- 우리가 직접 CNN 모델을 만드는 방법을 아는 것은 중요하다.
- 이미 잘 만든 model이 있다.
- 해당 model을 쓰는 방법을 알아야 한다. 현재, 직접 만드는 것이 아닌 가져다가 쓰는 것이 트렌드라고 한다.
1. tesorflow 모델
- VGG16 모델을 불러와서 사용할 것이다.
- 1. 라이브러리 로딩 from tensorflow.keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions # 모듈 ,input, output 불러온거임 - 2. 모델 불러오기 model = VGG16(include_top=True, # VGG16 모델의 아웃풋 레이어까지 전부 불러오기 weights='imagenet', # ImageNet 데이터를 기반으로 학습된 가중치 불러오기 input_shape=(224,224,3) # 모델에 들어가는 데이터의 형태 ) - 3. model.summary() <출력> Model: "vgg16" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 224, 224, 3)] 0 block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 block1_conv2 (Conv2D) (None, 224, 224, 64) 36928 block1_pool (MaxPooling2D) (None, 112, 112, 64) 0 block2_conv1 (Conv2D) (None, 112, 112, 128) 73856 block2_conv2 (Conv2D) (None, 112, 112, 128) 147584 block2_pool (MaxPooling2D) (None, 56, 56, 128) 0 block3_conv1 (Conv2D) (None, 56, 56, 256) 295168 block3_conv2 (Conv2D) (None, 56, 56, 256) 590080 block3_conv3 (Conv2D) (None, 56, 56, 256) 590080 block3_pool (MaxPooling2D) (None, 28, 28, 256) 0 . . . flatten (Flatten) (None, 25088) 0 fc1 (Dense) (None, 4096) 102764544 fc2 (Dense) (None, 4096) 16781312 predictions (Dense) (None, 1000) 4097000 ================================================================= Total params: 138357544 (527.79 MB) Trainable params: 138357544 (527.79 MB) Non-trainable params: 0 (0.00 Byte) _________________________________________________________________
2. tensorflow 모델-transfer learning
- transfer learning은 특별한 건 아니다.
- 잘 학습된 모델을 가져와서 바로 사용하는 것이 아니라, 우리 목적에 맞게 추가 학습을 진행한 다음 사용하는 것이다.
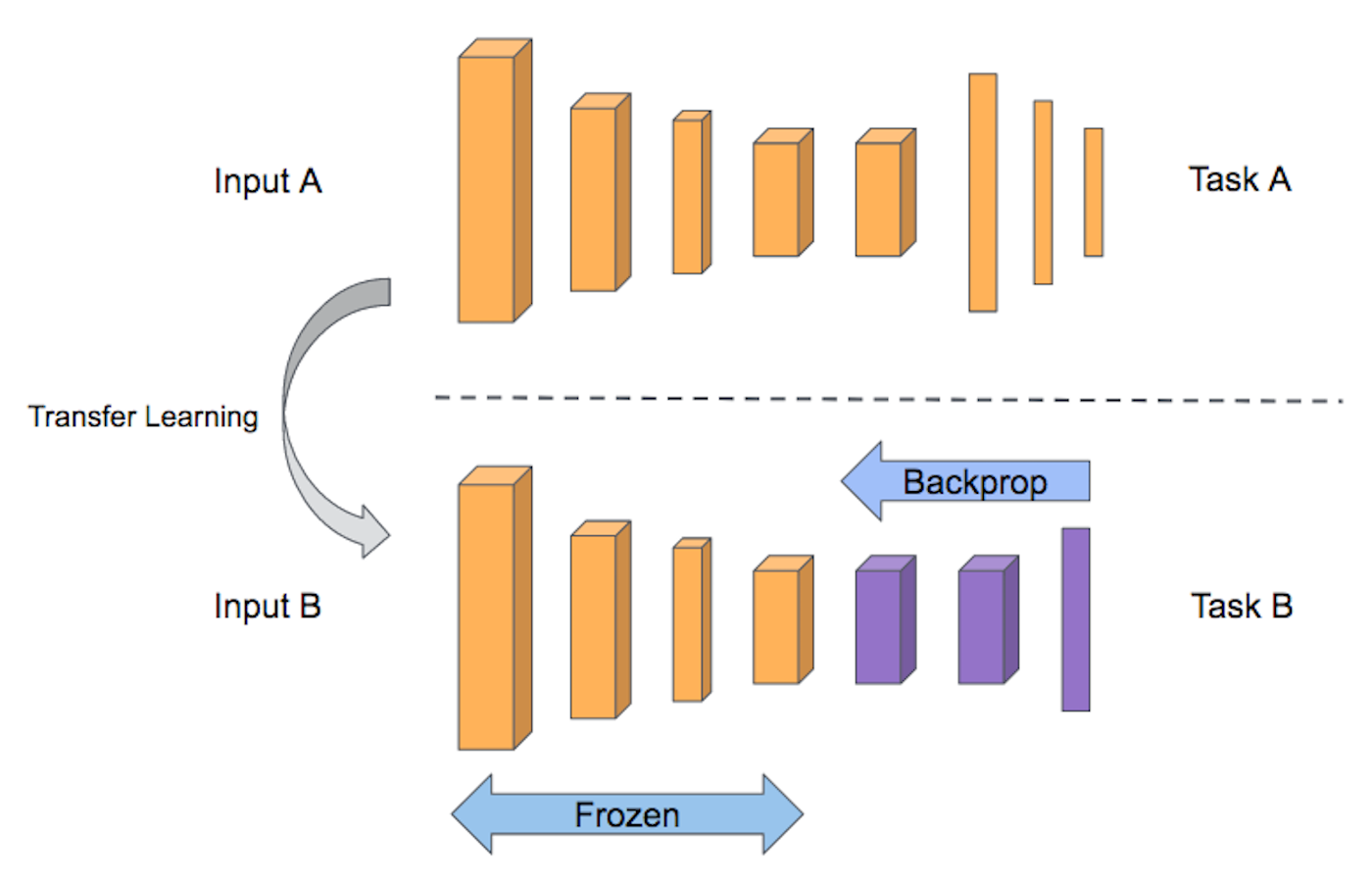
2-1. 모델 불러오기
- 1. 라이브러리 로딩 from tensorflow.keras.applications.InceptionV3 import InceptionV3, preprocess_input, decode_predictions # 모듈 ,input, output 불러온거임 - 2. 모델 불러오기 keras.backend.clear_session() model = InceptionV3(weights='imagenet', # ImageNet 데이터를 기반으로 미리 학습된 가중치 불러오기 include_top=False, # InceptionV3 모델의 아웃풋 레이어는 제외하고 불러오기 input_shape= (299,299,3)) # 입력 데이터의 형태 h = GlobalAveragePooling2D()(model.output) ol = Dense(3, # class 3개 클래스 개수만큼 진행한다. activation = 'softmax')(h) model = keras.models.Model(base_model.inputs, ol) - 3. 생성된 모델 시각화 from tensorflow.keras.utils import plot_model plot_model(model, show_shapes=True, show_layer_names=True) <출력>
- 해당 시각화를 보면, 우리가 직접 modeling을 해서 만들기는 힘들다.
- 그래서, 잘 만들어진 model을 불러와서 목적에 맞게 추가 학습하여 사용하는 것이 더 유용하다.

2-2. 모델 끝 부분 추가 학습
< 이미지 증강은 선택 사항, 방법만 표시> ----------------------------------------------------------------------------------------- - 4. trainIDG = ImageDataGenerator( featurewise_center=False, # set input mean to 0 over the dataset samplewise_center=False, # set each sample mean to 0 featurewise_std_normalization=False, # divide inputs by std of the dataset samplewise_std_normalization=False, # divide each input by its std zca_whitening=False, # apply ZCA whitening rotation_range=180, # randomly rotate images in the range (degrees, 0 to 180) zoom_range = 0.3, # Randomly zoom image width_shift_range=0.3, # randomly shift images horizontally (fraction of total width) height_shift_range=0.3, # randomly shift images vertically (fraction of total height) horizontal_flip=True, # randomly flip images vertical_flip=True) # randomly flip images validIDG = ImageDataGenerator() - 5. trainIDG.fit(train_x) validIDG.fit(valid_x) flow_trainIDG = trainIDG.flow(train_x, train_y) flow_validIDG = validIDG.flow(valid_x, valid_y)
- 모델 끝 부분 100개만 추가 학습 - 1. 모델 끝 부분 분할 len(model.layers) for idx, layer in enumerate(model.layers) : if idx < 213 : layer.trainable = False else : layer.trainable = True - 2. model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer=keras.optimizers.Adam(learning_rate=0.001) ) - 3. es = EarlyStopping(monitor='val_loss', min_delta=0, patience=8, verbose=1, restore_best_weights=True) - 4. model.fit(flow_trainIDG, validation_data=flow_validIDG, epochs=1000, verbose=1, callbacks=[es])
3. Object Detection
1. Ultralytics에서 잘 학습된 YOLO8 모델을 이용한다.
2. Localization
- Localization은 각각의 Object에 Bounding Box가 얼마나 정확하게 그려지는지를 나타낸다. 즉, Bounding Box Regression을 의미한다.
3. Classification
- Classification은 Object가 어떤 클래스에 속하는지 구분하는지를 나타낸다. 즉, Multi-Labeled classification을 의미한다.
3. Bounding Box
- 하나의 Object가 포함된 박스이며, 구성요소는 x, y(좌표) / w, h(크기)로 이뤄지며, 위치 정보를 나타낸다.
- 모델이 object가 있는 위치 정보를 잘 예측하는 것이 중점이며, 회귀 문제를 풀 듯 접근한다.
4. Confidence Score
- object가 bounding box 안에 있는지 확신하는 정도를 의미한다.
.- 정확하게 있다면 1을 가지고 없다면 0을 갖는, 확률의 경향을 띈다.
5. IoU(Intersection over Union)
-
두 박스의 중복 영역 크기를 통해 측정한다. 즉, 겹치는 영역이 넓을수록 좋은 예측값을 갖는다.
-
Object Detection을 하기 위해, 각 object 마다 bounding box를 그려주는 annotation 전처리를 해준다.
-
모델은 object에 대해 새로운 예측 bounding box를 만드는데, 이 2개의 box의 교집합을 측정하는 것이다.
-
confidence Score와 동일하게 확률의 경향을 띈다.
-
IoU Threshold 값이 커지면, 깐깐해진다.
6. NMS(Non-Maximum Suppression)
- 각각의 object에 형성된 bounding box를 제거하는 기능이다.
1) 일정 confidence score 이하의 box를 제거하고, 내림차순으로 정렬한다.
2) 첫 bounding box와의 IoU 값이 설정값 이상인 박스들을 제거한다.
3) box가 1개 될 때 까지 반복한다.
7. Precision, Recall, AP, mAP
-
AP는 precision-Recall Curve 그래프의 면적이다.
-
mAP는 각 클래스 별 AP를 합산하여 평균 낸 것이다.
-
precision과 recall은 IoU Threshold 값에 따라 변화가 일어난다.
- IoU 값이 커지면, 깐깐해지면서 TP의 수가 줄어든다. 그러면, precision은 1에 가까워진다. recall은 값이 낮아진다.
- 즉, precision과 recall은 반비례 관계를 갖는다.
8. Annotation
- 이미지 내에서 각각의 object에 bounding box를 표기하고, class를 부여하는 것이다.
- roboflow 내에서, 작업 수행 가능하다.
9. 핵심 지표들

큐브가 필요하다...!!!