0. 개요
프로그램이 실행되기 위해서는 반드시 메모리 위에 올라와 있어야 한다.
이 때 메모리 내에 어디로 할당을 해 줄 것인가에 대해 생각해 볼 필요가 있다.
complie time binding
코드가 컴파일 될 당시에 location이 결정되는 방식을 말한다. 시작 위치가 변경되면 재컴파일 해야 하는 단점이 있으며, 컴파일 당시에 그 위치에 이미 다른 데이터가 존재할 수 있기 때문에 많이 사용되지 않는 방식이다.
load time binding
컴파일 당시에는 relocatable code로 존재하다가 실행 전에 메모리에 올릴 때에 주소값을 정해주는 방식이다. 상대적인 주소를 사용하기 때문에 프로그램 내부에서 사용하는 주소와, physical 주소와 다르다. 프로그램을 실행한 후에도 주소를 변경할 수 있다.
execution time binding
실행 후, 그 명령어가 실행될 때 바인딩이 진행된다. 이때 그떄그때 주소를 변환시켜 실제 physical address를 알려주는 하드웨어가 MMU이다.
1) physical address
물리적 주소는 이 데이터가 그 메모리에서 실제로 몇 번지에 위치하느냐를 나타낸다. 절대 주소라고도 한다.
2) logical address
논리적 주소는 프로그램 내에서 '상대적으로 얼마나 떨어져 있는가' 등으로 표현하는 메모리이다. 실제로 프로그램이 실행되려면 이 논리 주소를 절대 주소 (물리 주소)로 변환하는 과정을 거쳐야 하고, 이 작업을 수행하는 하드웨어가 MMU(Memory Management Unit)이다.
1. Contiguous Memory Allocation
연속적 메모리 할당은 MMU를 통해 논리적 주소를 물리적 주소로 변환할 때 단순 덧셈을 하여 물리적 주소도 논리적 주소처럼 연속적으로 할당하는 것을 의미한다.
이 때 각 프로세스들은 각자의 메모리 영역을 넘어서서 다른 프로세스의 메모리 영역을 침범하지 않도록 Memory protection이 필요하다.
memory protection에는 두 가지의 레지스터가 사용된다.
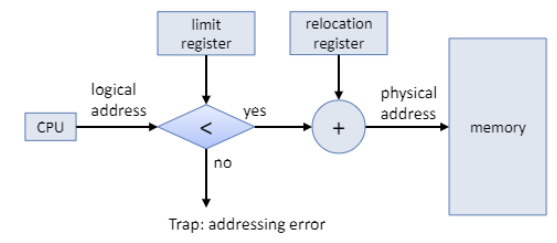
limit register
상한 레지스터에서 제한하고 있는 값보다 큰 가상 주소는 범위를 벗어났다고 판단하고 memory protection fault (trap)를 발생시킨다.
base(relocation) register
프로세스에 starting address를 제공한다. starting address 값에 logical address 값을 더한 것이 physical address가 된다.
프로세스별로 base 와 limit을 이용해서 프로세스마다 구역을 할당해 주는데, 이 공간을 어디다 할당할지가 또 하나의 주된 관심사이다.
메모리 상의 빈 공간을 hole 이라고 하는데, 이 hole들은 다양한 크기로 메모리 곳곳에 뽕뽕 뚫려 있다. 우리는 이 hole들 사이에서 특정 프로세스를 어디다가 넣어줄 것인지를 고민해야 한다. 여기서 세 가지 방법이 제시된다.
First fit
메모리의 처음서부터 충분한 크기를 찾는데, 이 프로세스를 할당해주기에 충분히 큰 hole이 발견되면 처음으로 발견된 그 hole에다가 바로 할당해주는 것을 말한다.
Best fit
프로세스들을 할당해 줄 수 있는 여러 hole 가운데 가장 작은 hole, 즉 프로세스의 크기에 최대한 딱 맞는 hole에 할당한다.
Worst fit
프로세스들을 할당해 줄 수 있는 여러 hole 가운데 가장 큰 hole, 즉 가장 큰 hole에 할당한다.
사실 말이 worst fit이지 마냥 안 좋은 기법은 아니다. hole이 클수록 그 프로세스를 할당하고서라도 다른 프로세스들을 할당하기에 충분한 공간이 남아있을 확률이 크다는 얘기이기 때문이다.
그러나 똑똑하신 분들이 여러 차례 시뮬레이션을 돌려본 결과 실제로 first fit과 best fit보다는 worst fit이 좋지 않다 라는 결론이 도출되었다.
2. Fragmentation
단편화(Fragmentation)은 두 가지로 나뉜다.
External Fragmentation
외부 단편화는, 작은 메모리 공간들이 곳곳에 존재하는데 이 메모리 공간들의 총합은 어떤 프로세스보다 크지만, 실제로는 작게 나뉘어져 있어 할당해줄 수 없는 것을 의미한다.
50% rule
first fit 기법으로 메모리를 할당해 주면, 전체 할당되는 메모리가 N block이라고 했을 때 External Fragmentation이 발생하여 놀고 있는 공간이 0.5N block 정도 생긴다는 규칙이다. 즉 항상 1/3 정도의 메모리 공간에서 손해를 보고 있다는 것을 의미한다.
compaction
메모리 곳곳에 흩어져 있는 hole들을 하나로 모아서 큰 hole 하나를 만들면 프로세스를 할당하기 용이할 것이다. 이렇게 하나로 모으는 작업을 compaction 이라고 하는데, 이 compacting에는 최적 알고리즘이 존재하지 않아 실행하는 데에 부담이 꽤 큰 작업이다.
Internal Fragmentation
내부 단편화는 프로세스가 필요한 양보다 더 크게 할당받아서 내부에서 사용되지 않고 있는 공간이 있다는 것을 의미한다.
Segmentation, paging 부터는 다음 글에서 ...
