Contribution
-
contrastive learning에서의 false negative 문제에 주목하며, instance-level과 semantic-aware contrastive learning을 매개하는 incremental false negative detection method를 제안하였다.
-
제안하는 method에서 현존하는 self-supervised contrastive learning framework보다 좋은 성능을 보여주고 있다.
Background: Instance-level contrastive learning
-
최근 instance-level contrastive learning method가 supervised pre-training approach에서 sota를 달성하고 있지만, 이러한 instance-level contrastive learning framework는 high-level semantic을 학습하고 있지 못한다고 한다.
-
instance-level CL에서는 dataset에 있는 어떠한 두 sample에 대하여 sample들간의 semantically similarity를 고려하지 않고 모두 negative pair로 취급하여 멀어지도록 한다는 문제점이 있다.
-
이러한 문제를 false negative 문제라고 칭하고 있고, 이는 덜 effective한 representation model을 초래하게 된다.
-
이러한 현상은 아래 figure에서 볼 수 있듯이 class 개수가 많아질 수록 더 심하다고 한다.
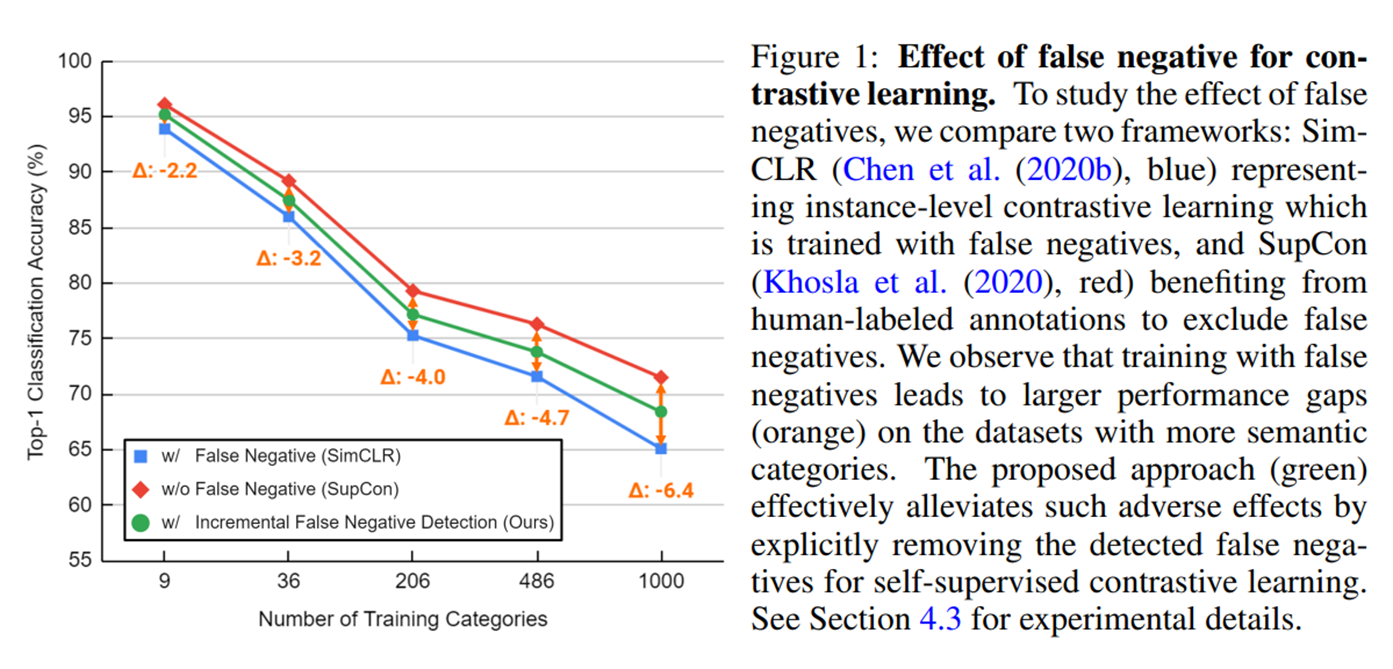
Background: Clustering for deep unsupervised learning
-
몇몇 unsupervised learning method들은 clustering technique들을 통하여 effective한 representation model을 구축하는 데에 benefit을 얻고 있다고 한다. 이러한 방식의 main idea는 cluster index를 pseudo label로 사용을 하여 supervised manner로 학습하는 것이다.
-
이 논문에서는 학습 초기 단계에 얻은 pseudo label들이 상대적으로 unreliable하고 그렇기때문에 학습 초반부터 이러한 pseudo label들을 full로 사용하는 것이 representation learning을 방해할 수 있음을 보여주고 있다.
-
이러한 문제를 해결하기 위하여 이 논문에서는 충분한 confidence를 가지는 pseudo label들만을 사용하는 clustering을 이용한 instance-level learning을 제안하였다.
Methodology: Instance-level Contrastive Learning
-
instance-level contrastive learning method는 하나의 sample을 나머지 다른 sample들과 구분하는 representation을 학습한다.
-
이러한 instance-level contrastive learning은 아래와 같은 loss를 통하여 학습될 수 있다.
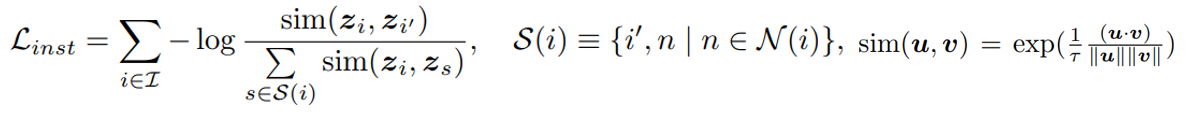
-
instance-level contrastive learning에서는 negative set에 어쩔 수 없이 anchor와 semantically similar한 sample들을 포함하게 된다. (false negative)
-
결과적으로, 이는 semantically similar한 sample들을 seperate하게 만들고 이는 좋은 semantic-aware representation에 있어서 suboptimal이라고 볼 수 있다.
Methodology: Incremental False Negative Detection
-
self-supervised contrastive learning으로 effective semantic-aware representation을 학습하기 위하여, 이 논문에서는 false negative를 탐지하고 삭제하는 method를 제안하였다.
-
여기서는 모든 training image i의 representation f(i)에 대하여 k-means clustering을 수행하여 feature들을 k개의 group으로 나누었다.
-
그리고 pseudo label yi는 가장 가까운 centroid에 의하여 assign된다.
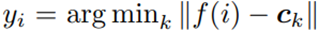
-
learning process에서 동일한 pseudo label을 가지는 두 image는 false negative pair로 취급된다.
-
한편, 이 논문에서는 early embedding space의 semantic structure가 덜 reliable하고 그렇기 때문에 reprsentation learning을 저해하는 noisy pseudo label을 생성해낼 수 도 있음을 관측하였다고 한다.
-
이러한 문제를 해결하기 위하여 학습 초기에는 오로지 높은 confidence를 가지는 sample들의 경우만 pseudo label을 사용하고 그렇지 않은 것들은 individual sample로 취급하여 사용을 하였다고 한다.
-
임의의 이미지 i가 있을 때, confidence는 image embedding f(i)가 belonging group의 centroid와는 가까울 수록, other centroids와는 멀 수록 높아지도록 설계하였고 다음과 같은 식으로 표현될 수 있다고 한다.
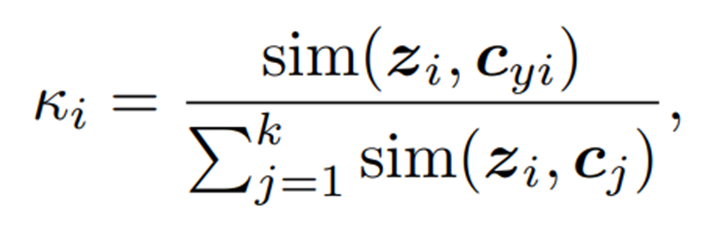
-
그리고나서 larger confidence를 기준으로 acceptance rate를 두어서 pseudo label을 assign하였다고 한다.
-
이러한 방식을 통하여 encoder는 더 잘 train되었고 embedding space의 semantic structure는 더 clear해졌다고 한다.
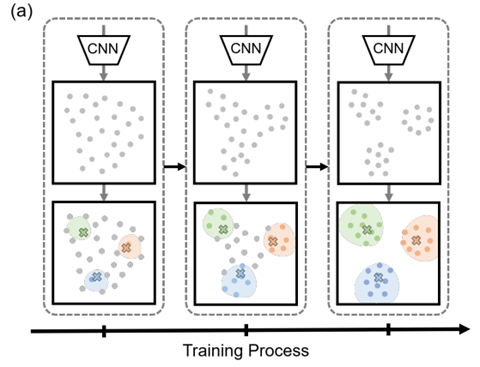
Methodology: Hierarchical semantic definition
-
unsupervised setting에서는 dataset의 정확한 class 개수를 알 수 없고 그렇기 때문에 다른 level의 granularity에 따라서 class 개수를 선택할 수 있다.
-
이 논문에서 제안하는 method의 flexibility와 robustness를 향상시키기 위하여 hierarchical clustering techniques를 도입하였다고 한다.
-
특히 서로 다른 granularity level의 false negative를 얻기 위하여 다른 cluster 개수로 k-means를 여러번 수행하였다고 한다.
-
objective function도 이에 맞춰서 서로 다른 level의 granularity로 생성된 false negative로 계산된 loss들의 average값을 사용하였다고 한다.
Methodology: Contrastive Learning without False Negative
-
pseudo label을 assign한 후에, 다음으로 할 것은 instance-level contrastive learning의 objective를 수정하는 것이다.
-
수정방법에 대해서 두 가지를 논의하였는데 각각 elimination approach와 additional approach이다.
- elimination approach
negative sample set으로부터 false negative를 제거하는 방법이다.
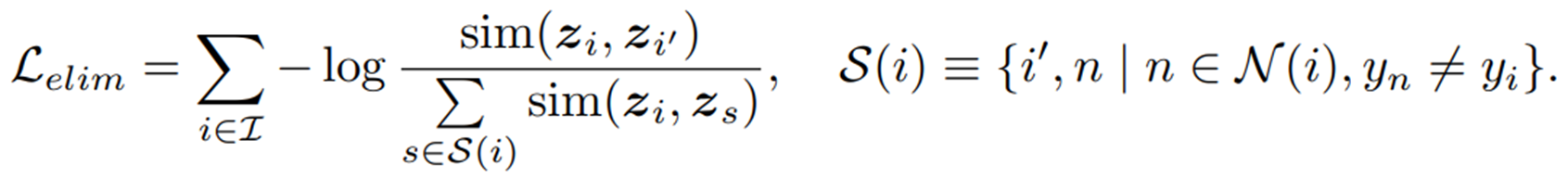
- elimination approach
-
attribution approach
false negative를 additional postive sample로 사용하는 방법이다.
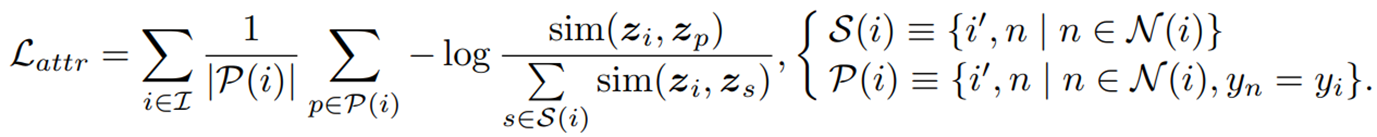
-
두 approach 다 negative set에서 false negative를 제거하였고 이를 anchor와 멀어지게 하는 것을 막았지만 unsupervised learning 특성상 noisy pseudo label을 포함할 수 밖에 없으므로 이에 대하여 tolerance가 적은 attribution approach보다 elimination approach를 사용하는 것이 더 안정적이라고 판단되어 결론적으로 elimination approach를 선택하였다고 한다.
Experiments
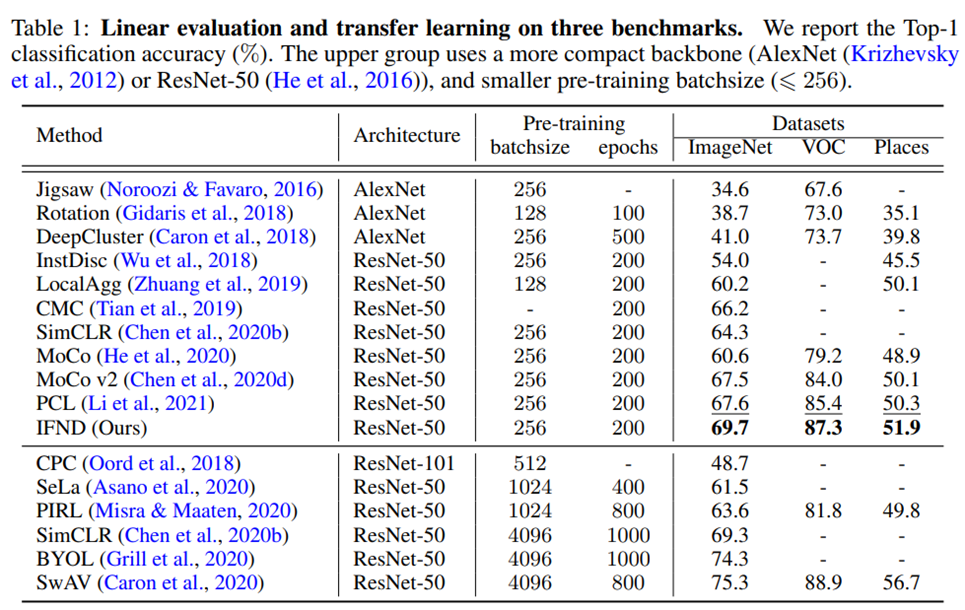
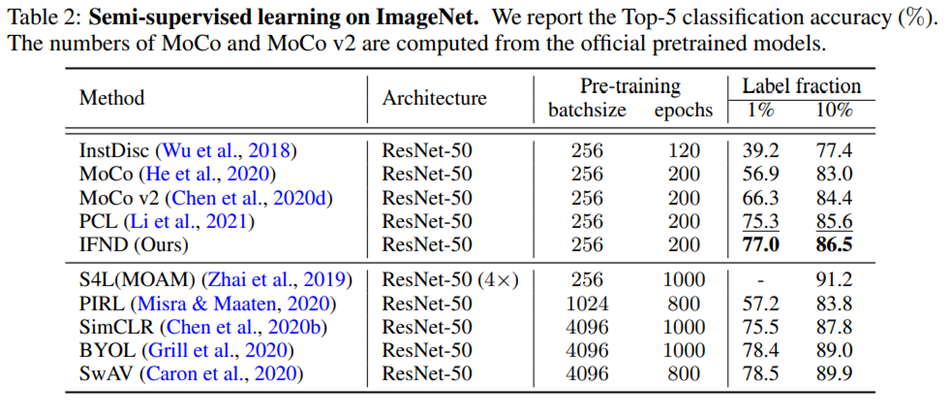
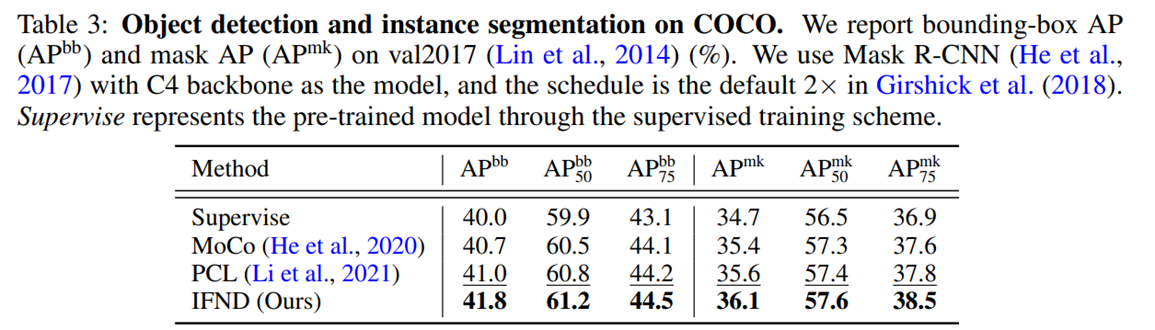
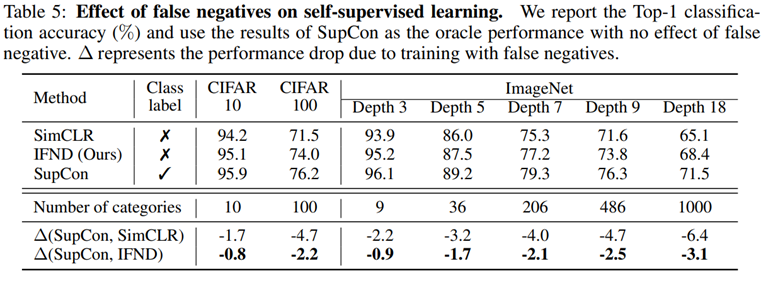
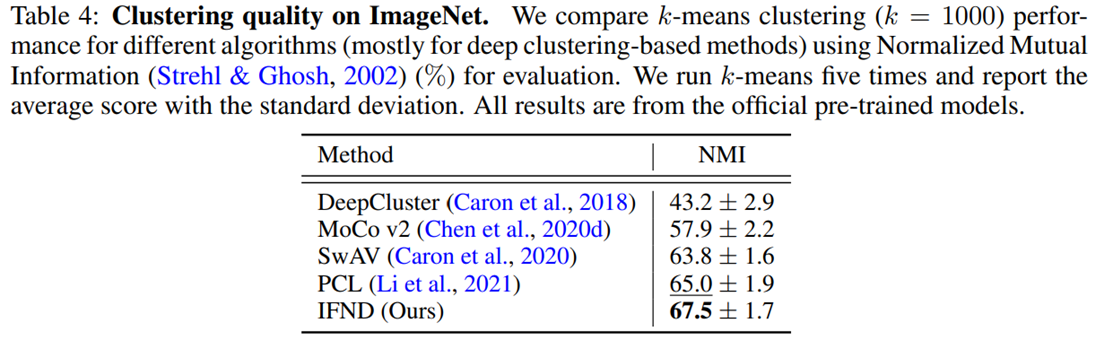

대부분의 task에서 좋은 성능을 보여주고 있다.
Visualization of Embedding space
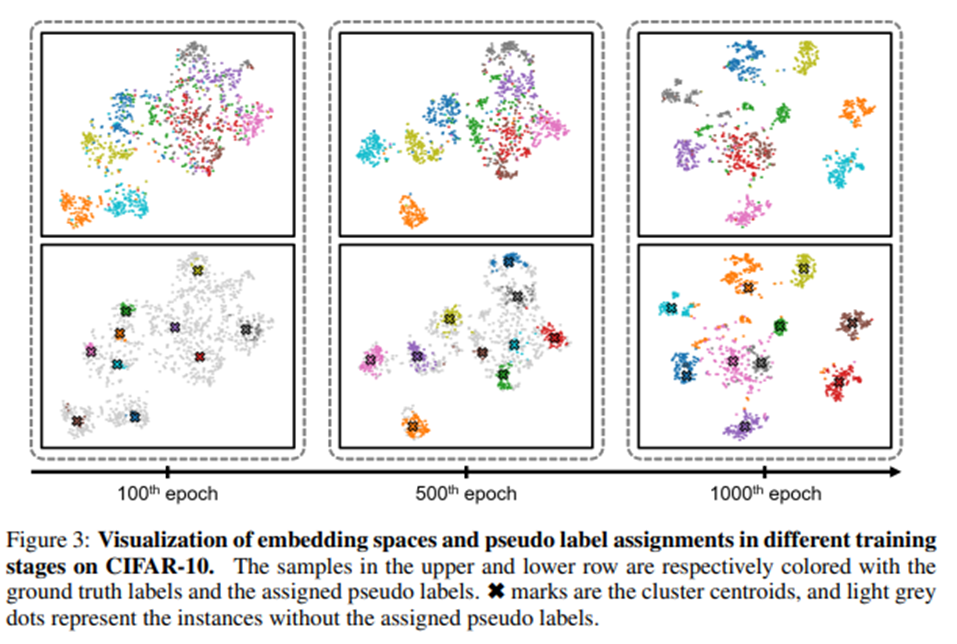
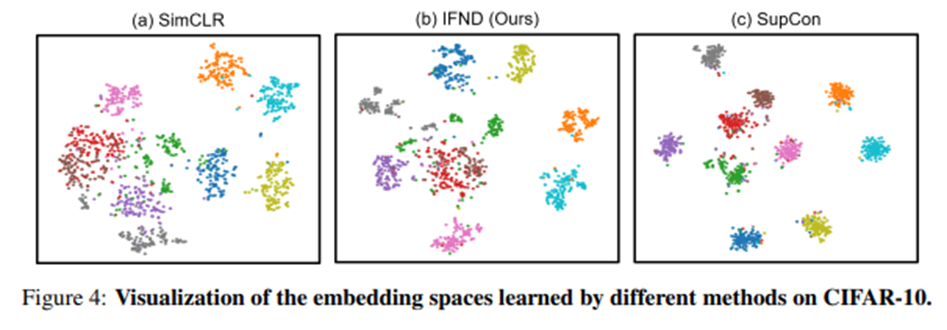
Figure 4에서 IFND가 supervised manner인 SupCon보다는 좋지 않지만 SimCLR보다는 좋은 distribution을 보여주고 있다.
Conclusion
-
이 논문에서는 self-supervised contrastive learning에서의 false negative의 undesired effect에 대하여 analyze하고 있다.
-
그리고 이를 해결하기 위하여 incremental false negative detection approach를 제안하여 trainig stage에서 false negative를 detect하고 remove하는 방식을 도입하였다.
-
여러 실험들에서 proposed framework의 effectiveness를 증명하고 있다.
