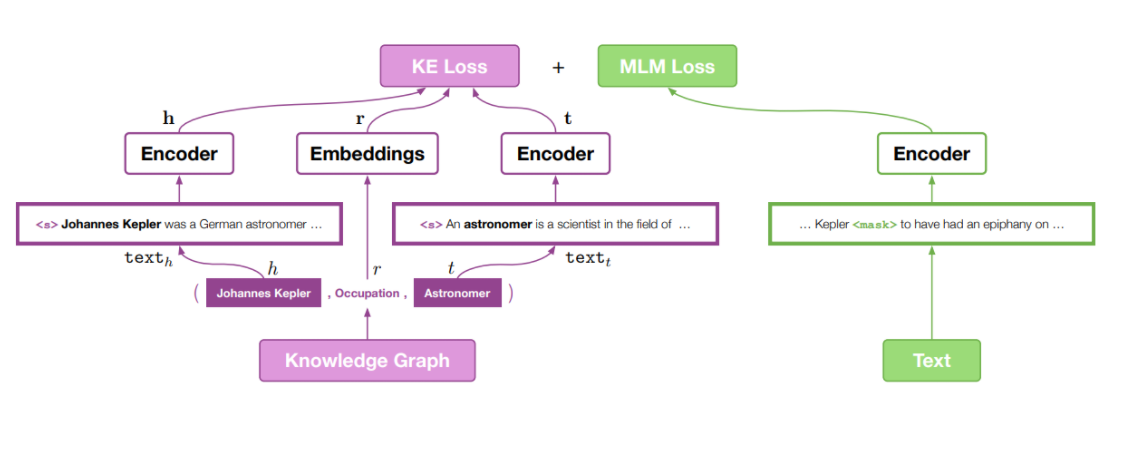
Contribution
-
Knowledge Embedding objective와 MLM objective를 jointly optimizing을 한
Knowledge-enhanced Pre-trained Language Model을 제안하였다.
-
text description을 encoding하여 entity embedding으로 사용하였다.
-
kepler를 훈련시키기 위해서는 (1)많은 양의 knowledge fact와 (2)aligned entity description과 (3)reasonable inductive-setting data split이 필요하다. 이를 충족시키기 위하여 Wikidata5M dataset을 도입하였다.
PLM vs KE
-
PLM
BERT나 RoBERTa 같은 Pre-trained language representation model(PLM)은 language modeling objective를 이용하여 large-scale unstructured corpora로부터 effective language representation을 배울 수 있지만 world fact는 잘 잡아내지 못한다는 단점이 있다.
-
KE
Knowledge embedding method는 structural fact를 continuous한 entity와 relation embedding에 잘 embed할 수 있다는 장점이 있지만, abundant textual information을 제대로 활용하지 못한다는 단점이 있다.
Entity description
- KE과 PLM의 gap을 메우기 위하여 entity description을 사용을 한다.
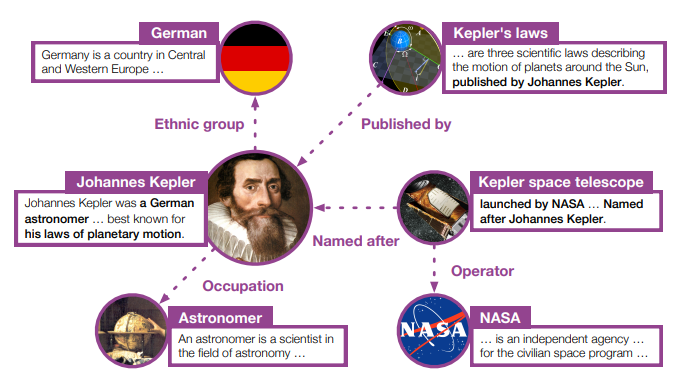
(entity name 아래 설명이 entity description)
- PLM encoder를 이용하여 text와 entity description을 unified semantic space에 encoding하고 KE objective와 MLM objective를 jointly optimizing하여 모델을 학습한다.
KEPLER's strengths
-
As a PLM
-
KEPLER는 KE objective를 이용하여 language representation에 factual knowledge를 integrate할 수 있다.
-
MLM objective를 이용하여 PLM의 강력한 language understanding ability를 내재한다.
-
KE objective는 model이 entity corresponding description으로부터 entity를 encode하기를 요구하므로 text로부터 knowledge를 추출하는 ability를 향상시킬 수 있다.
-
KEPLER는 model structure를 수정하지 않고 training objective만 추가를 한 것이므로 다른 PLM들처럼 NLP task들에 직접 적용이 될 수 있다
-
-
As a KE model
-
KEPLER는 MLM objective를 이용하여 entity description으로부터 abundant information을 잘 활용할 수 있게 된다
-
KEPLER는 inductive setting에서도 Knowledge Embedding을 수행할 수 있다.
-
KEPLER framework
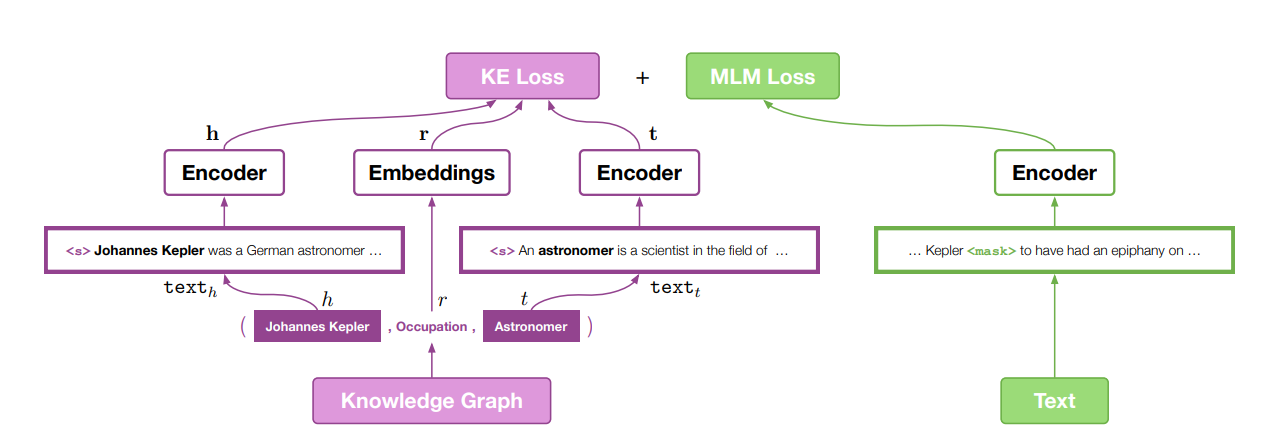
KE Loss와 MLM Loss는 각각 다른 mini batch에서 학습이 된다. 왜냐하면 우선 KE Loss 같은 경우는 entity descripton에서 학습이 되어야하는데 MLM Loss도 entity description에서 학습을 하게되면 기존에 English Wikipedia dataset에서 학습을 할 때보다 language representation ability가 떨어질 수 있기 때문이다.
Knowledge Embedding in KEPLER
-
Knowledge Embedding(KE)는 Knowledge Graph(KG)의 entity와 relation을 distributed representation으로 encode한 것이다
-
KEPLER에서는 stored embedding을 사용하는 대신에 entity를 corresponding text를 이용하여 vector로 encoding하여 사용한다. 사용될 수 있는 corresponding text에는 3가지가 있다.
-
Entity descriptions
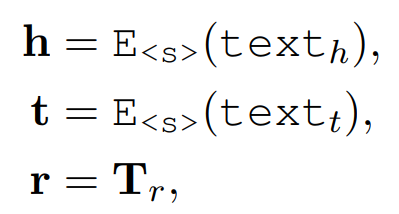
head entity 관련된 description text를 encoding하여 head entity의 embedding으로 사용한다. tail entity도 마찬가지의 방식으로 embedding을 구하여 사용한다. relation type embedding은 stored embedding을 사용한다. E<.s>의 <.s>는 text의 시작과 끝에 special token <.s>가 들어감을 의미한다. -
Entity and Relation Descriptions

head entity와 tail entity의 embedding은 앞의 Entity description을 이용하는 방법과 같은 방법을 사용하여 구하고 relation type의 embedding도 relation corresponding text description을 encode하여 구한다. -
Entkty Embeddings Conditioned on Relations
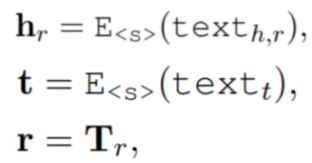
entity embedding에도 multiple aspects가 있는데 different relation이면 different embedding을 가질 것이라는 intuition에서 나온 방법이다. head entity와 relation entity의 text description을 concat한 뒤 encoding하여 head entity의 embedding으로 사용하는 방법이다.
-
Loss function
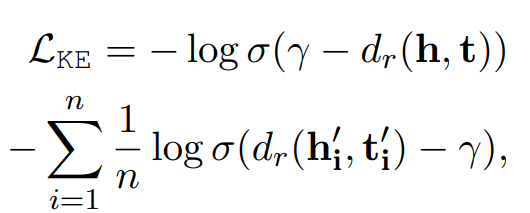
gamma는 margin을 의미, dr(h,t)는 score function을 의미한다. 여기서 사용되는 dr(h,t)는 TransE model에서 따온것으로 식은 아래와 같다.
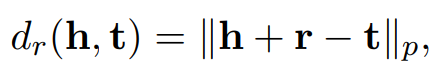
TransE 같은 경우에는 entity를 vector로 사용을 하는데 head entity와 relation type의 합이 tail entity와 유사해지도록 식이 설계가 되어 다음과 같은 score function이 나오게 된다. (h + r = t)
또한 loss function의 두번째 항의 hi'과 ti' 같은 경우는 negative sample을 의미한다. negative sampling을 이용하여 관련 있는 entity끼리는 가깝게, 관련 없는 entity끼리는 멀어지게 학습을 시킨다.
Experiment
-
NLP tasks
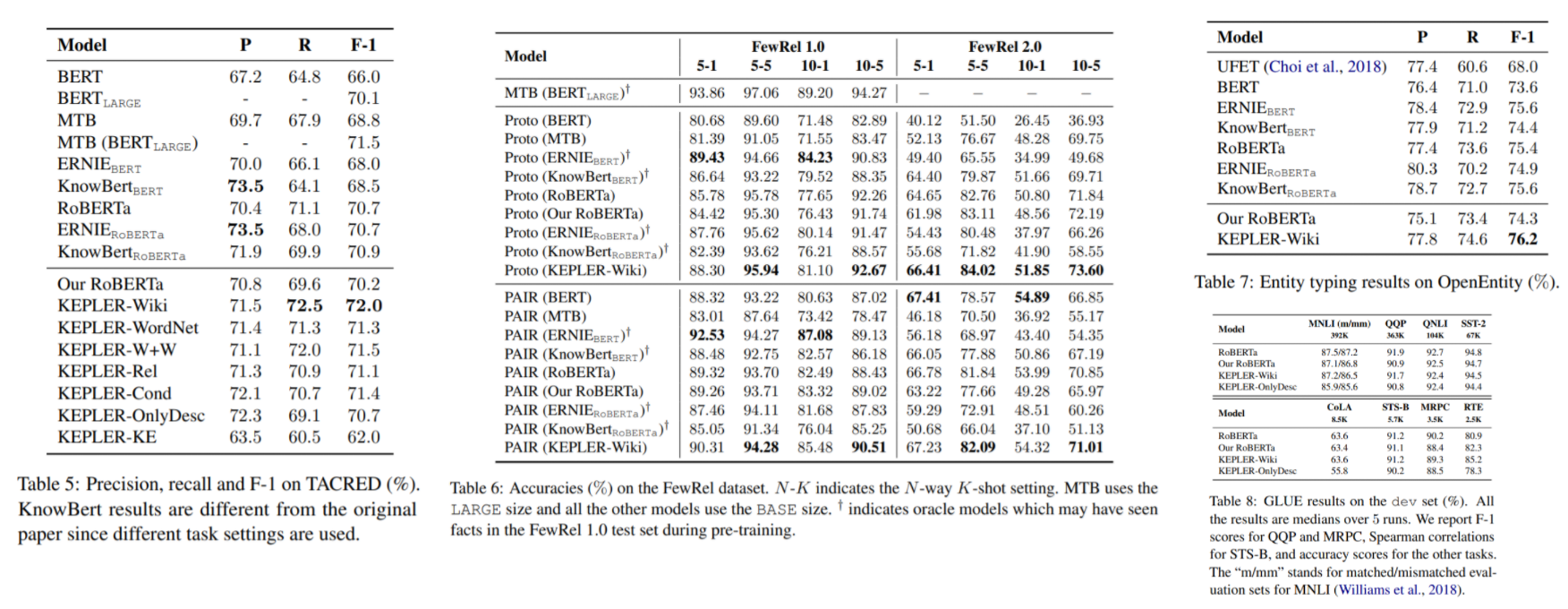
-
KE tasks
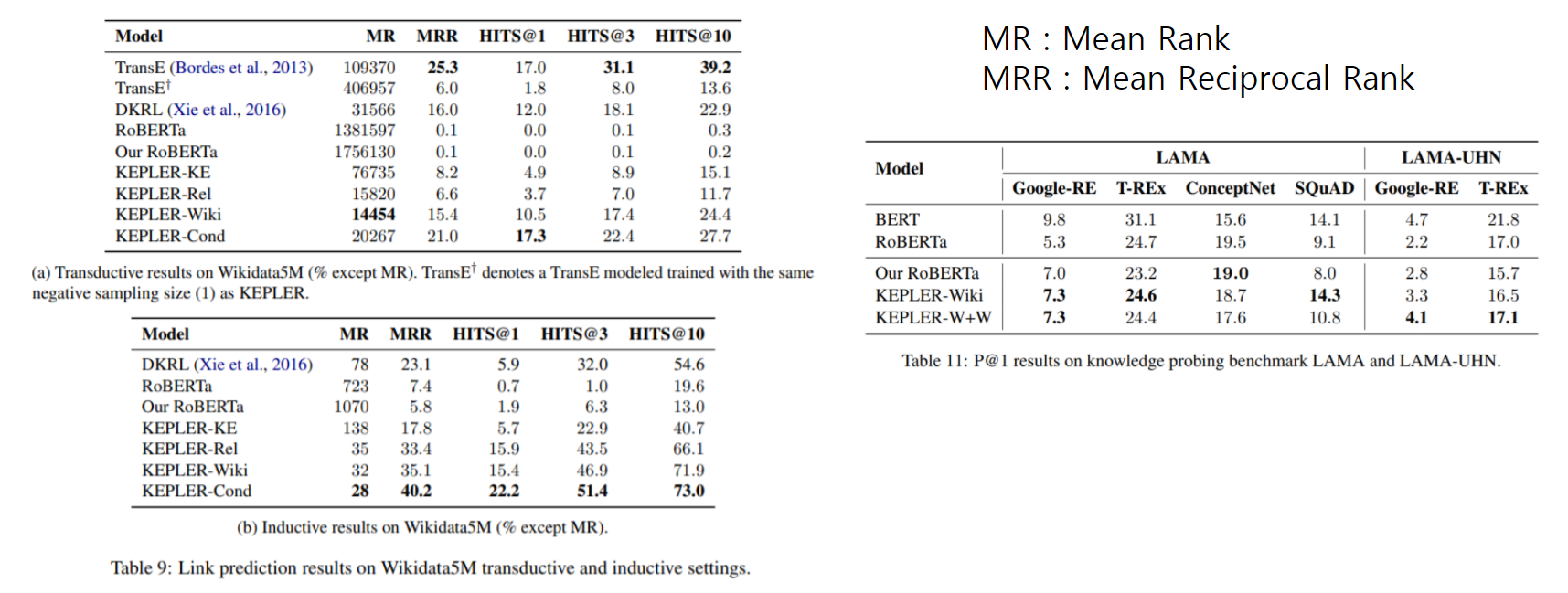
(a) table을 보면 TransE가 KEPLER-wiki보다 성능이 좋은 경우도 많은데 이는 KEPLER의 경우 model complexity 때문에 negative sample size를 1로 한 반면에, TransE 경우에는 negative sample size를 64 또는 그 이상으로 사용하였기 때문에 그럴 수 있다고 논문에서 말하고 있다. 또한 training epoch역시 KEPLER는 30번을 사용하였지만 TransE는 1000번을 사용하여 그러한 점에서 차이가 날 수 있다고 한다. 그래서 아래에 TransE+는 KEPLER처럼 negative sample size를 1만 사용을 한 것인데 그 경우에는 KEPLER가 훨씬 우수한 성능을 내는 것을 확인할 수 있다.
Conclusion
-
이 논문에서는 knowledge embedding과 pre-trained language representation을 위한 simple하지만 effective한 unified model KEPLER를 제안하고 있다.
-
KEPLER는 KE과 MLM objective를 이용하여 factual knowledge와 language representation을 같은 semantic space에 align을 시키도록 학습을 시켜서 많은 NLP와 KE application에서 좋은 성능을 거둔 것을 보여주고 있다.
